
Custom Hook
https://airflow.apache.org/docs/apache-airflow/stable/_modules/airflow/hooks/base.html
BaseHook
BaseHook클래스를 상속받아 직접 만든 Hook을 사용 가능
get_connection()
- Connection 객체를 가져오는 메서드
classmethod로 설정되어 있어 객체화하지 않고도 호출 가능
@classmethod
def get_connection(cls, conn_id: str) -> Connection:
"""
Get connection, given connection id.
:param conn_id: connection id
:return: connection
"""
from airflow.models.connection import Connection
conn = Connection.get_connection_from_secrets(conn_id)
log.info("Connection Retrieved '%s'", conn.conn_id)
return connget_hook()
- Connection 객체로부터 Hook 객체를 반환하는 메서드
classmethod로 설정되어 있어 객체화하지 않고도 호출 가능
@classmethod
def get_hook(cls, conn_id: str, hook_params: dict | None = None) -> BaseHook:
"""
Return default hook for this connection id.
:param conn_id: connection id
:param hook_params: hook parameters
:return: default hook for this connection
"""
connection = cls.get_connection(conn_id)
return connection.get_hook(hook_params=hook_params)get_conn()
- Hook 객체에 대한 연결을 구현하는 메서드로, 반드시 재정의해야 함
def get_conn(self) -> Any:
"""Return connection for the hook."""
raise NotImplementedError()PostgresHook 개선점 파악
이전에 만들었던 네이버 쇼핑 검색 결과에 대한 CSV 파일을 적재하는 PostgresHook의 기능을 개선
- 구분자가
Tab으로 고정되어 있고, 헤더까지 포함해서 업로드 됨- Psycopg 공식 문서에 따르면,
CSV HEADER구문을 뒤에 붙여 헤더를 제외할 수 있음 - 또한,
COPY문 뒤에DELIMITER구문을 추가해 구분자를 지정할 수도 있음
- Psycopg 공식 문서에 따르면,
- 테이블이 없으면 에러가 발생함, 또한 직접 테이블을 생성하는 것도 불편함
- CSV 파일의 헤더를 읽어서
CREATE TABLE문을 만들고, 위COPY문 앞에 붙여서 테이블 생성 - 또한, 더 정확한 테이블 구성을 위해 모든 열을
text타입으로 지정하지 않고, CSV 파일의 전체 또는 일부를 읽어서int4타입의 열을 추측할 수 있을 것이라 판단
- CSV 파일의 헤더를 읽어서
- 기존엔 데이터를 계속해서 추가했는데, 덮어쓰기 옵션을 통해 이전 데이터를 지울 수도 있으면 더 좋을 것이라 생각함
Hook 기능 정의
CSV 파일을 PostgreSQL 테이블에 적재하는데, 테이블이 없으면 생성하고, 덮어쓰기도 허용
CustomPostgresHook
BaseHook을 상속받는CustomPostgresHook를 구현- 기본적인 구성은 Postgres Provider 문서에서 제공하는 소스코드를 참고
- Hook 재사용을 위해
plugins/경로 아래에 추가
# plugins/hooks/postgres.py
from airflow.hooks.base import BaseHook
from typing import Literal
import psycopg2
class CustomPostgresHook(BaseHook):
def __init__(self, postgres_conn_id: str, **kwargs):
self.postgres_conn_id = postgres_conn_id
self.conn = None
self.database = kwargs.get("database")
def get_conn(self) -> psycopg2.extensions.connection:
conn = BaseHook.get_connection(self.postgres_conn_id)
conn_args = {
"host": conn.host,
"user": conn.login,
"password": conn.password,
"dbname": self.database or conn.schema,
"port": conn.port,
}
self.conn = psycopg2.connect(**conn_args)
return self.conn
