
제주도 교통량 예측대회를 위해서 싸지방에서 고군분투중이다. 가능한 내가 배웠던 다양한 기법들을 모두 적용해고자 했다. 싸지방 컴퓨터는 한정된 시간내에 모델을 돌릴 수 있으므로 stacking보다는 시간소모가 좀더 적은 blending을 시도해보고자 했다.
Blending이란?
ensemble 기법중 하나로 여러가지 leak model들을 trian data로 학습 시키고, validation set과 test set들을 predict한다. predict한 여러 validation prediction set들과 test prediction set들을 각각 concat한후 강력한 meta model에 concat했던 validation prediction set과 y_val을 fit한다. 그리고 meta 모델의 predict는 아까 concat한 test prediction set들을 predict하는 기법이다.
어떻게 해?
Structure
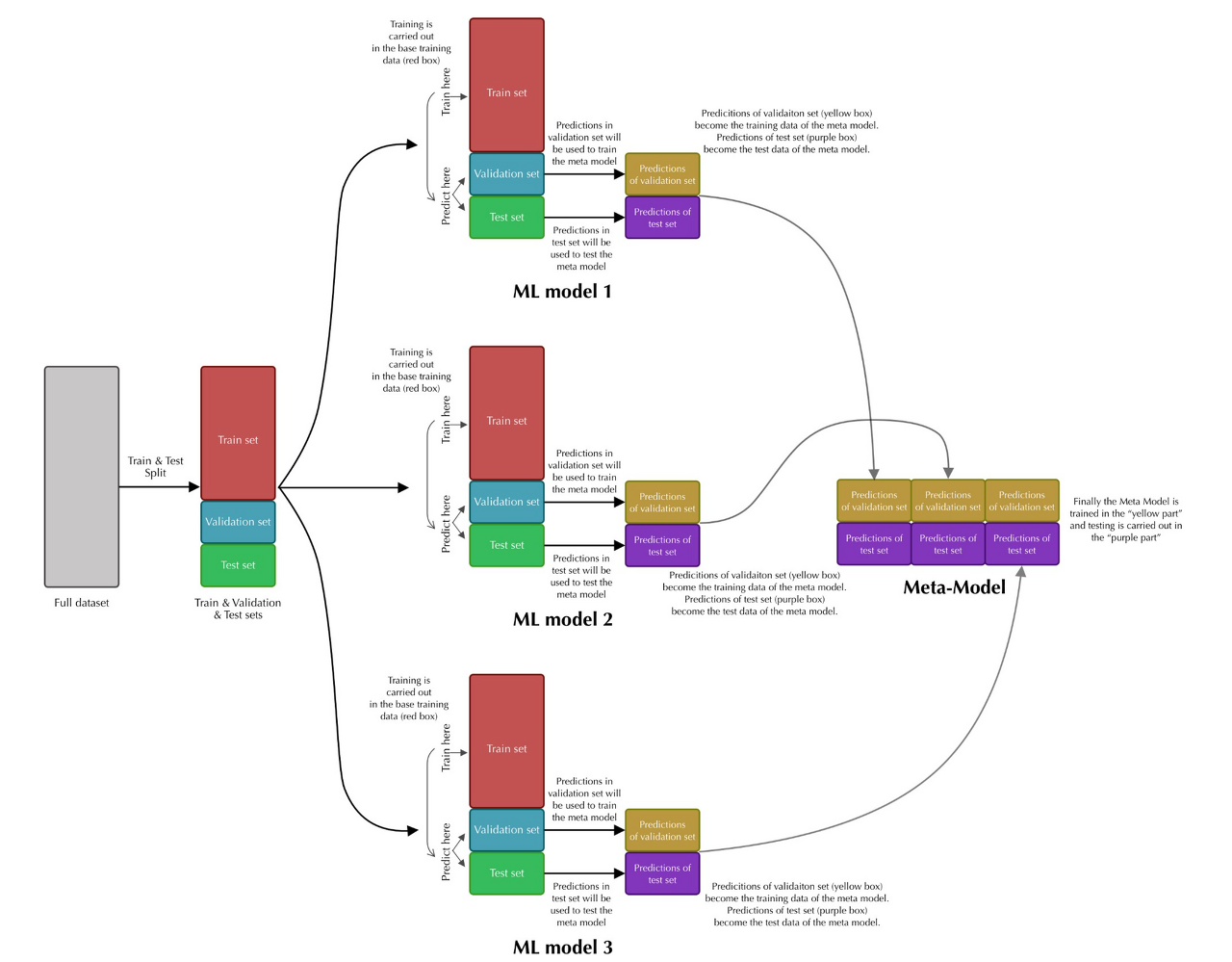
순서
- train test split을 통해 train set과 validation set 나누기
- 여러가지 leak model들을 trian data로 학습 시키기
- 학습시킨 모델에 validation set과 test set들을 predict한다
- predict한 여러 validation prediction set들과 test prediction set들을 각각 concat한다.
cf)
1 - concat할때 val 요소들 (기존 split했던 X_val, predict했던 부산물들)
2 - concat할때 test 요소들 (기존 split했던 test, predict했던 부산물들)
5. 강력한 meta model에 concat했던 validation set과 y_val을 fit한다.
6. meta 모델의 predict는 아까 concat한 test prediction set들을 predict한다.
나이스한 설명들
https://slowsteadystat.tistory.com/21
https://3months.tistory.com/486
-> 두번째 링크의 예제코드에서 score의 y_test는 train test split을 할때 애초에 score을 내기 위해서 train set을 validation set과 test set으로 나누어 test를 x_test와 y_test를 따로 나눈것 같다.
출처:
1. blending structure사진: https://slowsteadystat.tistory.com/21
