질문
- 파티션을 늘리면 Round-Robin 방식으로 메세지가 쓰이는데 순차적으로 consume 보장 하지 않는다는데 이유는? Consumer Group내에 Consumer 가 같은 서버 내에 있다면 상관 없는 거 아닌가
- Consumer Group내에 Consumer 가 같은 서버에서 구분 된 것이라면 그 자체로도 성능이 높아지는지
- Spark와 하둡 차이
확인해야할 점
- Zookeeper 역할
- RabbitMQ fail-over
이전 아키텍처 한계 극복
https://velog.io/@minsuk/ELK-%EC%8A%A4%ED%83%9D-%EA%B5%AC%EC%B6%95
해당 글의
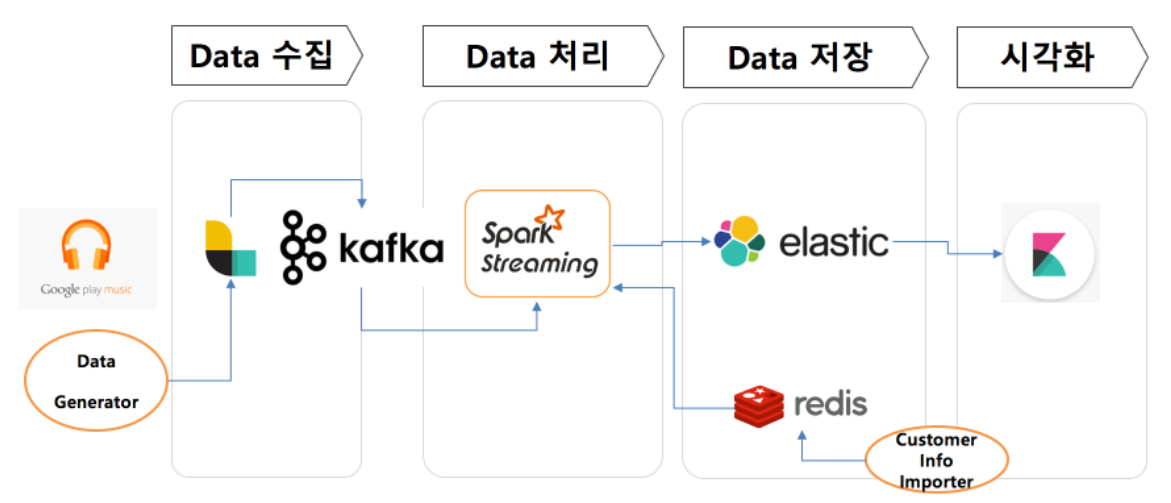
Kafka
이벤트 스트리밍 플랫폼, pub/sub구조.
기본 아키텍처
Producer가 topic에 데이터 전송, Broker가 데이터 저장, Consumer가 데이터 가져간다
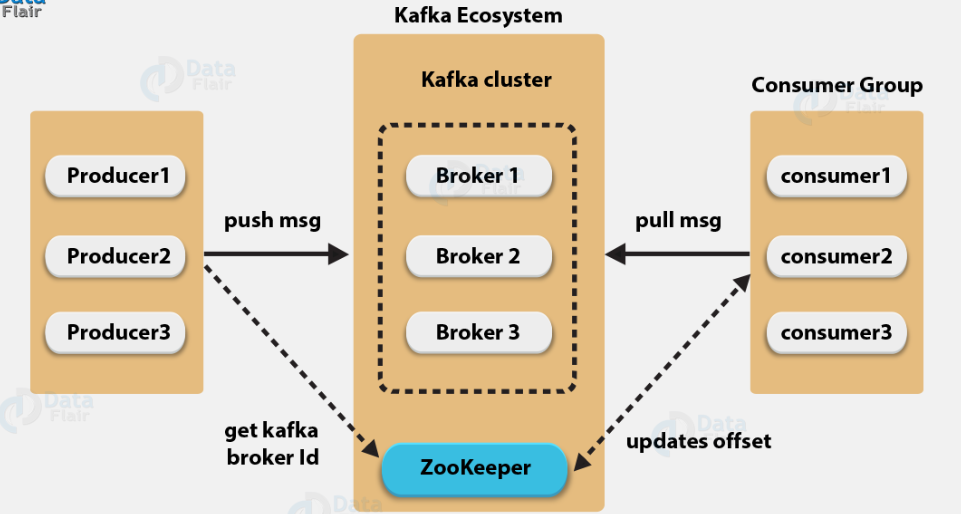
Topic & Partition
Topic은 여러개의 partition으로 나눠지고, partition 내 한 칸은 로그다. partition 내 로그 위치는 offset이다. partition을 늘리면 그만큼 분산처리가 되다보니 throughput이 높아진다. 하지만 파티션을 늘리면 Round-robin 방식으로 쓰여짐에 따라 순차적으로 메세지가 쓰여지지 않는 단점이 있다.
