Chapter 5: Large and Fast- Exploiting Memory Hierarchy (크고 빠른 - 메모리 계층 구조 활용)
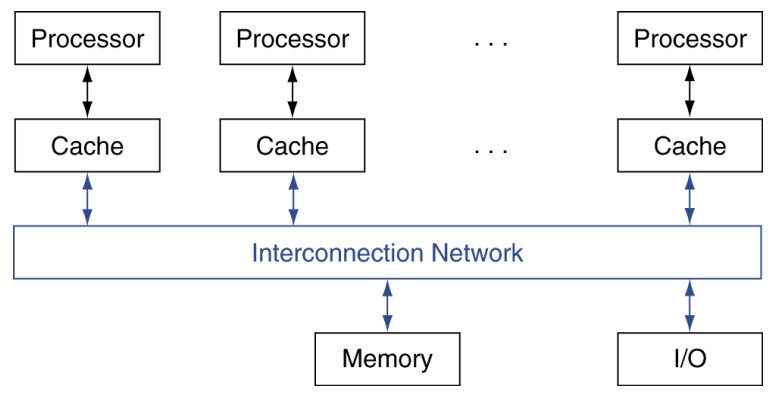
Cache Coherence Problem(캐시 일관성 문제)
🚨이 문제가 어떤 상황인지 알고 이름 말할 수 있도록 !
- 두 개의 CPU core가 물리적 주소 공간(physical address space)을 공유한다고 가정할 때
- Write-through caches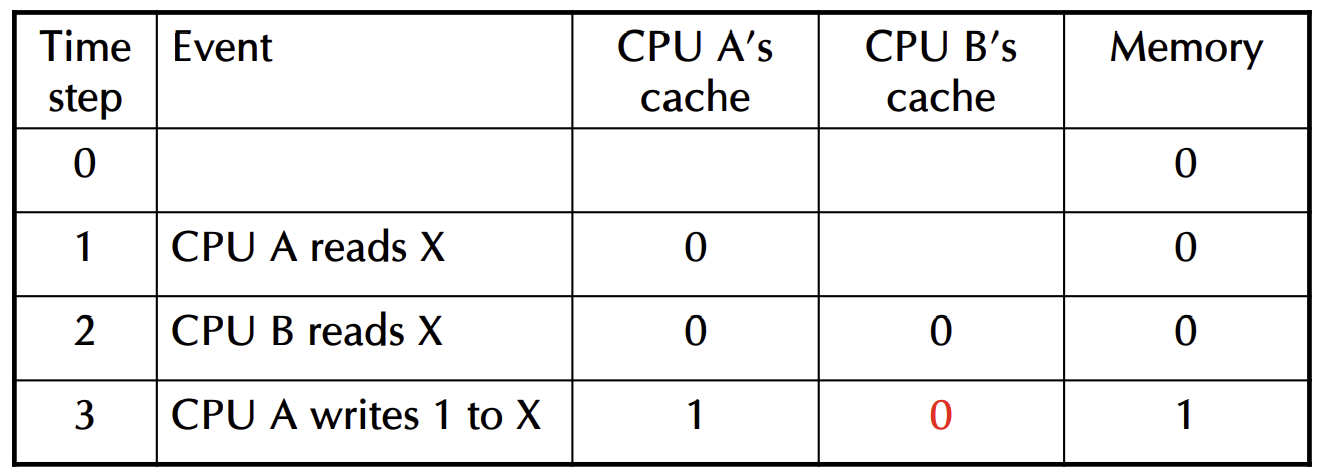
🖼️두개의 CPU Core(CPU A, CPU B)가 동일한 물리적 주소를 공유하고 있고 각 CPU가 독립적으로 캐시를 관리하는 상황
-> 각 시간 단계에서 어떤 일이 발생하는지 & 그에 따라 각 CPU의 캐시와 메모리 상태가 어떻게 변하는지 보여줌
0: 처음 시작시 CPU A와 CPU B 모두 X 변수에 접근x
1: CPU A가 X를 읽고 CPU A의 캐시에서 X 값은 여전히 0이고, CPU B의 캐시와 메모리 역시 값이 변하지 x
2: CPU B도 X를 읽고 CPU A와 CPU B 모두 X를 캐시에 저장하고 있지만, 둘 다 0으로 동일한 값을 유지
3: CPU A가 X에 값을 1로 쓰기 시작하고 이때 CPU A의 캐시는 X 값을 1로 업데이트하고, 메모리 또한 1로 업데이트됨 but CPU B의 캐시에는 아직 0이 저장
➡️핵심: 두 CPU가 같은 데이터를 읽고 쓰는 경우, 각 CPU의 캐시가 서로 다를 수 있기 때문에 발생 <<CPU A는 1을 썼지만, CPU B는 여전히 X를 0으로 가지고 있을 수 있음 & 이때, CPU B가 X를 읽을 때 1을 읽지 않고 0을 읽으면 일관성이 깨지게 되므로 이를 해결하기 위해서는 캐시 일관성 프로토콜이 필요>>
Coherence Defined(일관성의 정의)
- 비공식적으로(informally): 읽기(Reads)는 가장 최근에 기록된 값(most recently written value)을 반환해야함
- 공식적으로(formally):
- P가 X에 쓰고, P가 X를 읽는다(중간에 다른 쓰기 없음=no intervening writes)
- => 읽기는 기록된 값을 반환
- P1이 X에 쓰고, P2가 X를 읽는다(충분히 나중에==sufficiently later)
- => 읽기는 기록된 값을 반환
- ex. 위 예시에서 3단계 이후 CPU B가 X를 읽는 경우 참고
- => 읽기는 기록된 값을 반환
- P1이 X에 쓰고, P2가 X에 쓴다
- => 모든 프로세서는 동일한 순서로 쓰기를 본다
- X의 최종 값이 모두 동일해야함
- => 모든 프로세서는 동일한 순서로 쓰기를 본다
- P가 X에 쓰고, P가 X를 읽는다(중간에 다른 쓰기 없음=no intervening writes)
Cache Coherence Protocols(캐시 일관성 프로토콜)
- 다중프로세서(multiprocessors)에서 일관성을 보장하기 위해 캐시에서 수행되는 작업
- data를 local cache로 이동(migration)
- 공유 메모리에 대한 bandwidth(대역폭) 감소
- read-shared data의 복제(replication)
