최근 제안 작업을 위해 최신 AI 모델에 대한 조언을 듣는 중 흥미로운 모델에 대해서 듣게 되었다. 기존에 MoE(Mixture of Experts) 기술에 대해서 얼핏 듣긴 하였으나 이것으로 LLaMA-2 70B 모델의 성능을 넘었다는 Mixtral model의 이야기는 흥미로웠다.
Sparse Mixture of Experts(SMoE)
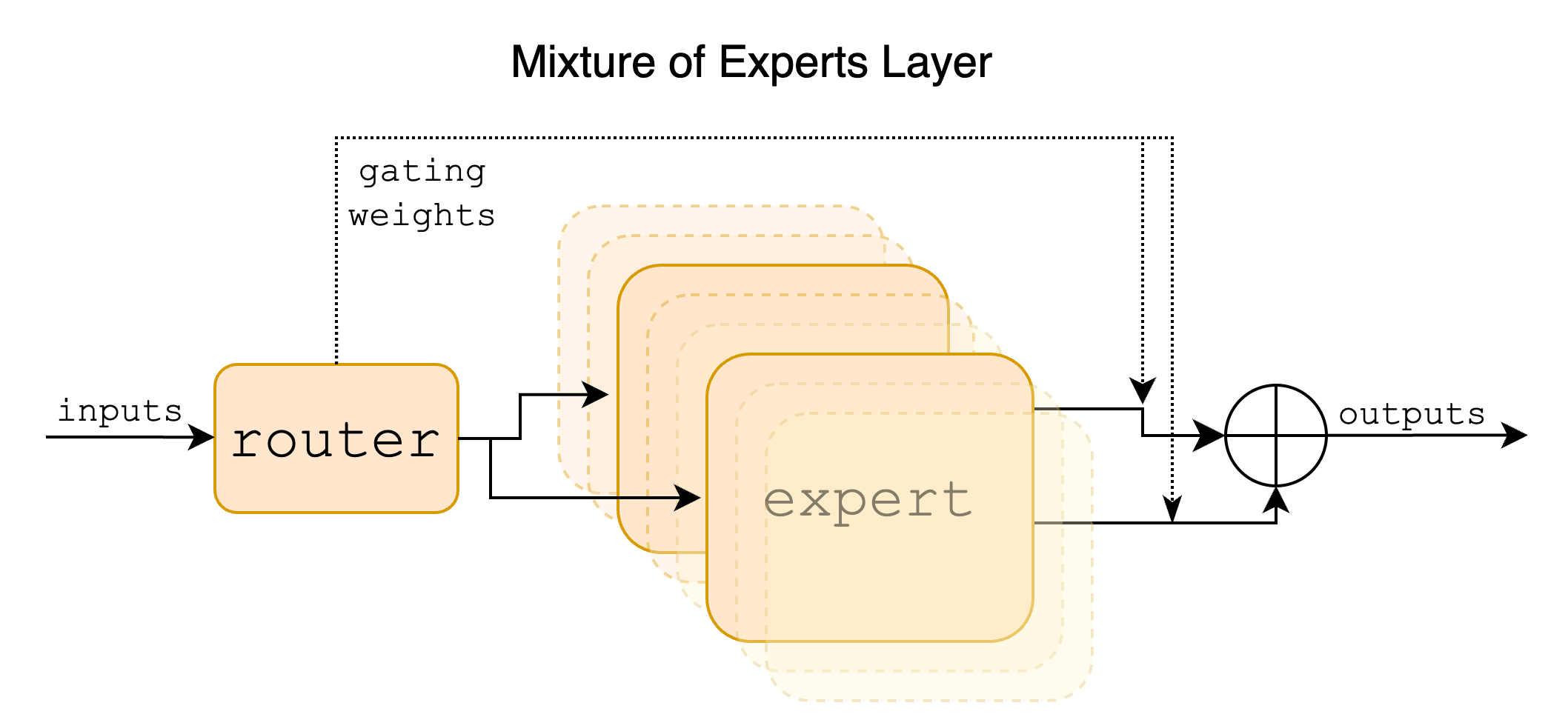
이 모델은 총 8개의 Mistral 7B 모델 8개에 Sparse Mixture of Experts(SMoE) 방식을 도입한 모델이다.