def bulk_load(self, table: str, filename: str, encoding="utf-8",
if_exists: Literal["append","replace"]="append", sep=',', with_header=True):
create = self._create_table_sql(table, filename, encoding, sep, with_header)
replace = "TRUNCATE TABLE {};".format(table) if if_exists == "replace" else str()
copy = "COPY {} FROM STDIN DELIMITER '{}' {};".format(table, sep, ("CSV HEADER" if with_header else "CSV"))
sql = ''.join([create, replace, copy])
self.copy_expert(sql, filename, encoding)
def _create_table_sql(self, table: str, filename: str, encoding="utf-8", sep=',', with_header=True) -> str:
if with_header:
column_list = self._read_csv_column_list(filename, encoding, sep)
return "CREATE TABLE IF NOT EXISTS {}({});".format(table, column_list)
else:
return str()
def _read_csv_column_list(self, filename: str, encoding="utf-8", sep=',') -> str:
import csv
def is_int4_type(value: str) -> bool:
return (not value) or (value.isdigit() and (-2147483648 <= int(value) <= 2147483647))
with open(filename, "r+", encoding=encoding) as file:
reader = csv.reader(file, delimiter=sep)
header = next(reader)
dtypes = [all(map(is_int4_type, values)) for values in zip(*[next(reader) for _ in range(5)])]
return ", ".join(["{} {}".format(col, ("int4" if is_int4 else "text")) for col, is_int4 in zip(header, dtypes)])
def copy_expert(self, sql: str, filename: str, encoding="utf-8") -> None:
from contextlib import closing
self.log.info("Running copy expert: %s, filename: %s", sql, filename)
with open(filename, "r+", encoding=encoding) as file, closing(self.get_conn()) as conn, closing(conn.cursor()) as cur:
cur.copy_expert(sql, file)
file.truncate(file.tell())
conn.commit()PostgreSQL 연결
get_conn()
PostgresHook의get_conn()메서드와 유사한데, 메서드를 호출할 때마다Connection객체를 가져와 연결 정보를 읽어오는데 차이가 있음psycopg2라이브러리를 사용해 PostgreSQL에 연결하고psycopg2.extensions.connection객체를 반환
def get_conn(self) -> psycopg2.extensions.connection:
conn = BaseHook.get_connection(self.postgres_conn_id)
conn_args = {
"host": conn.host,
"user": conn.login,
"password": conn.password,
"dbname": self.database or conn.schema,
"port": conn.port,
}
self.conn = psycopg2.connect(**conn_args)
return self.conn쿼리문 생성
bulk_load()
f"COPY {table} FROM STDIN"형식의 단순한 SQL문을 사용하던 기존bulk_load()메서드를 개선create:_create_table_sql()메서드를 통해CREATE TABLE문 생성replace:if_exists파라미터 값에 따라 테이블 내용을 모두 삭제하는 구문을 선택적으로 추가copy: 구분자 또는 헤더 포함 여부 등을 파라미터로 받고 이를 활용하여COPY문 생성
def bulk_load(self, table: str, filename: str, encoding="utf-8",
if_exists: Literal["append","replace"]="append", sep=',', with_header=True):
