BFS/DFS
그래프의 탐색은 하나의 정점에서 시작하여 모든 정점들을 한 번씩 방문(탐색)하는 것이 목적이다
그래프의 데이터는 배열처럼 정렬이 되어 있지 않다 그래서 원하는 자료를 찾으려면 하나씩 모두 탐색해서 찾아야 한다.
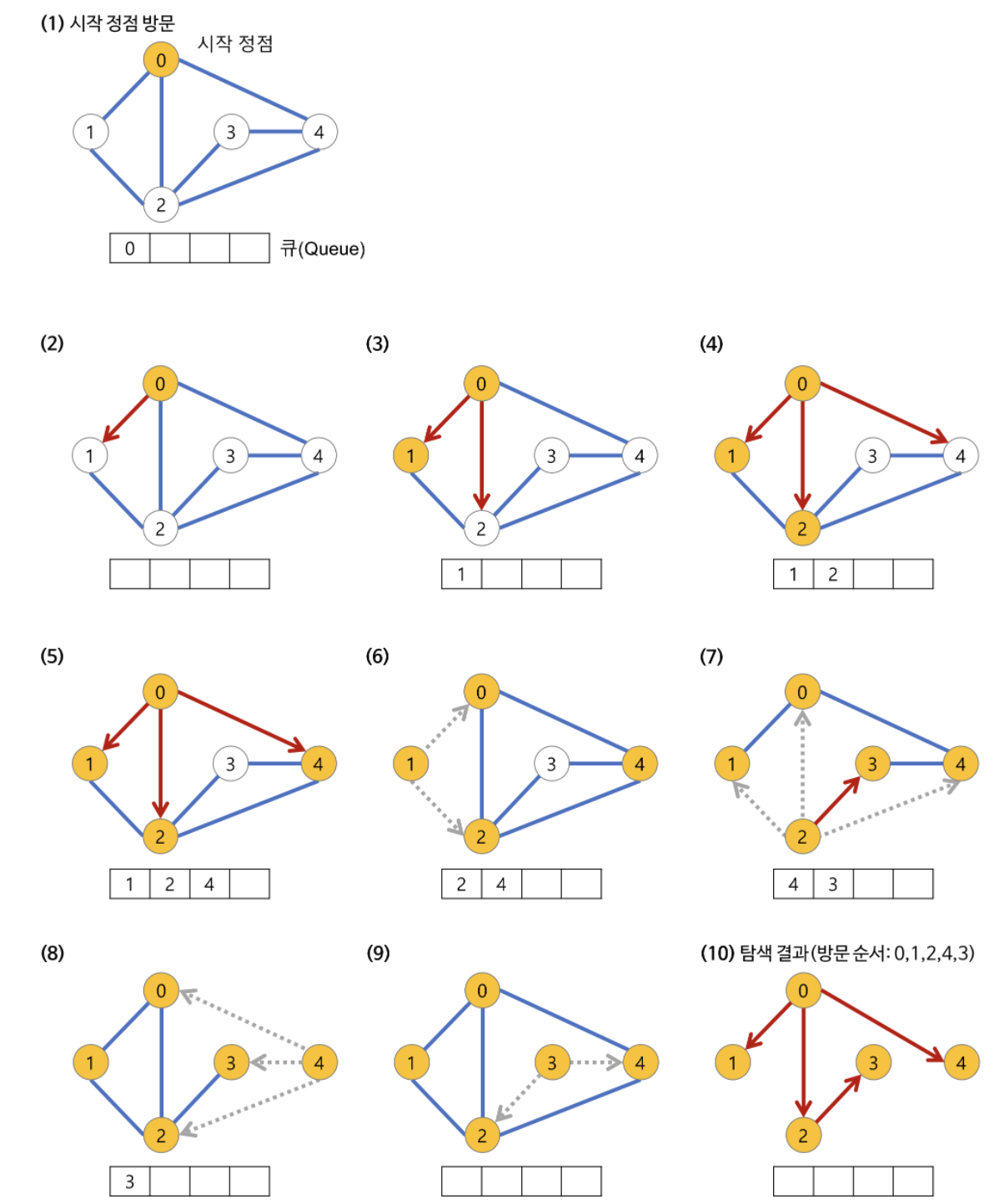
BFS(너비 우선 탐색, Breadth-First Search)
너비 우선 탐색이란?
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
-
시작 정점으로부터 가까운 정점을 먼저 탐색하고 멀리 떨어져 있는 정점을 나중에 탐색하는 순회 방법
-
깊게(deep) 탐색하기 전 넓게(wide) 탐색하는 것이다.
-
예) 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 사용
- 지구상 존재하는 모든 친구 관계를 그래프로 표현한 후 Ash와 Vanessa사이에 존재하는 경로를 찾는 경우
- 깊이 우선 탐색 - 모든 친구 관계를 다 살펴봐야 할지도 모른다
- 너비 우선 탐색 - Ash와 가까운 관계부터 탐색
-
너비 우선 탐색이 깊이 우선 탐색보다 좀 더 복잡하다
BFS의 특징
-
직관적이지 않은 면이 있다
- BFS는 시작 노드에서 시작해서 거리에 따라 단계별로 탐색한다고 볼 수 있다.
-
BFS는 재귀적으로 동작하지 않는다.
-
가장 큰 차이점은 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야 한다는 것
- 만약 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
-
BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용한다.