SMoE 방식은 큰 규모의 모델을 한번에 돌리는 것이 아닌 여러 Experts로 나누어 처리량과 메모리 비용을 분리할 수 있게 해주며, 각 토큰마다 전체 모델의 일부분만을 활성화하여 처리한다. 이 접근법에서 각 토큰은 하나 이상의 "Experts"(별도의 가중치 세트)에 할당되며, 오직 해당 Expert 모델에 의해서만 처리된다. 이러한 분할은 모델의 Feed Forward 레이어에서 일어나고 결론적으로 Experts 모델은 데이터의 다양한 측면을 전문화하여 복잡한 패턴을 포착하고 더 정확한 예측을 할 수 있게 한다.
모델 파라미터
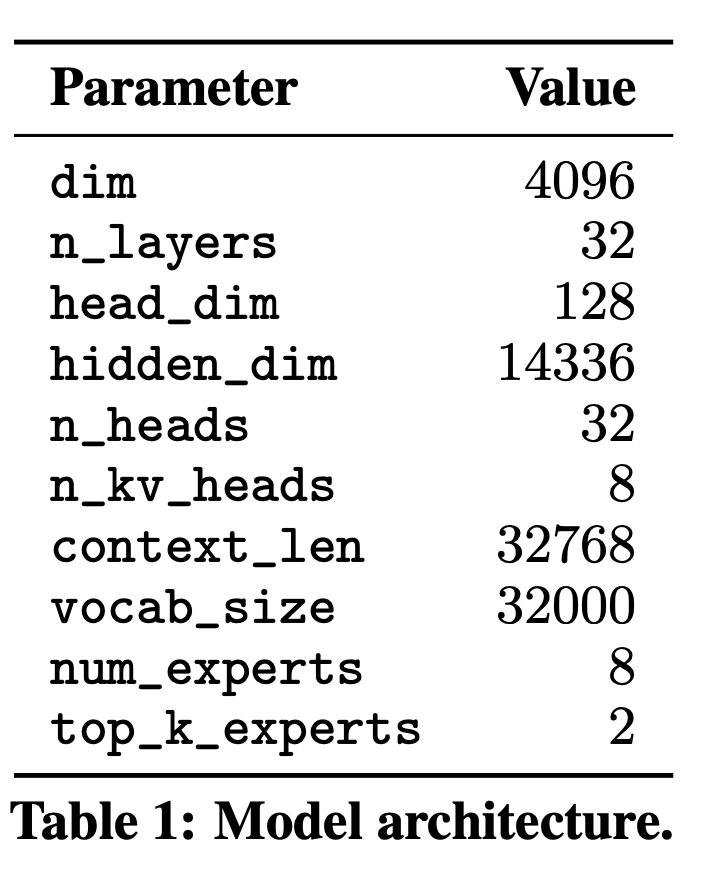
위에서 볼 수 있듯이 32768 token을 처리할 수 있고, 8개의 experts의 architecture를 가지고 있다. 이 중 모든 레이어에서, 각 토큰마다 라우터 네트워크가 두 개의 'Experts'를 선택하여 토큰을 처리하고 그들의 출력을 결합해 출력한다.
모델의 특수성
이 기술은 모델이 토큰 당 전체 파라미터 세트의 일부만을 사용하기 때문에 비용과 지연 시간을 제어하면서 모델의 파라미터 수를 증가시킨다. 구체적으로, Mixtral은 총 46.7B의 파라미터를 가지고 있지만 토큰 당 12.9B의 파라미터만을 사용합니다. 따라서, 12.9B 모델과 같은 속도와 비용으로 입력을 처리하고 출력을 생성할 수 있다는 것이 장점이다. LLM 같은 경우 성능을 유지하면서 meomory cost와 속도를 줄이는 것이 중요한데 효과적으로 이뤄냈다..
Mixtral은 공개 웹에서 추출한 데이터로 사전 학습되며, 전문가와 라우터를 동시에 학습하는 방법으로 학습이 된다.
