Data preprocessing
Data preprocessing 역할
1) 머신러닝의 input 형태로 데이터 변환(feature engineering)
-> 모델이 학습하기 위해서는 그에 알맞는 numerical한 data로 변환해야함.
2) NAN/NULL(결측값) 및 outlier(이상치)를 처리하여 데이터 정제
-> 모델이 학습하기 위한 data로 변환/ 위에 있는 녀석들은 학습 x
3) train test splite
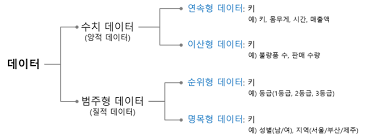
Categorical Variable 처리방식
명목형 자료(norminal data)
- 수치 맵핑 방식
- Ordinal encoding
- Label encoding
- Binary encoding.....

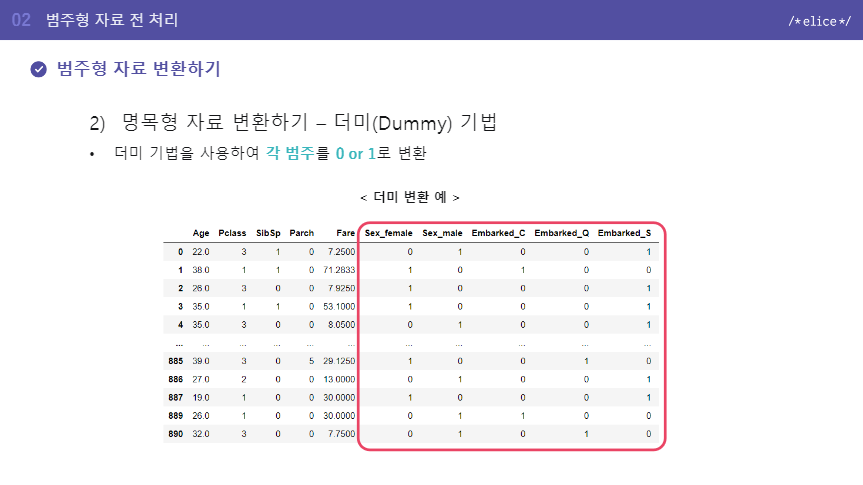
- dummy 기법
- 더미 기법을 사용하여 각 범주를 0 or 1로 변환 / 새로운 feature들을 만듬
- Onehot encoding
- Dummy encoding(Dummy encoding removes a duplicate category present in the one-hot encoding.)
잘 설명된 원핫과 더미 차이 링크
순서형 자료(ordinal data)
• 수치에 맵핑하여 변환하지만,수치 간 크기 차이는 커스텀 가능
• 크기 차이가 머신러닝 결과에 영향을 끼칠 수 있음
- 마찬가지로 ordinal encoding인데 그 사이 간격을 조절 할 수 있음
Numerical Variable 처리 방식
바로 input값으로 사용할 수 있지만 모델의 성능을 높이기 위해서 변환 필요
1) Scaling
-
변수 값의 범위 및 크기를 변환하는 방식
-
변수(feature) 간의 범위가 나면 사용함
정규화(Normalization)
- 겁나 큰 값들이 들어있는 feature가 다른 작은 값들만 있는 feature에 영향을 미칠수 있어서 겁나 큰값 feature들을 0~1사이의 값으로 scaling하는 하나의 scaling기법

표준화(Standardization)
- 정규화와 같이 하나의 스케일링 방식임. 정규분포 곡선에 점들이 찍힐것임.
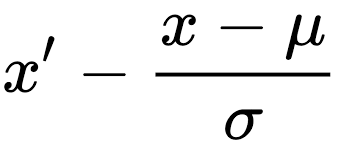
2) 범주화
- 변수의 값보다 범주가 중요한 경우 사용
ex) 시험점수에서 평균이 54.63이라면 (평균이상 -> 1/ 평균 이하 -> 0)
Missing Value 처리
처리방식
1) NAN값이 존재하는 샘플 삭제
2) 결측값이 많이 존재하는 feature 삭제
3) 다른 값으로 대체(mean/median/simpleImputer/머신러닝 이용)
Outlier처리
- 이상치가 있으면 모델성능
- 일반적으로 data preprocessing과정에서 제거
- 어떤값이 outlier인지 판단하는 기준 중요!
이상치 판단 기준방법
1) 통계 지표(카이제곱 검정,IQR 지표등)을 사용
2) 데이터 분포 보고 직접 판단
3) 머신러닝 기법 사용, 이상치 분류
train test split
- 모델 평가를 위한 학습에 사용하지 않은 test data 필요
- Label data: 예측 대상 데이터
- Feature data: label 예측 위한 입력값
cf)train test split parameters
1) random_state: 세트를 섞을 때 해당 int 값을 보고 섞으며, 하이퍼 파라미터를 튜닝시 이 값을 고정해두고 튜닝해야 매번 데이터셋이 변경되는 것을 방지할 수 있습니다.
2) stratify: default=None 입니다. classification을 다룰 때 매우 중요한 옵션값입니다. stratify 값을 target으로 지정해주면 각각의 class 비율(ratio)을 train / validation에 유지해 줍니다. (한 쪽에 쏠려서 분배되는 것을 방지합니다) 만약 이 옵션을 지정해 주지 않고 classification 문제를 다룬다면, 성능의 차이가 많이 날 수 있습니다.
3) test_size: 테스트 셋 구성의 비율을 나타냅니다. train_size의 옵션과 반대 관계에 있는 옵션 값이며, 주로 test_size를 지정해 줍니다. 0.2는 전체 데이터 셋의 20%를 test (validation) 셋으로 지정하겠다는 의미입니다. default 값은 0.25 입니다.
- [명목형 자료 예시 출처]:
- 명목형 자료 수치맵핑/ dummy 기법 사진 출처: 2022 군 장병 sw/ai 역량 강화 프로그램
https://military22.elice.io/courses/26526/lectures/204992/materials/12- 정규화 사진 출처:https://www.wallstreetmojo.com/normalization-formula/
- train test split parameter설명: https://teddylee777.github.io/scikit-learn/train-test-split
