Arrays: 배열
메모리 (internal implementation: 내부 구현)
-
내부적으로 프로그램에서 사용하는 모든 변수, 상수가 저장되는 곳
-
컴퓨터의 구조
- CPU: main brain data
- memory: data가 잠시 올려지는 temoporary stage
=> 특정 메모리는 특정 주소(address)로 접근해야함
For a single variable of a primitive type (int, float, …), we know its size (how many bits are needed). (==초기 유형의 단일 변수의 경우 얼마나 많은 bit가 필요한지 그 size를 알 수 있음) - DISK: disk 안 속 data가 영구적(컴퓨터의 on,off 상관없이) 저장됨
-
Q. 배열에 6을 더할때 (a.append(6))
- 이론적 시간 복잡도: O(1)
- 현실적 시간 복잡도(= append할 충분한 space가 없는 경우): O(N)
=> memory space가 어떻게 사용되는지 매번 알 필요는 없기때문에 비 이상적
- 현실적 시간 복잡도(= append할 충분한 space가 없는 경우): O(N)
배열
-
배열: memory box들의 numbered sequence로 구성된(comprise) 객체
- python list
- i번째 객체를 A[i]로 쉽게 접근할 수 있는 이유
-
배열의 구성
- fixed integer length(N) : 초기화(initialize)할때 설정해야함
- 단, List는 Array를 Resizing, Shifting, Copying하여 Dynamic length로 만든 것!!- N개의 memory boxes (0부터 N-1로 넘버링됨)
- Resizing(크기 조정) : 새 memory box와 copy operation이 필요해서 expensive
- 매번 크기 하나씩 늘림? -> 너무 많이 resizing 해야함
- 한번에 너무 크게 늘림? -> memory 낭비(wastage)로 비효율적
=> resize할때마다 python list가 0,4,8,16,25,35,46... 이런 식으로 늘어남 (규칙이 있는게 아니고 empirical하게 정한 것)
Q. data collection 중 append와 pop을 더 쉽게 할 수 있는 방법은 없을까?
Linked Lists: 연결 리스트
-
주요 아이디어
- list의 각 element들이 메모리에 흩어져있게 함(scattered)
- 대신에, 각 element는 다음 것을 가르킴
-
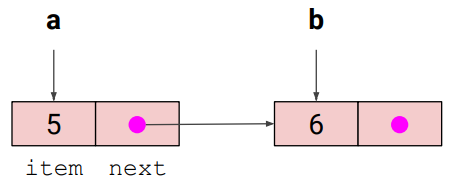
Class Node 생성
- 저장할 item
- 가르킬 next node
Singly Linked List: 단일 연결 리스트
-
기능
- 빈 list creating(생성)
- 새 항목 inserting(추가)
- 항목 retrieving(탐색)
- 기존의 항목 deleting(삭제)
-
Class LinkedList 생성
- first node에 대한 reference(참조)만 유지
- 연결리스트의 first node는 None(==element가 없음)
새 item inserting(추가)
- 1단계: 주어진 item으로 새 node 생성
- 2단계: i-1번째 위치로 이동(traverse)
- 3단계: new node의 next를 원래 i번째 node로 설정
- 4단계: i-1번째 노드의 next를 new node로 업데이트
=> 마지막에 삽입하는 item에는 작동 ⭕
=> 처음 삽입하는 item에는 작동 ❌ (i-1번째 위치가 없기 때문)
< 첫번째 위치에 삽입하는 경우>
-
1단계: 주어진 item으로 새 node 생성
-
2단계: 새 node의 next를 원래 first node로 설정
-
3단계: first node의 reference(참조)를 new node로 업데이트
=> Q. self.first=None(first item을 삽입하면) 작동함? ⭕
=> Q. i번째 위치가 마지막 item의 위치보다 크면 어떻게 됨?
A. None.next에 접근할 때 여기에서 충돌이 일어남 -> 따라서, 이를 방지해야함
Size Variable: 크기 변수
- First try
- i가 valid range 안에 있는 경우의 체크사항을 추가함
- 이때, 유효한 범위: 0 ~ 현재까지의 item 수(current length)
- Q. size를 어떻게 알 수 있을까?
- naive: 첫번째부터 None 만날때까지 traverse (효율적 x: 새 item 삽입할때 마다 O(n))
- 🌟Solution: insert, delete할 때 크기 변수를 유지하기
=> 시간 복잡도: O(1)
항목 retrieving(탐색)
- logic
- 1단계: i번째 위치로 tranverse(이동)
- 2단계: node에서 item을 반환함
- 고려할 사항
- 구현이 작동하는지?
기존의 항목 deleting(삭제)
-
1단계: i-1번째 위치로 tranverse(이동)
-
2단계: i-1번째 node의 next를 삭제타켓의 다음 node로 설정
=> 마지막에 삽입하는 item에는 작동 ⭕
=> 처음 삽입하는 item에는 작동 ❌ (i-1번째 위치가 없기 때문)
<첫번째 위치를 삭제하는 경우>
- first 다음의 node를 first로 설정함
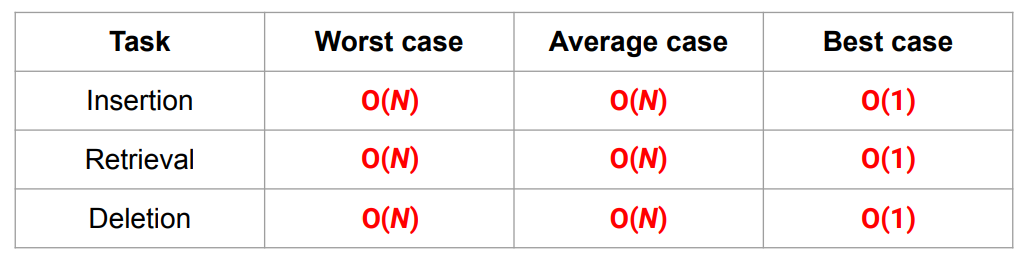
단일 연결 리스트의 시간복잡도
Doubly Linked List: 이중 연결 리스트

- 이전 item에 대한 접근할 수 있는 기능이 있을 때 사용하면 유용함
- 복잡성에 대한 점근적(asymptotic) 이점이 없음
Comparison
-
배열
- 연속적(consecutive) 메모리 공간이 할당됨
- 고정된 길이
- O(1)에서는 무작위 접근이 됨
- item shifting 어려움
-
연결리스트
- 메모리 공간에 흩어져있음(scattered)
- next 참조를 저장하기 위해서 추가 공간이 필요함
- 무작위 접근 허용 X => 탐색은 O(N)
- 사이즈 변경에 shifting 필요 X
