ML
1.multilabel-classification finetuning

실험 설계evaluation metric macro
2.Mean pooling - 임베딩 차원 맞춰보자이

문제 Lyrics와 quantized f0된 melody를 FFT encoding을 하면 [batch size, hidden channel, time(seq_len)-> 시퀀스 Length]가 나온다. sequence length가 다를 수도 있지 않누?? 해결 m
3.왜 nn.Embedding을 하면 transpose를 하는걸까?

lyrics encoder과 melodyU encoder를 Summation한 뒤의 shape는 (1, 192, 1) - (b, h, time(seq_len))이다. 요녀석들은 enhanced condition encoder에서 다시 FFT 연산을 하는데 동일하게 nn
4.nn.Embedding이란
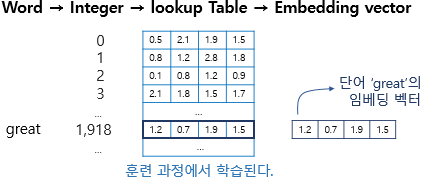
동기 내가 아는 embedding의 개념은 자연어 혹은 entity들을 사용자가 원하는 의미적 유사도대로 임베딩 space에 수치화 해서 배치하는것으로 알고 있다. 근데 자연어인 lyrics를 바로 nn.Embedding에 통과 시키는것이 아닌 Lyrics가 이미 v
5.텐서 조작 팁 - unsqueeze는 뭐냐?

unsqueeze는 PyTorch에서 텐서에 새로운 차원(길이 1인 축)을 추가하는 함수입니다.예를 들어, quantized_f0의 shape이 (1703,)라면, quantized_f0.unsq
6.임베딩과 tokenize개념

sequence(text, frame으로 나뉘어진 f0음성등)을 token으로 나눠서 수치화한것, 인덱싱으로 매핑한것token들에 대해서 의미적인 연관성을 기반으로 배치한것
7.batch vs batch size

데이터 Sample 묶음batch 1 묶음에 들어가는 sample의 개수
8.HalluLens 논문리뷰

기존의 데이터 리키지가 걱정되는 할루시네이션 벤치마크는 저리가라!