안녕하세요. 민 입니다. 😊 오늘의 두 번째 포스팅입니다. 크롤링에 대해서 간략하게 공부한 이후에 실습만큼 좋은 게 없죠 ? 오늘은 유명한 스포츠 사이트에서 그 동안의 있던 경기내역에 대해서 추출해보려고 합니다. 따라오시죠 !!
목차
1.크롤링으로 정보가져오기
2.csv파일(엑셀형식)에 정보넣어주기
3.csv파일 정보 추출 후 matplotlib적용해보기
1.크롤링으로 정보가져오기
크롤링으로 정보를 가져오기 위해서는 기본적인 설정이 필요합니다. selenium , soup , webdriver 등등 필요한 게 많은 데 사용하시면서 알아가시죠 !
일단 저희가 가져올 사이트를 하기 위해 국내에서 유행하는 스포츠사이트에 대한 정보를 가져오겠습니다.
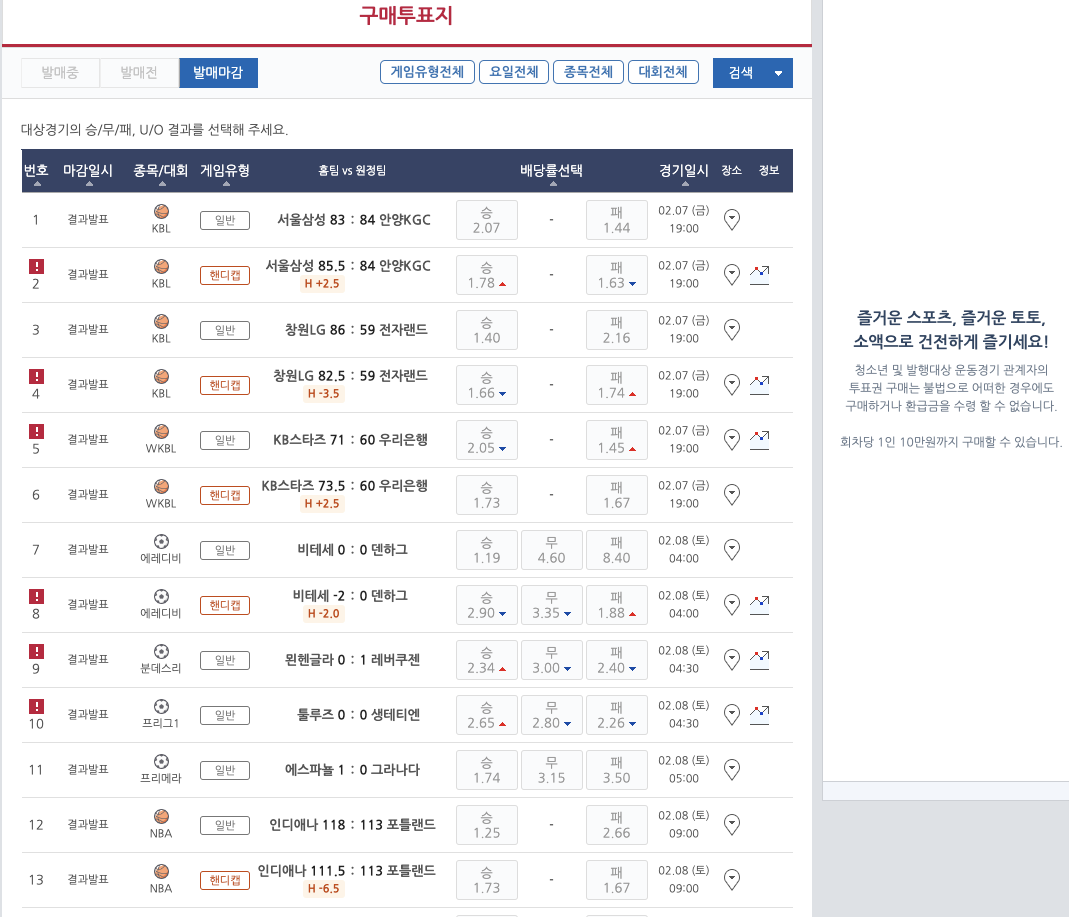
-> 여기를 누르시면 접속이 가능합니다 .
https://www.betman.co.kr/main/mainPage/gamebuy/gameSlipIFR.do?gmId=G101&gmTs=140012&gameDivCd=C&isIFR=Y
링크를 자세히 보시면 중간에 140012라는 부분이 보일텐데 14년도라는 뜻이고
15,16,17 등으로 변경하시면 해당하는 년도에 경기내역를 확인가능합니다 .