모델 성능
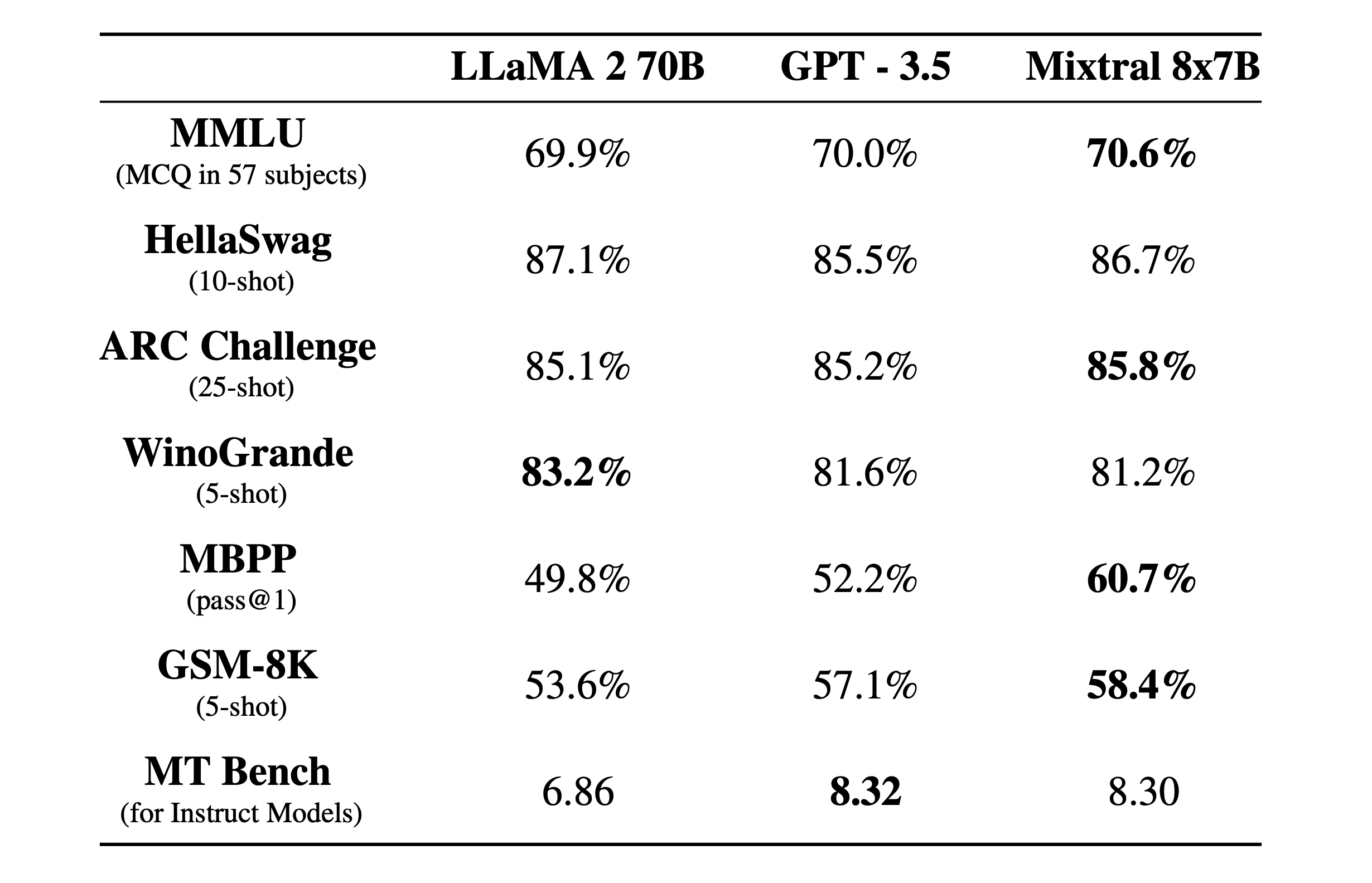
위에서 확인할 수 있다시피 Mixtral 8x7B 모델의 경우 Open Source 모델 중 가장 큰 성능을 자랑하는 LLaMA 2 70B 모델과 GPT -3.5 모델에 비해 여러 지표에서 상회하고 있는 것을 확인할 수 있다. 코드를 작성하는 MBPP Benchmark의 경우 상대적으로 꽤나 높은 점수를 보이고 있고, 나머지는 성능이 비슷하다고 하더라도 이를 학습하는 비용이나 inference 비용이 다른 모델보다 현저히 적다고 했을 때 효율적이라고 볼 수 있다.