- 접근에 대한 경쟁(contention) 감소
- data를 local cache로 이동(migration)
- Snnoping protocols
- 각 캐시가 bus의 reads/writes를 모니터링
- Directory-based protocols
- 캐시와 메모리가 block의 공유 상태를 directory에 기록(record)
Chapter 6: Parallel Processors from Client to Cloud(클라이언트에서 클라우드까지의 병렬 프로세서)
Parallel Programming(병렬 프로그래밍)
- 병렬 소프트웨어(parallel software)가 문제의 핵심
- 상당한 성능 향상을 얻어야함
- 그렇지 않으면, 더 빠른 단일프로세서(uniprocessor)를 사용하는 것이 더 쉬움!
- 어려운 것들
- 분할(Partitioning)
- 조정(Coordination)
- 통신 오버헤드(Communications overhead)
Scaling Example
Workload(작업): 10개의 scalars sum과 10 × 10 matrix sum
- 프로세서 수를 10개에서 100개로 늘렸을 때의 속도 향상
- 단일 프로세서: 시간 = (10 + 100) × tadd
- 10개의 프로세서:
- Time = 10 × tadd + 100/10 × tadd = 20 × tadd
- 속도향상(speedup) = 110/20 = 5.5 (잠재적 최대 성능의 55%)
- 100개의 프로세서:
- Time = 10 × tadd + 100/100 × tadd = 11 × tadd
- 속도향상(speedup) = 110/11 = 10 (잠재적 최대 성능의 10%)
※ 작업(load)이 프로세서 간에 균형 있게 분배된다고 가정
Q. 행렬 크기가 100 × 100인 경우는 어떻게 될까?
- 단일 프로세서: 시간 = (10 + 10000) × tadd
- 10개의 프로세서:
- 시간 = 10 × tadd + 10000/10 × tadd = 1010 × tadd
- 속도향상(speedup) = 10010/1010 = 9.9 (잠재적 최대 성능의 99%)
- 100개의 프로세서:
- 시간 = 10 × tadd + 10000/100 × tadd = 110 × tadd
- 속도향상(speedup) = 10010/110 = 91 (잠재적 최대 성능의 91%)
※ 작업이 균형 있게 분배된다고 가정
Strong vs Weak Scaling(강한 스케일링 vs 약한 스케일링)
🚨뭐가 strong, weak인지 구분하기
- Strong scaling: 문제 크기 고정됨
- 위의 예시와 같음
- Weak scaling: 문제 크기가 프로세서 수에 비례(proportional)
- 10개의 프로세서, 10 × 10 행렬
- 시간 = 20 × tadd
- 100개의 프로세서, 32 × 32 행렬
- 시간 = 10 × tadd + 1000/100 × tadd = 20 × tadd
※ 이 예에서는 성능이 일정하게 유지됨
- 시간 = 10 × tadd + 1000/100 × tadd = 20 × tadd
- 10개의 프로세서, 10 × 10 행렬
Instruction and Data Streams
🚨그림과 표를 기억!
