Chapter 6: Parallel Processors from Client to Cloud(클라이언트에서 클라우드까지의 병렬 프로세서)
GPU?
- 2D/3D 그래픽, 비디오, 시각 컴퓨팅 및 이스플레이에 최적화된 프로세서
- 시각 컴퓨팅을 위해 최적화된 고도로 병렬화(parallel)되고, 고도로 멀티스레드(multithreaded)된 멀티프로세서
- 계산된 객체(computed objects)와의 실시간 시각적 상호작용(real-time visual interaction)을 그래픽 이미지 및 비디오를 통해 제공함
- GPU는 programmable graphics 프로세서이자 확장가능한 병렬 컴퓨팅 플랫폼(scalable computing platform)으로 역할을 함
GPU의 Evolution
🚨몇년에 뭐 있었는지 암기
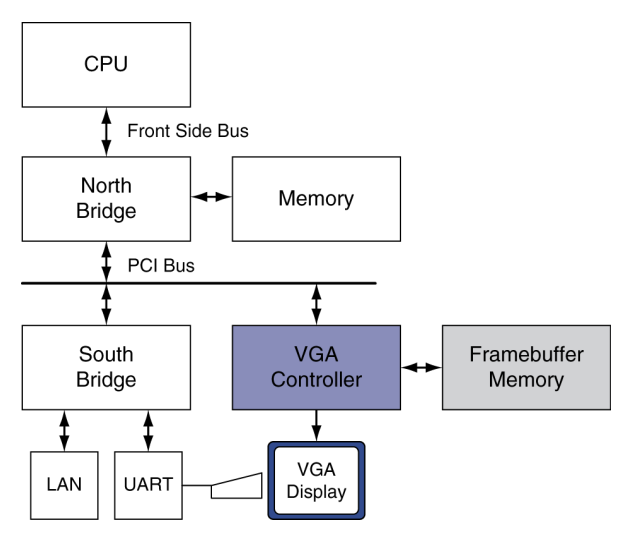
- 1980년대 - GPU 없음. PC는 VGA(video graphics array) 컨트롤러 사용
- 1990년대 - VGA 컨트롤러에 더 많은 기능 추가
- 1997년 - 3D 가속 기능(3D acceleration functions) 추가:
- 삼각형 설정(triangle setup) 및 레스터화(rasterization)를 위한 하드웨어
- texture mapping 및 shading
- 2000년 - 단일 칩 그래픽 프로세서(single chip graphics processor)(‘GPU’라는 용어의 시작)
- 2005년 - 대규모 병렬 프로그래머블 프로세서(massively parallel programmable processors)
- 2007년 - CUDA(Compute Unified Device Architecture)
CPU와 GPU의 차이
- 지연 비내성(Latency Intolerance) vs 지연 내성(Latency Tolerance)
- 작업 병렬성(Task Parallelism) vs 데이터 병렬성(Data Parallelism)
- 다중 스레드 코어(Multi-threaded Cores) vs SIMT(단일 명령어 다중 스레드 코어 = Single Instruction Multiple Thread Cores)
- 수십 개(10s)의 스레드 vs 수만 개(10,000s)의 스레드
Latency and Throughput(지연과 처리량)
🚨CPU와 GPU 차이 이야기할 때 제일 중요한 것
- Latency == 어떤 것이 시작된 순간과 그 효과 중 하나가 시작되거나 감지될 수 있는 순간 사이의 시간 지연(time delay)
- ex. 텍스처 읽기 요청과 텍스처 데이터 반환되는 사이의 시간 지연
- Throughput == 주어진 시간동안 수행된 작업의 양
- ex. 초당 처리된 triangle의 수
- CPU: low latency, low throughput 프로세서
- GPU: high latency, high throughput 프로세서
CPU와 GPU의 병렬성(parallelism)
- CPU: 작업 병렬성(task parallelism)
- 여러 작업이 여러 스레드에 매핑됨
- 작업은 다른 명령어를 실행함
- 수십 개(10s)의 상대적으로 무거운 스레드가 수십 개의 코어에서 실행됨
- 각 스레드는 명시적으로 관리되고 스케줄됨
- 각 스레드는 개별적으로 프로그래밍되어야함
- GPU: 데이터 병렬성(data parallelism)
- SIMD model(Single Instruction Multiple Data)
- 동일한 명령어를 다른 데이터에 적용
- 수만 개(10,000s)의 경량 스레드(lightweight threads)가 수백개의 코어에서 실행됨
- 스레드는 하드웨어에 의해 관리되고 스케줄됨
- 프로그래밍은 스레드 배치(batch)로 수행됨(ex. 한 픽셀 shader를 픽셀 그룹에 적용하거나 draw call을 수행)
GPU System Architectures
🚨이 아키텍처의 이름을 '영어로' 암기하기
🌟Heterogeneous CPU-GPU System Architecture
- 역사적인 PC(1990년대)
- VGA 컨트롤러가 frame buffer memory에서 graphics display를 구동
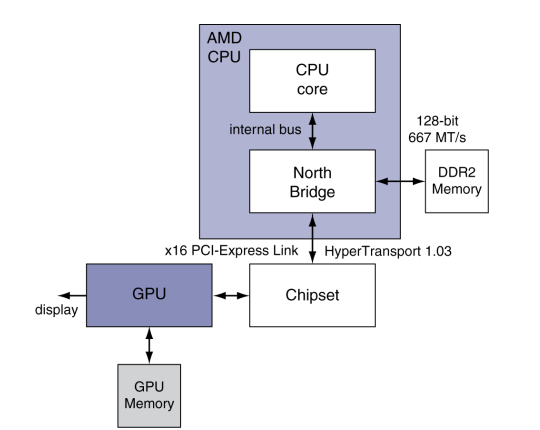
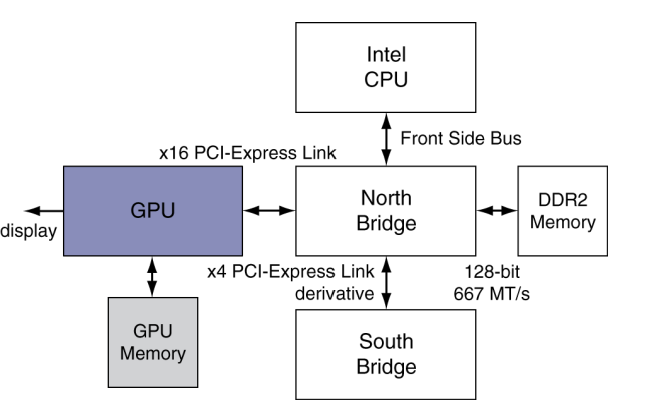
- Intel과 AMD CPU를 사용하는 현대의 PC
- PCI-Express (PCIe)
- point-to-point link를 사용하는 표준 시스템 I/O interconnect
- link는 구성 가능한 수(configurable number)의 lane과 대역폭(bandwidth)을 가짐
- point-to-point link를 사용하는 표준 시스템 I/O interconnect
- PCI-Express (PCIe)
- 통합 메모리 아키텍처 (UMA== unified memory architecture)
- CPU와 GPU가 공통 시스템 메모리를 공유하는 시스템 아키텍처
