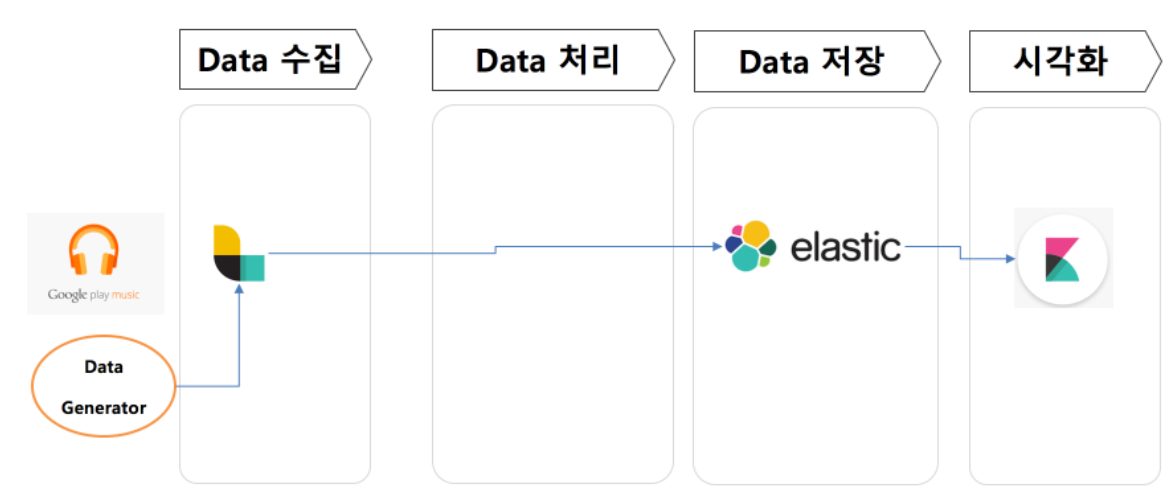
ELK란?
ElasticSearch, LogStash, Kibana 조합으로 로그 수집 - 로그 저장 및 검색 - 시각화로 쓰이게 된다.
기본 아키텍처
Logstash
특징
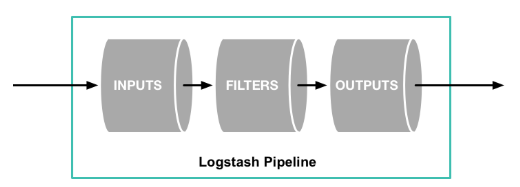
Logstash는 실시간 파이프라인 기능을 갖는 데이터 수집 엔지이며, Input을 받아 Filter를통해 가공하고 Output이 ElasticSearch의 Input이 되거나 MQ의 producer가 되는 등 파이프라인의 첫번째 단계이다.
Logstash는 여러 시스템에서 데이터 수집 및 위해 다양한 입력 Plugin을 지원하기 때문에 유연성 갖고 있다.
다른 Dataflow Tool과 차이
Streamsets, Nifi 등 ETL 툴과 다른점은 Logstash는 로그 수집하고 구문 분석해서 나중에 사용할 수 있도록하는 Log Management로 분류된다. 반면 다른 툴들은 Stream Processing 범주의 도구로 분류된다.
설정파일
Input : 로그데이터가 쌓이는 파일
Filter : 로그데이터에서 필요한 칼럼, 형변환 등 Transformation과정
Output : ElasticSearch와 연동될 경우에는 hosts는 ElasticSearch서버, 해당 서버의 index 설정
> logstash_stage1.conf
input {
file {
path => "/home/minoh1227/demo-spark-analytics/00.stage1/tracks_live.csv"
start_position => "end"
}
}
filter {
csv {
columns => ["event_id","customer_id","track_id","datetime","ismobile","listening_zip_code"]
separator => ","
}
date {
match => [ "datetime", "YYYY-MM-dd HH:mm:ss"]
target => "datetime"
}
mutate {
convert => { "ismobile" => "integer" }
}
}
output {
stdout {
codec => rubydebug{ }
}
elasticsearch {
hosts => "http://localhost:9200"
index => "ba_realtime"
}
}메세지 유실 방지
기본적으로 Memory Queue이용하기 때문에 장애 시에 memory에 있는 데이터가 사라진다. 해당 문제를 방지하기 위해서 파일에 저장하는 Persistent Queue사용하면 된다.
input - PQ - filter - output
input - Head checkpoint - filter - output - Tail checkpoint
HC지점에 큐에 들어가고 TC지점에서 ack상태 되고 큐에서 빠져나간다. 만약 비정상 종료 했다면 ack아닌 것들은 filter만 다시 처리하게 된다.