자 이제 실습하러 들어가보시죠 !
1. 개발자 도구를 켜주기
2. 가져오고 싶은 부분클릭
3. 해당하는 부분의 코드를 어떻게 가져올 지 생각하기
이런 순서대로 크롤링을 진행할 수 있는데요 .
코드를 확인하시고 집중해야할 출력하는 부분에 집중해봅시다 !!
import time
from selenium import webdriver # selenium 패키지에서 webdriver 모듈을 가져온다 -> 웹 브라우저 제
from selenium.webdriver.common.by import By # 웹 요소식별
from webdriver_manager.chrome import ChromeDriverManager # 웹 드라이버를 자동으로 다운로드
import pandas as pd # pandas
import json
options = webdriver.ChromeOptions() # options
options.add_experimental_option(
"excludeSwitches", ["enable-logging"]) # logging 생성
driver = webdriver.Chrome(options=options)
text_list = []
pathcsv = './betmandata/betman.csv' #
result_dict = {}
result_list = []
pathjson = './betmandata/betman2014.json'
try:
driver.get( 'https://www.betman.co.kr/main/mainPage/gamebuy/gameSlipIFR.do?gmId=G101&gmTs=140001&gameDivCd=C&isIFR=Y')
# 전체리스트
gameMainArea = driver.find_element(
by=By.CLASS_NAME, value='gameMainArea')
# 내부 class
tabList = driver.find_element(By.XPATH, '//*[@id="tabMenuDiv"]')
tblArea_noLine = driver.find_element(By.XPATH, '//*[@id="div_gmBuySlip"]')
tdb_gmButSlipList = driver.find_elements(
By.XPATH, '//*[@id="tbd_gmBuySlipList"]')
list = driver.find_elements(By.XPATH, '//*[@id="tbd_gmBuySlipList"]/tr[3]')
print(type(list))
time.sleep(5)
index = driver.find_elements(By.XPATH, '//*[@id="tbd_gmBuySlipList"]')
print(type(index))
result = []
# tr 태그를 가져옵니다.
tr_elements = driver.find_elements(
By.XPATH, '//*[@id="tbd_gmBuySlipList"]/tr')
# tr 태그의 개수를 세어 출력합니다.
print(f'Total number of tr elements: {len(tr_elements)}')
for i in range(len(tr_elements)):
# 각 행에 대한 XPath 생성
row_xpath = f'//*[@id="tbd_gmBuySlipList"]/tr[{i + 1}]'
# //*[@id="tbd_gmBuySlipList"]/tr[{i+1}]
# //*[@id="tbd_gmBuySlipList"]/tr[1]/td[3]/span[2]
db_fs11 = driver.find_element(
By.XPATH, row_xpath + f'/td[{3}]/span[{2}]').text
# //*[@id="tbd_gmBuySlipList"]/tr[1]/td[3]/span[2]
badge_gray = driver.find_element(
By.XPATH, row_xpath + f'/td[{4}]/span').text
# //*[@id="tbd_gmBuySlipList"]/tr[1]/td[4]/span
scoreDiv_fwb = driver.find_element(
By.XPATH, row_xpath + f'/td[{5}]/div').text
# //*[@id="tbd_gmBuySlipList"]/tr[1]/td[5]/div
formBox = driver.find_element(
By.XPATH, row_xpath + f'/td[{6}]/div').text
# //*[@id="tbd_gmBuySlipList"]/tr[1]/td[6]/div
fs11 = driver.find_element(
By.XPATH, row_xpath + f'/td[{7}]').text
result_dict = {}
result_dict['db_fs11'] = db_fs11
result_dict['badge_gray'] = badge_gray
result_dict['scoreDiv_fwb'] = scoreDiv_fwb
result_dict['formBox'] = formBox
result_dict['fs11'] = fs11
result_list.append(result_dict)
# 딕셔너리를 리스트에 추가
result_list.append(result_dict)
result.append([db_fs11, badge_gray, scoreDiv_fwb, formBox, fs11])
with open(pathjson, 'w', encoding='utf-8') as w:
json.dump(result_list, w, indent=4, ensure_ascii=False)
n_table = pd.DataFrame(result, columns=(
'2014' 'db_fs11', 'badge_gray', 'scoreDiv_fwb', 'formBox', 'fs11'))
n_table_to_csv = n_table.to_csv(
pathcsv, index=True, encoding='utf-8', mode='w')
# //*[@id="tbd_gmBuySlipList"]/tr[1]/td[7]
print('리그: {} 경기: {} 경기결과 : {} 승,무,패: {} 경기일시:{} '.format(
db_fs11, badge_gray, scoreDiv_fwb, formBox, fs11))
except Exception as e:
print(e)
코드가 많이길죠 ? 코드를 다 보시려고 하지 않으셔도 됩니다.