아래 표를 보면 LLaMA 2 모델에 비해 파라미터 별로 얼마나 큰 성능 차이를 보이는지 확인할 수 있다.
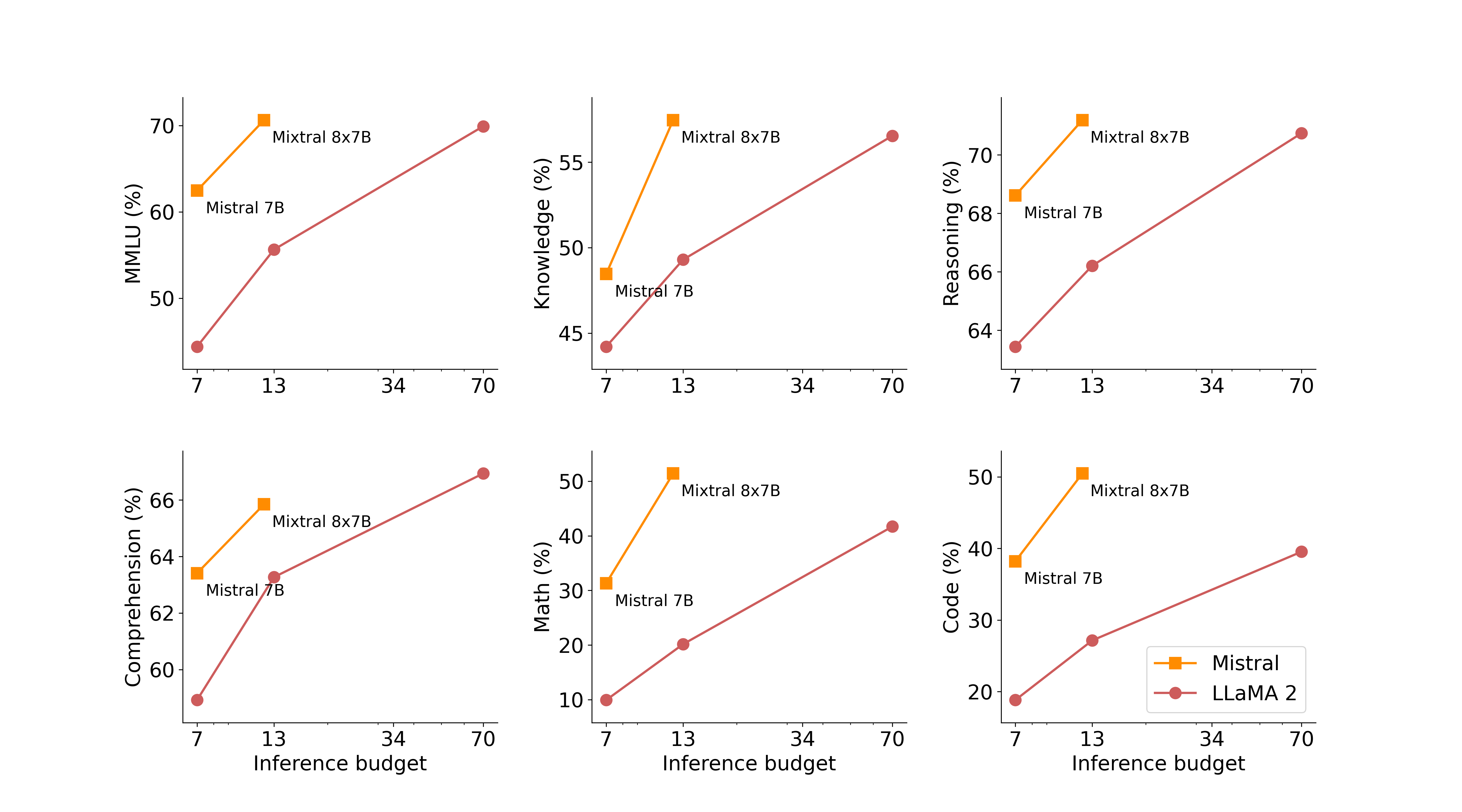
고려점
위 모델은 SMoE의 구조로 학습하여 다른 모델에 비해 적은 비용과 시간으로 성능 좋은 모델을 학습할 수 있고, 사용할 수 있다는 장점이 있다. 하지만 사용에 있어서 몇 가지 고려해야 할 포인트 들이있다.
