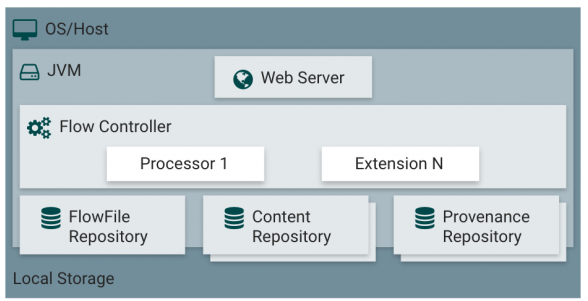
Nifi 아키텍처
Nifi Cluster
master노드가 없기 때문에 SPOT가 되지 않아서 zero master clsutering이라고 볼 수 있다.
클러스터 사용하면, 각 인스턴스가 동일한 데이터 flow를 통해 병렬로 데이터를 처리한다. flow 변경이 일어나면 나머지 노드들이 변경 사항 복사함
Cluster Coordinator
: 각 NiFi 서버들의 정보(가동 여부, 상태)를 관리하며, DataFlow의 추가, 수정, 삭제 등의 변경을 클러스터에 등록된 NiFi 노드들에 복제해줍니다.
질문 : default가 작업분배안하는거면 why clustering?
Load Balance strategy
- Do not load balance
- Partition by attribute
- Round robin
- Single nodeLoad Balance Compression
- Do not compress
- Compress attributes only
- Compress attributes and content Available Prioritizers
- FisrstInFirstOutPrioritizer
- NewsestFlowFileFirstPrioritizer
- OldestFlowFileFirstPrioritizer
- PriorityAttributePrioritizersContent Repository
https://eyeballs.tistory.com/347
https://paulsmooth.tistory.com/203
Reference
https://www.popit.kr/bigdata-platform-based-on-nifi/
https://www.popit.kr/apache-nifi-overview-and-install/
https://paulsmooth.tistory.com/203?category=957200
https://taaewoo.tistory.com/40
https://gist.github.com/cheerupdi/87eacaa87b74feee4de0bb5eba0216d2
(clustering)
http://eg3020.blogspot.com/2020/11/apache-nifi-2-queued.html
https://gist.github.com/cheerupdi
https://blog.ex-em.com/1575
https://eyeballs.tistory.com/311
https://eyeballs.tistory.com/320
https://justkook.blogspot.com/2018/02/nifi-clustering-hahigh-availability.html