여기서 이제 실제적으로 가져오는 부분에 대해서 알아볼 것 입니다 .
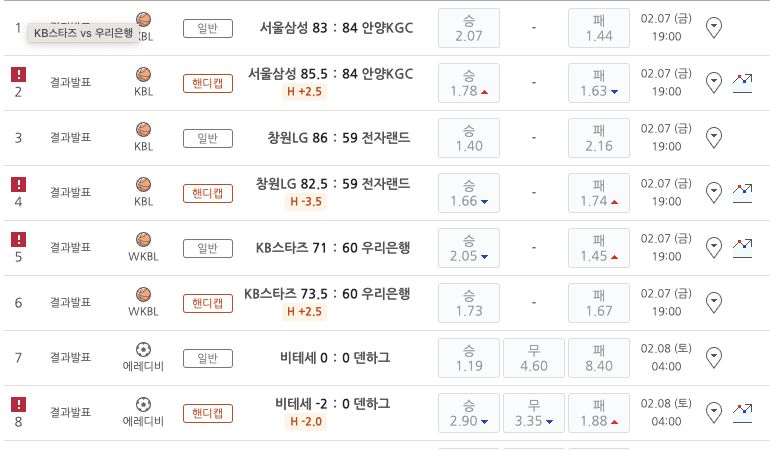
저는 이 부분에 존재하는 팀 , 경기결과 , 승무패 , 경기날짜 , 경기종류 내용이 모두 궁금하였고 모두 하나씩 가져왔습니다.
✓ 개발자 도구를 이용하여 크롤링하고 싶은 부분 검색
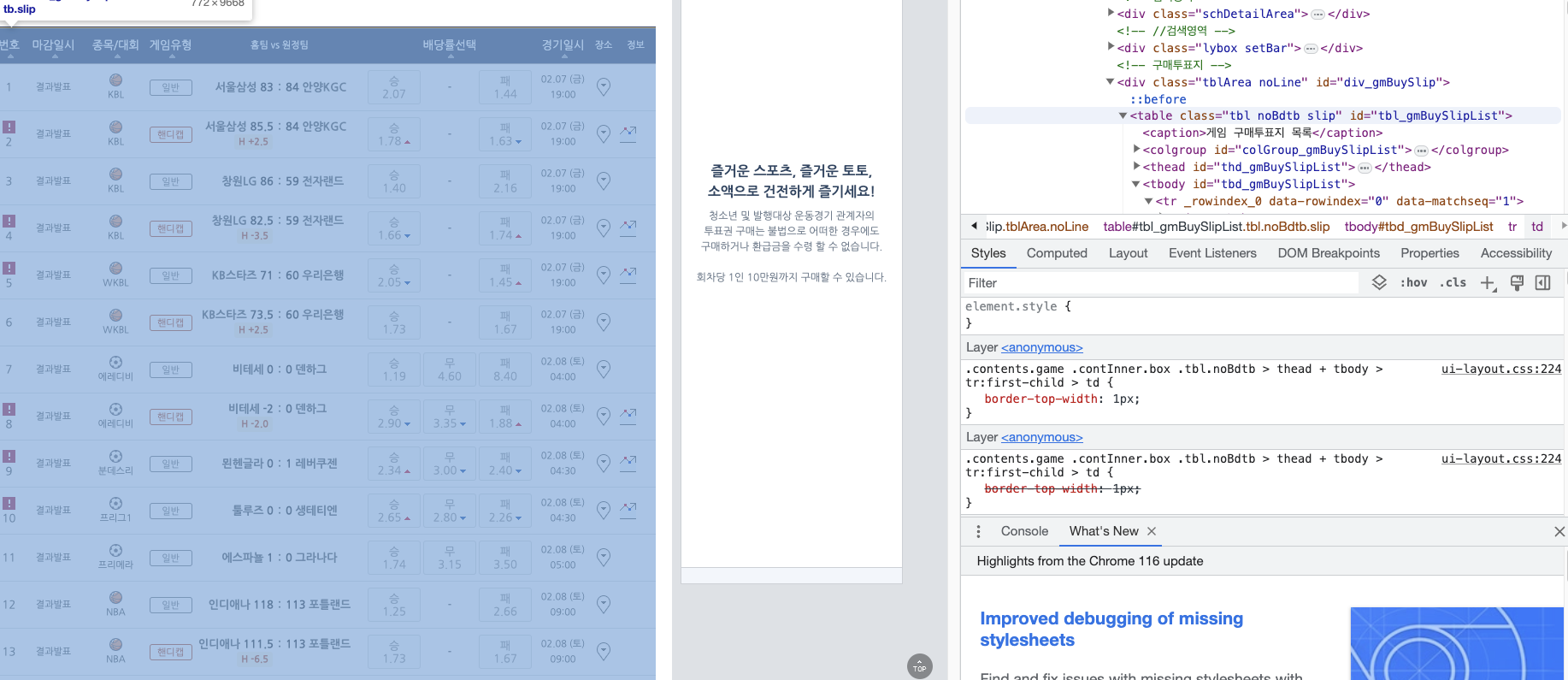
이런식으로 개발자도구를 켜주신다음에 필요한 부분에 대해서 클릭해주셔서 코드를 확인해주시고요. copy->xpath 순으로 복사해주시면 됩니다 .
그럼 XPATH의 값이 list 형식으로 나오는 부분이기 때문에 반복문을 이용해서 값을 받아줄 수 있겠죠 ??
✓ 찾고싶은 요소를 크롤링 한 이후에 리스트에 저장