-
영어, 불어, 이탈리아어, 독일어, 스페인어 5가지 모델에 있어서만 좋은 성능을 보이고 한국어 성능이 좋지 않다는 점이다.
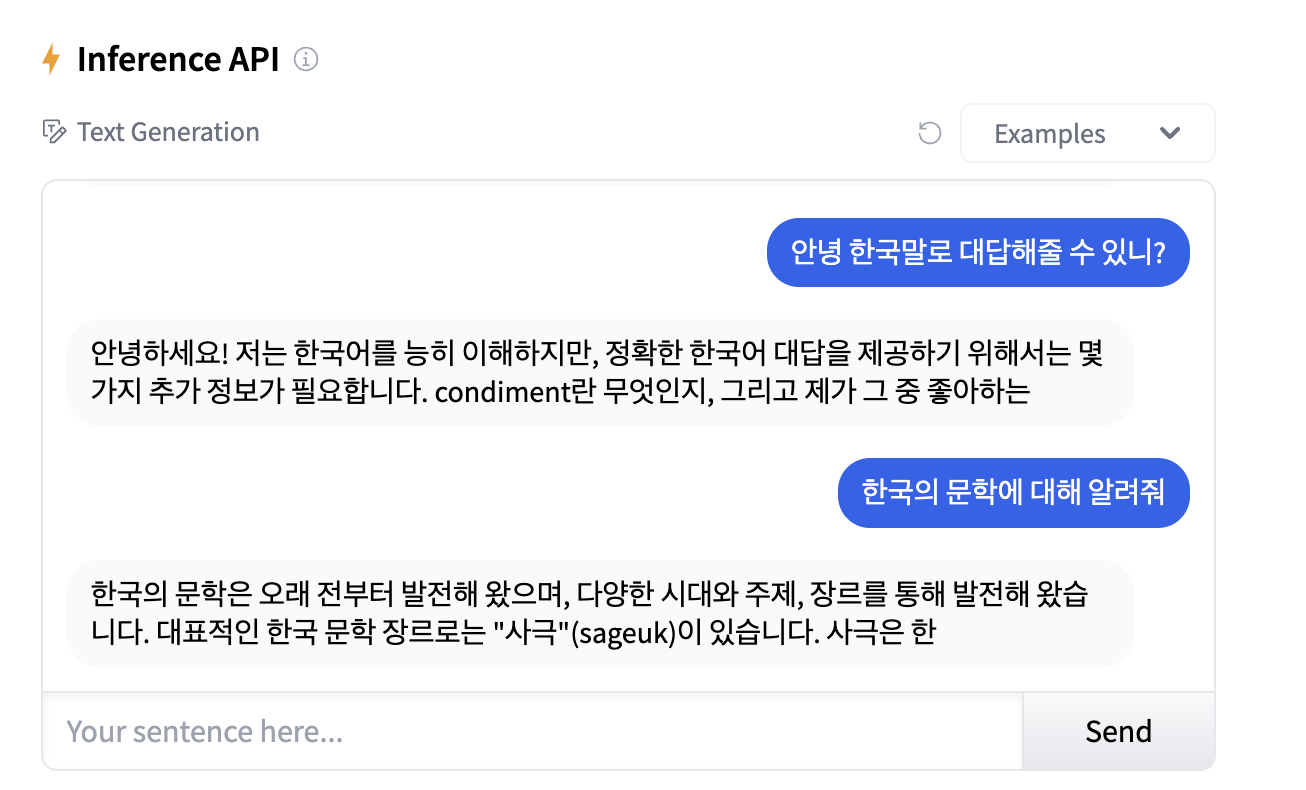
실제 한국어를 HuggingFace Inference API를 활용해 사용해봤을 때 좋지 않은 성능임을 확인할 수 있다. -
Mixtral 모델은 강한 수준의 수정이 필요한 애플리케이션을 구성하는데 일부 출력을 금지하도록 학습되어 있다.
위 고려점을 고려하여 프로젝트에 활용하거나, SMoE 구조를 적극 도입하여 활용하는 것이 현명할 것 같다.