- 선입선출(FIFO) 원칙으로 탐색
- 일반적으로 큐를 이용해 반복적 형태로 구현하는 것이 가장 잘 동작한다
-
'Prim','Dijkstra' 알고리즘과 유사하다
너비 우선 탐색(BFS)의 시간 복잡도
-
인접 리스트로 표현된 그래프: O(N+E)
-
인접 행렬로 표현된 그래프: O(N^2)
-
깊이 우선 탐색(DFS)과 마찬가지로 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
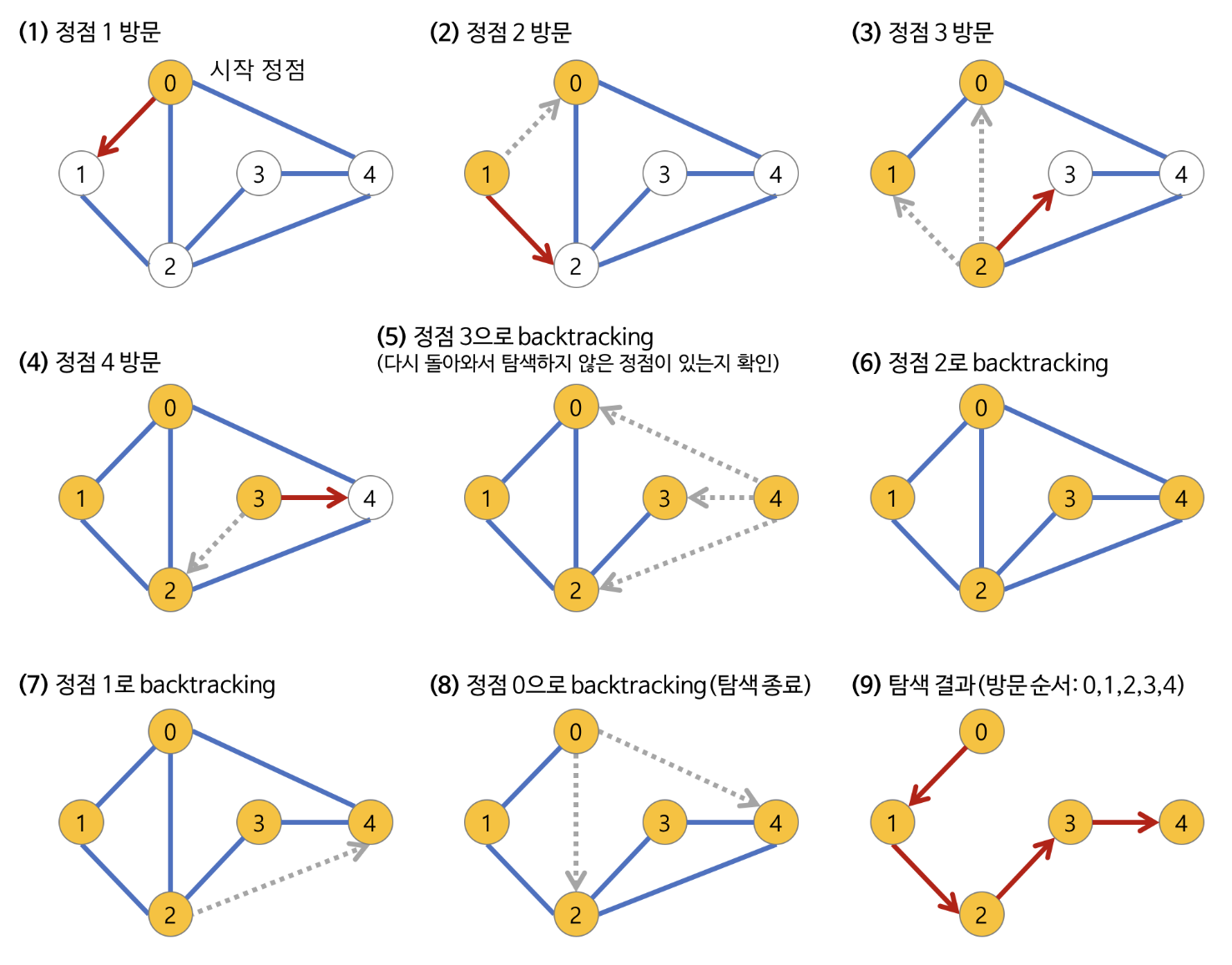
DFS (깊이 우선 탐색, Depth-First Search)
깊이 우선 탐색이란?
루트 노드(혹 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전 해당 분기를 완벽하게 탐색하는 방법 -
미로를 탐색할 때 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 될때 다시 가장 가까운 갈림길로 돌아와 이곳으로붕터 다른 방향으로 다시 탐색을 진행하는 방법과 유사하다
-
넓게(wide) 탐색하기 전 깊게(deep) 탐색하는 것이다.
-
사용하는 경우는 모든 노드를 방문 하고자 하는 경우에 이 방법을 쓴다.
-
깊이 우선 탐색이 너비 우선 탐색보다 좀 더 간단하다
-
단순 검색 속도 자체는 너비 우선 탐색에 비해 느리다
깊이 우선 탐색의 특징
-
자기 자신을 호출하는
순환 알고리즘의 형태를 가진다. -
전위 순회(Pre-Order Traversals)를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류이다
-
가장 큰 차이점은 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사한다
- 검사하지않는 경우 무한루프에 빠질 위험이 있다.
깊이 우선 탐색(DFS)의 시간 복잡도
- DFS는 그래프(정점의 수: N, 간선의 수: E)의 모든 간선을 조회한다.
- 인접 리스트로 표현된 그래프: O(N+E)
- 인접 행렬로 표현된 그래프: O(N^2)
즉, 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
출처
https://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html