Topic이 각 Consumer group이 파티션 별 offset 위치를 기억하기 때문에 fail-over 상황에 대비할 수 있다.
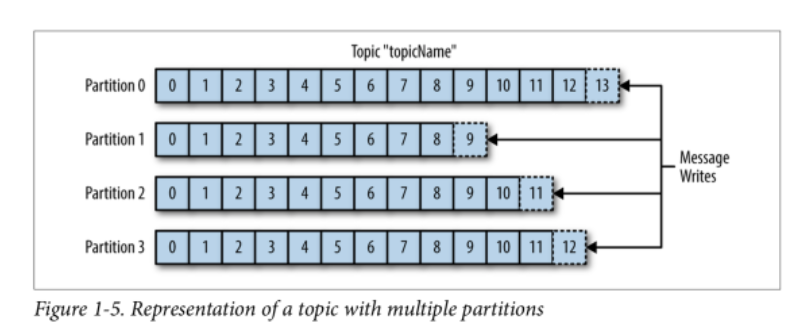
Consumer Group
Consumer Group은 하나의 topic을 담당하는데 Group내 Consumer 하나 가 down 되면 다른 Consumer 가 해당 partition을 담당하면서 Rebalance 할 수 있다.
Broker, Zookeeper
Broker(Kafka)를 여러 개 둠으로써 클러스터를 구성할 수 있고 이에 따른 Replication르 두어 수평적인 scale-out과 높은 HA를 유지할 수 있다. Zookeeper는
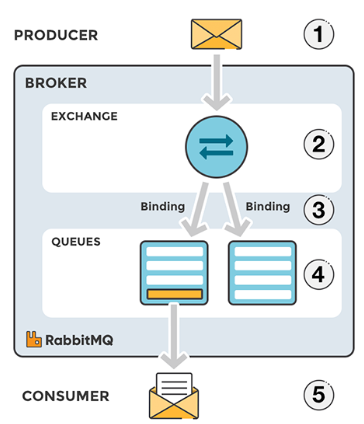
RabbitMQ(MQ)와 차이
- Zookeeper 같은 코디네티어가 따로 없음
- Topic 대신 Exchange와 Queue & binding 통해서 메세지 소비
- 높은 Throughput보다는 지정된 수신이에게 원하는 방식으로(Exchange) 신뢰성 있게 전달에 초점. 복잡한 라우팅.
- 하나의 consumer만 데이터를 읽을 수 있음
단점 : 결합력이 높아지면서 트래픽이 증가하더라도 scale-out 한계
Spark
하둡과의 차이는
1. hdfs에서 데이터를 불러와서 메모리에 놓고, 인메모리 프로세싱 통해 빠르게 수행
하둡은 반복작업 수행할 때마다 디스크에 접근하기 때문에 실시간 데이터 니즈가 증가함에 따라 실시간 작업 불가능. 보통 그래서 하둡은 배치성 통계작업에 사용
2. stream processing
