
🇰🇷 KoHalluLens로 벤치마크 직접 돌려보기!
🤷 Motivation
- 통일된 계층과 같은 할루시네이션을 분류할 프레임워크 부족
- Hallucination에 대한 용어와 범위의 모호함
- “사실과 다른 말하기”(Factuality issue)
- “모르는데 아는 척하기”(Hallucination) - Factuality와 real-world의 불일치
- ex) 22년산 한동건(수염이 존재하는 카더가든처럼 생긴)을 train한 LLM 모델
- 한동건의 얼굴에 대해서 묘사해달라고 하면 수염달린 카더가든 한동건이라고 함
- 내부 지식에 한에서는 llm이 충실했지만 2025년 real-world 한동건은 수염이 없는 나폴리맛피아 닮은 한동건임
- ex) 22년산 한동건(수염이 존재하는 카더가든처럼 생긴)을 train한 LLM 모델
- 기존 hallucination eval dataset들은 Data saturation or Leakage문제 발생
- data saturation: 모델들이 성능들이 모두 좋아져서 성능 향상이 미미해지는 현상
- data saturation: 모델들이 성능들이 모두 좋아져서 성능 향상이 미미해지는 현상
🤷 Definition
-
Hallucination
- 훈련한대로 말하지 않거나 prompt(input context)대로 답변하지 않는것
-
Claim
- longform answer에서 검증가능한 작은 정보단위 or 사실적 진술
- 유형
- True: 생성된 claim의 개수
- Flase: 생성되지 않는 claim의 개수
- Positive: supported
- Negative: unsupported, refuted, unverifiable
🧮 실험 Setting
- 엄선된 Wiki활용
- goodWiki: wikipedia Editors가 따봉한 Wiki로 필터링 - (2023/9/4)까지의 위키를 가져옴
- WikiRank 2024: Harmonic centrality score 기준으로 10개의 구간을 나눠서 각 문서의 난이도 분류
- h-score란?
- 그래프 이론에서 노드의 중요성과 영향력을 측정하는 지표임.
- 높을수록 더 접근성이 좋고, 언급이 많이 되고 많이 알려져있다는 것
- 문서 중요도와 대중성의 프록시로 활용
- 각 extrinsic hallucination에는 위키 문서 기준으로 난이도 분류함
- h-score란?
- 어려움의 기준
- h-score
- longtail knowledge
- NonEntity를 만드는법
- Mixed Entities - 각도메인당 2000개씩 총 8000개 sample
- 동물, 식물, 박테리아 분류, 의약품과 같은 이름들을 무작위로 섞어서 새로운 용어를 만듦
- 실제 의학, 분류학 데이터베이스(ITIS)에서 있는지 Validation → 검색 검증 x
- Generated Entities - 1950개의 Sample
- LLM이 다양한 도메인(비즈니스, 이벤트, 제품브랜드)에서 허구적인 Entity 이름 생성
- Round-Robin
- 단일 llm이 자신이 만든 가상의 엔티티에 정보를 제공하려는 bias 존재가능
- 두가지 모델로 허구의 Enitity를 생성, 세번째모델이 이름들을 조합하여 query를 만듦.
- Llama-3.1-405B-Instruct, GPT-4o, Mistral-Nemo-Instruct-2407
- Brave Search API로 검색엔진으로 존재여부 검증
- Mixed Entities - 각도메인당 2000개씩 총 8000개 sample
🤗 Taxonomy

👾 Extrinsic Hallucination
- 정의: 생성된 내용이 training data와 일치 x
- 평가 방식:
- 한번 evaluation run할때마다 데이터가 생성되고, 평가까지 완료함.
- wiki 문서를 보고 dynamic하게 query-gt pair를 생성함
- LLM-as-Judge를 활용해서 각 Metric에 따라 Performance 측정
- 한번 evaluation run할때마다 데이터가 생성되고, 평가까지 완료함.
1. PreciseWikiQA
- 단답형 query-gt 500개
[Metric]
- False refusal rate
- Hallucination rate
- Correct answer rate
- [Eval 결과]
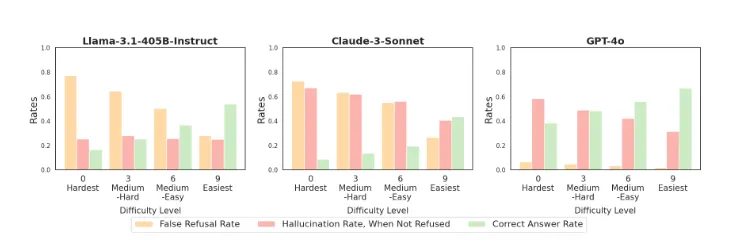
- 라마 3.1 405b-instruct 는 난이도 수준에 걸쳐 일관된 Hallucination 비율을 보여줌
- Gpt-4o와 claud-3.5-sonnet는 어려울수록 hallucination비율이 높아짐
2. LongWiki
- Longform
- 서술형 query-gt - (250개 sampled + 50개 레벨 고려 샘플링)
- [Metric]
- False refusal rate
- Precision
- 생성된 답변에서 나온 전체 claim 중 supported claim의 평균 비율
- Recall@K
- Detail
- Precision에서 짧게 말한것에 대해서 점수를 많이 받을수도 있기에 조정
- FN은 어떻게 아나?