create = self._create_table_sql(table, filename, encoding, sep, with_header)
replace = "TRUNCATE TABLE {};".format(table) if if_exists == "replace" else str()
copy = "COPY {} FROM STDIN DELIMITER '{}' {};".format(table, sep, ("CSV HEADER" if with_header else "CSV"))
sql = ''.join([create, replace, copy])
self.copy_expert(sql, filename, encoding)_create_table_sql()
- 헤더가 있을 경우에 한정해,
_read_csv_column_list()메서드를 통해 열 목록을 가져오고,CREATE TABLE문 안에 열 목록을 포맷팅해 반환 IF NOT EXISTS구문을 추가해 테이블이 이미 존재할 경우는 테이블 생성 생략- 헤더가 없을 경우에는 기본적으로 테이블 생성 무시
def _create_table_sql(self, table: str, filename: str, encoding="utf-8", sep=',', with_header=True) -> str:
if with_header:
column_list = self._read_csv_column_list(filename, encoding, sep)
return "CREATE TABLE IF NOT EXISTS {}({});".format(table, column_list)
else:
return str()_read_csv_column_list()
- 헤더와 상위 5개 행을 읽어서 데이터 타입을 추정하고, 이를 바탕으로 테이블의 열 목록을 정의
- 데이터 타입은
int4또는text두 가지 경우만 판단하며,int4범위에 있는 숫자형 문자 또는 NULL 값으로만 구성된 열은int4타입으로 지정하고, 나머지는text타입으로 지정
def _read_csv_column_list(self, filename: str, encoding="utf-8", sep=',') -> str:
import csv
def is_int4_type(value: str) -> bool:
return (not value) or (value.isdigit() and (-2147483648 <= int(value) <= 2147483647))
with open(filename, "r+", encoding=encoding) as file:
reader = csv.reader(file, delimiter=sep)
header = next(reader)
dtypes = [all(map(is_int4_type, values)) for values in zip(*[next(reader) for _ in range(5)])]
return ", ".join(["{} {}".format(col, ("int4" if is_int4 else "text")) for col, is_int4 in zip(header, dtypes)])쿼리문 실행
copy_expert()
PostgresHook의copy_expert()메서드와 동일한데, 한글 CSV 파일은EUC-KR등 다른 인코딩이 필요할 수 있어encoding파라미터를 추가
def copy_expert(self, sql: str, filename: str, encoding="utf-8") -> None:
from contextlib import closing
self.log.info("Running copy expert: %s, filename: %s", sql, filename)
with open(filename, "r+", encoding=encoding) as file, closing(self.get_conn()) as conn, closing(conn.cursor()) as cur:
cur.copy_expert(sql, file)
file.truncate(file.tell())
conn.commit()DAG
Custom Hook 활용
plugins/에 정의한CustomPostgresHook을 활용- 실행 날짜에 생성된
shop.csv파일을 보고nshopping.search2테이블을 생성 및 적재 shop.csv파일을 굳이shop_with_tab.csv파일로 가공할 필요성을 줄여서 편의성 개선
# dags/python_with_postgres_custom.py
from airflow.sdk import DAG
from airflow.providers.standard.operators.python import PythonOperator
from hooks.postgres import CustomPostgresHook
import pendulum
with DAG(
dag_id="python_with_postgres_custom",
schedule=None,