튜닝포인트
input -> Queue -> Workers 부분의 Queue에서 batch size 및 pipeline.workers 개수를 늘려서 스레드 개수를 늘려주는 방안이 있다.
https://www.elastic.co/guide/en/logstash/current/logstash-settings-file.html
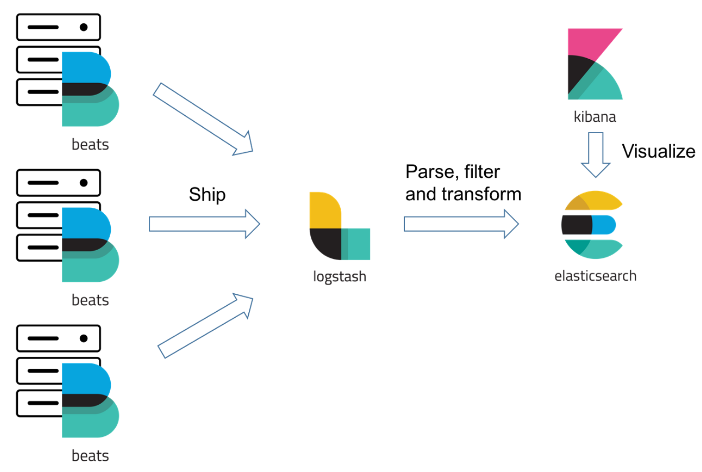
Filebeat 비교
- Logstash는 다른 서버의 파일시스템에서 로그파일을 읽지 못하기 때문에 log file shipper인 filebeat를 원천 로그 데이터 생성하는 서버에 설치해서 logstash의 특정 포트로 데이터를 전송할 수 있도록 아키텍처를 그려야한다. Logstash는 로그 받아오는 서버의 hostname기준으로 분기처리해서 ES에 전송 등 처리 할 수 있다.
- Beats는 filter이 불가능하다.
ElasticSearch
- 분산 검색 엔진으로 보통 Cluster구성하고, shard로 데이터 저장하며 replica를 저장하기 때문에 높은 HA를 제공한다.
- 실시간으로 색인되어 데이터 검색과 분석 가능
- JSON 기반으로 저장해서 Rest API 기반으로 처리한다.
analzer
데이터가 들어오면 Tokernizer, Token Filter가 특정 기준으로 토큰을 분리해서 검색 가능하도록(searchable) 가공한다.
Term Query vs Full-Text Query
Term Query경우에는 analyzer거치지 않고 검색어와 일치하는 문서 찾기. 정형 데이터 예시로는 날짜, IP주소, 제품ID 등.
Full-Text Query경우에는 analyzer 거쳐서 좀 더 복잡한 조회에 적합
RDB와 차이점
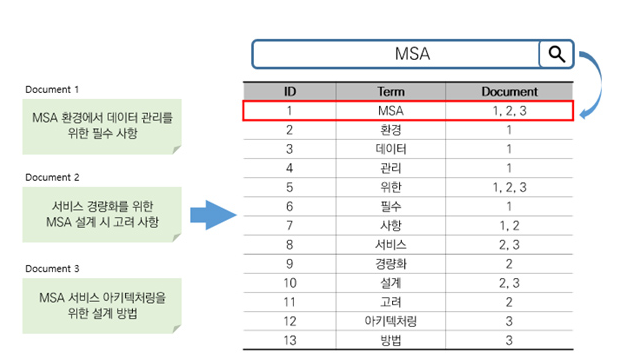
- RDB는 row기반으로 데이터 저장하지만, ES는 단어 기반(Inverted Index)로 저장한다. (일반적인 NoSQL도 역색인 지원X) 해당 단어만 찾으면 포함된 문서 위치 알 수 있다.
단점
- Rollback 지원 하지 않는다.
- update 지원하지 않는다. 기존 문서 delete -> insert 과정을 거친다.
<row 기반>
<Inverted Index 기반>
Kibana
ElasticSearch에 있는 데이터를 검색하여 분석 및 시각화한다. Histograme, Geo 맵 등 여러 시각화를 편리하게 할 수 있다. ElasticSearch의 결과를 보여주는 것이기 때문에 ElasticSearch가 필수로 선행된다.
대표적인 카테고리
Discover
ElasticSearch의 Index에있는 데이터 탐색 시 사용
DashBoard
필요한 차트를 구성해서 DashBoard 구성
ELK 아키텍처 한계
- 사용자 증가로 처리 용량 한계
LogStash는 단일 Instance기 때문에 분산 작업을 하지 못한다. 물론 LogStash를 여러개 두어 병렬 처리를 할 수 있지만 클러스터 모드가 없기 때문에 dead Instance 작업을 하지 않는다. - 더 많은 데이터 통해 분석 필요
현재 LogStash에서 ElasticSearch에 데이터가 넘어갈 때 고객의 정보가 더 있으며 좋겠다. 그럴 때는 Redis에 미리 고객 데이터를 넣고 LogStash에서 filter에서 Redis에 있는 정보를 추가할 수 있다.
Reference
(logstash)
https://blog.naver.com/PostView.nhn?blogId=wideeyed&logNo=222153700165