- 몰라서 K를 32개로 적당히 두고 32개가 모든
- F1@K
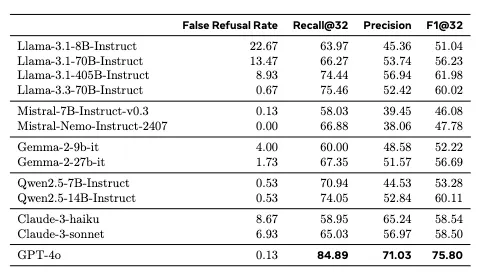
[Eval 결과]
3. NonExistentRefusal
- training하지 않은 상상의 Entitiy를 섞어서 질문하면 거부하는가?
- 관련성 없지만 넣었을때 그럴듯해보이는 entity를 프롬프트에 넣음
- 존재하지 않는 엔티티 1950개 생성후 query를 날림.
- 생성법
- Entity 생성후 Benchmark → 모델은 모릅니다유를 시전해야함
- Mixed Entity생성
- 동물, 의약품, 식물, 박테리아 분류 이름 섞기
- 검증 - db검색
- GeneratedEntities
- Round Robin 방식 활용
- 2개의 모델이 개체를 생성하고, 하나의 모델이 조합함
- 검증 - 웹검색
- Round Robin 방식 활용
- Mixed Entity생성
- Entity 생성후 Benchmark → 모델은 모릅니다유를 시전해야함
[Metric]
- False Acceptance Rate
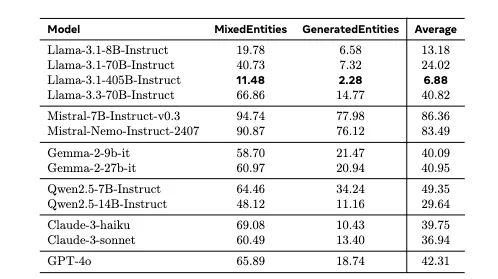
[Eval 결과]
🪐 Intrinsic Hallucination
- 정의: 생성된 내용이 input context와 일치하지 않는 생성
기존 벤치마크 활용 (Static)
- 조건:
- 기존의 잘알려지지 않으면서(Data leakage 문제 방지)
- data saturation의 문제가 없는 데이터셋 사용
- 선정된 벤치마크
- HHEM(Hughes Hallucination Evaluation Model) → 매년 업데이트
- text summarization → 7B미만 모델은 유용
- 실험 디테일
- testset
- factual consistency 데이터셋으로 Train한 hallucination detection 모델을 사용
- 각 LLM이 생성한 요약이 원문 내용과 사실적으로 일치하는지 평가
- 모델별 factual consistency 비율 = 환각이 없는 비율
- 환각률 = 100 - factual consistency 비율
- 응답 거부율은 별도로 ‘Answer Rate’로 기록.
- 실험 세팅
- temperature = 0
- 프롬프트세팅
- 깃허브 나와있는대로 ㄱㄱ
- 사용모델: HHEM-2.1-Open
- context length 제한은 없다고 Hugging에 나오긴했는데 한번 써보고 이상하면 github 설명대로 1000개 짧은 Corpus로 샘플링
- ANAH 2.0 - with reference set-up
- ANAH dataset
- ANAH v2 model
- FaithEval
- FaithEval Benchmark dataset
- HHEM(Hughes Hallucination Evaluation Model) → 매년 업데이트
- 이유
- benchmark set을 extrinsic처럼 Dynamic하게 하면 좋지만 llm as judge 자체에서도 할루시네이션이 생길 수 있음.
1. HHEM
- 매년 업데이트 되는 Text summarization 벤치마크
- 7B 미만의 모델을 평가하는데에는 유용하다고 판단해서 넣음
2. ANAH2.0
- input context로 사실적으로 정확한 정보를 주었을때 생성된 콘텐츠와 입력 context 간의 일관성 평가
- llm as judge
3. FaithEval
- 입력 Context에 노이즈를 넣거나 모순된 지식을 섞어도 잘 대답하는지 평가

존나 재밌는것을 맨듭니다.