start_date=pendulum.datetime(2025, 1, 1, tz="Asia/Seoul"),
catchup=False,
tags=["example", "hook"],
) as dag:
def bulk_load_postgres(postgres_conn_id: str, table: str, filename: str, **kwargs):
custom_postgres_hook = CustomPostgresHook(postgres_conn_id=postgres_conn_id)
custom_postgres_hook.bulk_load(table=table, filename=filename, if_exists="replace", sep=",", with_header=True)
bulk_load_postgres = PythonOperator(
task_id="bulk_load_postgres",
python_callable=bulk_load_postgres,
op_kwargs={"postgres_conn_id": "conn-db-postgres-custom",
"table":"nshopping.search2",
"filename":"/opt/airflow/files/naverSearch/{{data_interval_end.in_timezone(\"Asia/Seoul\") | ds_nodash }}/shop.csv"}
)DAG 실행
- 실행 로그 중에서
CustomPostgresHook이 생성한 SQL문을 확인 가능 if_exists="replace"파라미터를 추가했기 때문에, 중간에TRUNCATE TABLE구문이 추가- 따라서, 여러 번 DAG을 실행해도 매번 테이블이 초기화되어 중복된 데이터가 업로드되지 않음
[2025-06-11, 01:24:16] INFO - DAG bundles loaded: dags-folder: source="airflow.dag_processing.bundles.manager.DagBundlesManager"
[2025-06-11, 01:24:16] INFO - Filling up the DagBag from /opt/airflow/dags/python_with_postgres_custom.py: source="airflow.models.dagbag.DagBag"
[2025-06-11, 01:24:16] INFO - Running copy expert: CREATE TABLE IF NOT EXISTS nshopping.search2(rank int4, title text, link text, image text, lprice int4, hprice int4, mallName text, productId text, productType int4, brand text, maker text, category1 text, category2 text, category3 int4, category4 int4);TRUNCATE TABLE nshopping.search2;COPY nshopping.search2 FROM STDIN DELIMITER ',' CSV HEADER;, filename: /opt/airflow/files/naverSearch/20250611/shop.csv: source="hooks.postgres.CustomPostgresHook"
[2025-06-11, 01:24:16] INFO - Secrets backends loaded for worker: count=1: backend_classes=["EnvironmentVariablesBackend"]: source="supervisor"
[2025-06-11, 01:24:16] INFO - Connection Retrieved 'conn-db-postgres-custom': source="airflow.hooks.base"
[2025-06-11, 01:24:16] INFO - Done. Returned value was: None: source="airflow.task.operators.airflow.providers.standard.operators.python.PythonOperator"테이블 조회
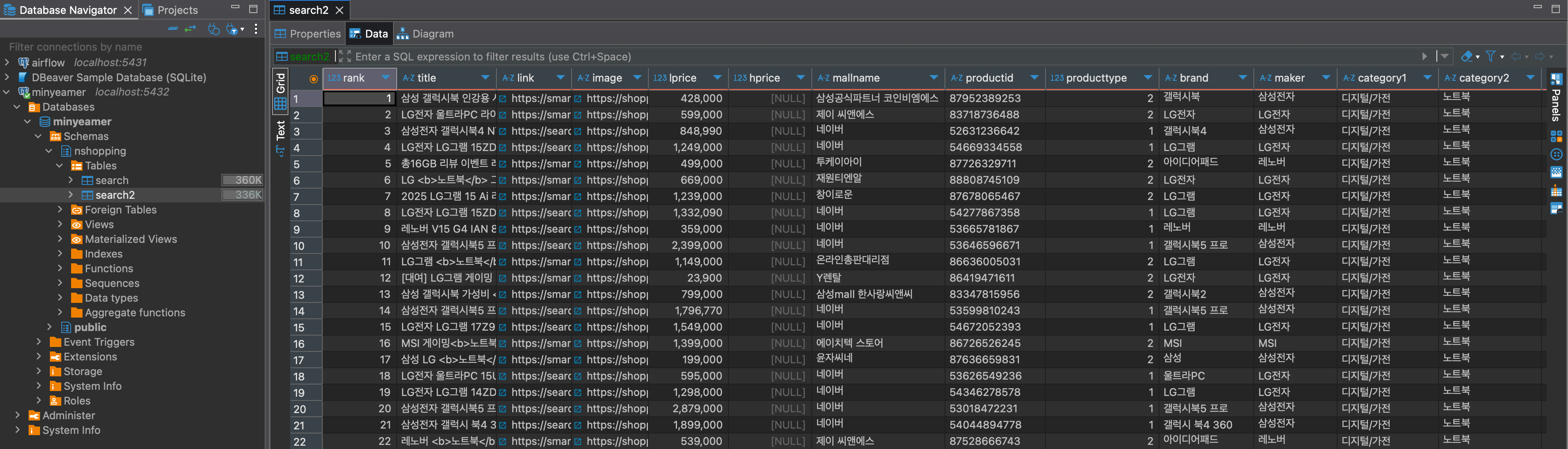
- DBeaver에서
nshopping.search2테이블이 생성되었고, 의도대로 정수형 열을 추측하여 데이터 타입을 구분해서 지정된 것을 확인
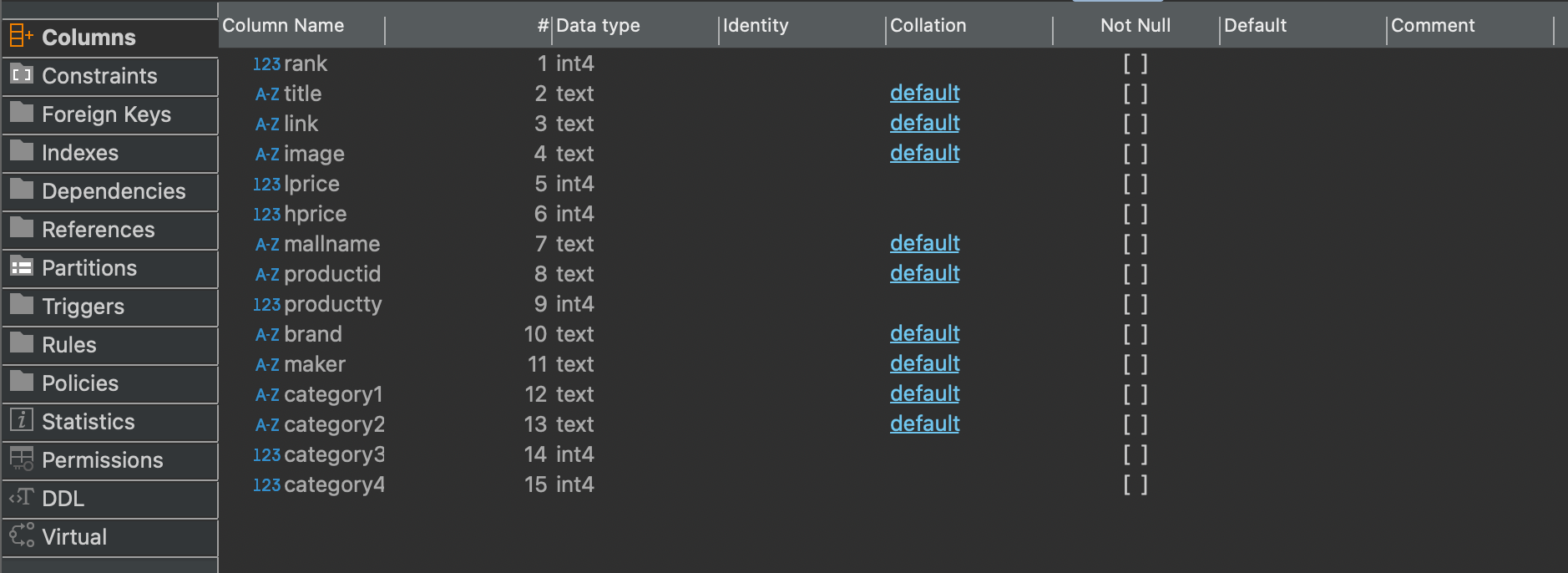
- 테이블 내용을 보면, 기존의 문제였던 헤더가 1행으로 들어갔던게 해결됨이 확인
- 또한, 추측한 데이터 타입에 맞춰서 값이 정상적으로 들어갔음을 확인
- 참조한 강의에서는 CSV 파일을
pd.DataFrame객체로 읽고, SQLAlchemy의 엔진을 사용해to_sql()기능으로 PostgreSQL 테이블에 데이터를 적재하는 방식으로 접근- 개인적으로는
PostgresHook을 이해하고자,PostgresHook의 원형을 최대한 유지하면서 필요한 기능만 추가하기 위해 외부 라이브러리의 사용을 제한함
- 개인적으로는

데이터의 모든 것을 추구합니다.