반복문을 사용해서 요소에 하나하나 값을 넣어준 이후에 csv파일로 저장하는 구문을 넣어주시면 됩니다 .
✓ (1) CSV파일저장
자 이제 csv파일을 확인하러 가볼까요 ??
✓ (2) CSV파일
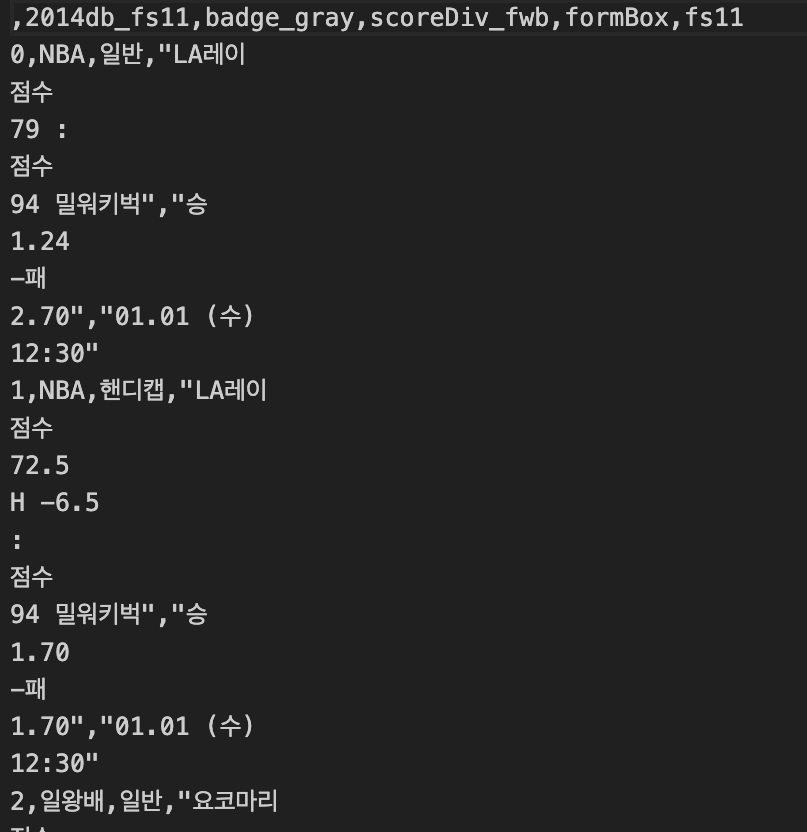
✓ (3) CSV파일을 읽고 10년간의 경기 확인 (matplotlib)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import csv
from matplotlib import rc
from sklearn.linear_model import LinearRegression
rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False # 추가해줍니다.