- 다른 분류 방식
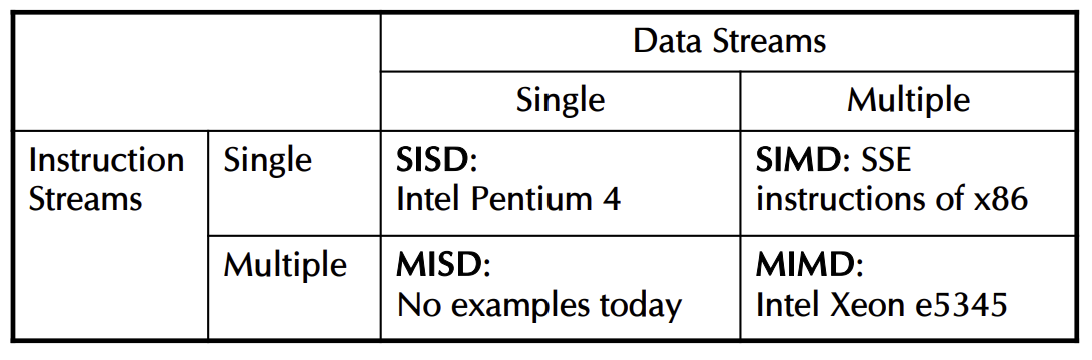
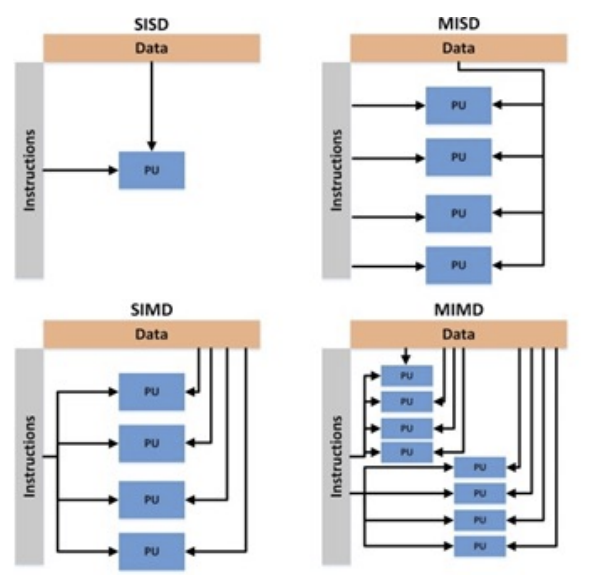
- SPMD(Single Program Multiple Data): 단일 프로그램 다중 데이터
- MIMD 컴퓨터에서 실행되는 병렬 프로그램
- 서로 다른 프로세서를 위한 조건부 코드(conditional code) 포함
Vector vs Scalar
- 벡터 아키텍처(vector architectures)와 컴파일러(compilers)
- 데이터 병렬 프로그램을 단순화
- 루프 종속성(loop-carried dependences)의 부재를 명시적으로 표현(explicit statement)
- 하드웨어에서의 checking 감소
- 규칙적인 접근 패턴이 interleaved와 burst memory의 이점을 활용
- loop를 피함으로써 control hazard를 회피
- 특수 목적의 미디어 확장(ad-hoc media extension, such as MMX, SSE)보다 더 일반적임
- 컴파일러 기술과 더 잘 맞음
SIMD(Single Instruction, Multiple Data)
-> 거의 단점이 없음!!
- 데이터 벡터에 대해 원소별 연산(operate elementwise) 수행
- ex. x86의 MMX 및 SSE 명령어
- 128-bit wide register에 여러 데이터 요소 저장
- ex. x86의 MMX 및 SSE 명령어
- 모든 프로세서가 동시에 동일한 명령을 수행
- 각 프로세서는 다른 데이터 주소 등을 사용
- 동기화(synchronization)를 단순화
- 명령어 제어 하드웨어(instruction control hardware)가 적음
- 데이터 병렬성이 높은 애플리케이션(highly data-parallel applications)에서 최적의 성능 발휘
Multithreading(멀티스레딩)
- 병렬(parallel)로 여러 thread를 실행하는 방식
- 레지스터, PC 등을 복제(replicate)
- thread 간 빠른 전환(switching)
- 세밀한 멀티스레딩(Fine-grain multithreading)
- 각 사이클마다 스레드를 전환(switch)
- 명령어 실행을 교차로 배치(interleave)
- 한 스레드가 stall(지연)되면, 다른 스레드를 실행
- 거친 멀티스레딩(Coarse-grain multithreading)
- 긴 지연(ex. L2-cache miss)에서만 스레드를 전환(switch)
- 하드웨어가 단순하지만, 짧은 stall(ex. data hazards)에서는 숨길 수 없음
Shared Memory
🚨interconnection memory랑 연결해서 보기
- SMP: 공유 메모리 멀티프로세서(shared memory multiprocessor)
- 하드웨어가 모든 프로세서에 대해 단일 물리적 주소 공간을 제공
- 공유 변수를 locks(잠금)을 사용하여 동기화(synchronize)
- 메모리 접근 시간
- UMA (일관된=uniform) vs. NUMA (비일관된=nonuniform)