# 빈 배열 가져오기
data = []
# 연도별 경기 데이터
years = range(2014, 2024) # 2014년부터 2023년까지
# 경기수 MatchNum
MatchNum = []
# csv 파일 읽어와서 경기 구하기
for i in range(10):
with open(f'./betmandata/betman{2014+i}.csv', newline='', encoding='utf-8') as csvfile:
data = []
reader = csv.reader(csvfile)
for row in reader:
data.append(row)
MatchNum.append(len(data))
# 경기
print(MatchNum)
# 그래프 생성
plt.figure(figsize=(10, 6)) # 그래프 크기 설정
plt.plot(years, MatchNum, marker='o', linestyle='-')
plt.title('연도별 경기 수')
plt.xlabel('연도')
plt.ylabel('경기 수')
plt.grid(True)
# 그래프 표시
# 선형 회귀 모델을 훈련하기 위해 데이터를 준비합니다.
X = np.array(years).reshape(-1, 1) # 연도를 특성으로 사용
y = np.array(MatchNum) # 경기 수를 타겟으로 사용
# 선형 회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X, y)
# 예상 그래프 생성
predicted_y = model.predict(X)
# 예상 그래프 추가
plt.plot(years, predicted_y, marker='x', linestyle='--', label='예상 경기 수')
# 범례 표시
plt.legend()
# 그래프 표시
plt.show()
# def WinAndLose(data):
# for i in range(len(data)):
# if data[i]
#
💁 ♂️ 결과확인
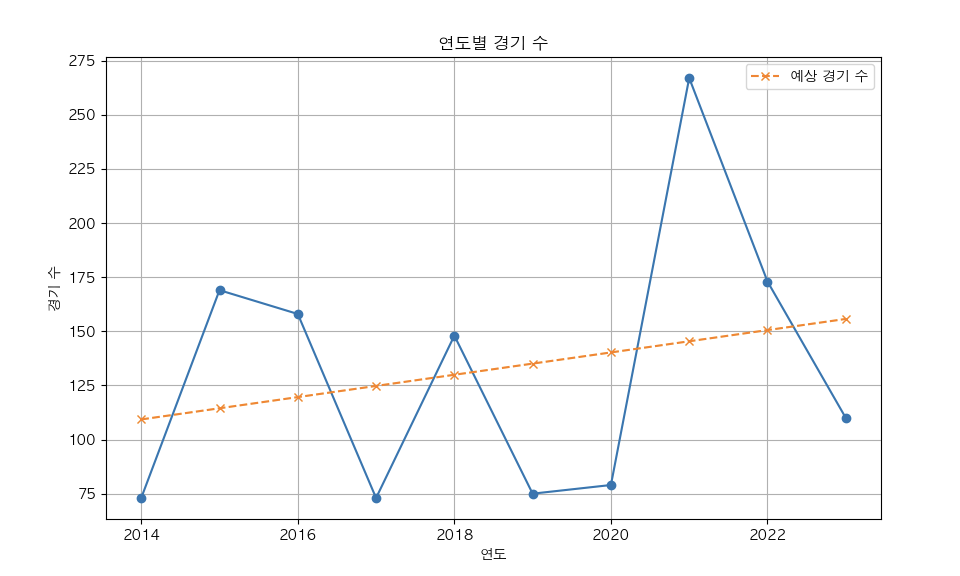
오늘은 크롤링을 이용하여 스포츠 사이트의 경기결과를 저장하고 따로 경기에 관한정보 만 추출하여 그래프를 matplotlib을 이용하여 제작해보았습니다 .
여러분도 간단한 것이라도 좋으니 하나씩 크롤링해서 예측하는 것을 반복하시면 좋겠습니다 .
🏃♂️🏃♂️🏃♂️
코드가 간략하기 때문에 코드가 궁금하시다면 !!
코드확인하러가기
