
Spark Structure
정형화 API에 대해 알아보기에 앞서, 정형적 모델 이전의 RDD 프로그래밍 API 모델을 확인해본다.
RDD
RDD는 Spark 1.x 버전에 있던 저수준의 DSL을 의미하고, 스파크에서 가장 기본적인 추상적인 부분이다. RDD에는 세 가지의 핵심으로 특성이 있다.
-
의존성
어떤 입력을 필요로 하고 RDD가 어떻게 만들어지는지 Spark에게 가르쳐 주는 의존성이 필요하다. -
파티션
Executor들에 작업을 분산해 파티션별로 병렬 연산할 수 있는 능력을 부여한다. 지역성 정보를 사용하여 각 Executor가 가까이 있는 Executor에게 우선적으로 작업을 보낸다. -
연산 함수
파티션에 저장되는 데이터를Iterator[T]형태로 만들어준다. 하지만,Iterator[T]데이터 타입이 파이썬 RDD에서 기본 객체로만 인식이 가능해 불투명했다. Spark가 함수에서 연산이나 표현식을 검사하지 못해 객체를 바이트 뭉치로 직렬화해 쓰는 것밖에 못했다. 이로 인해 연산 순서를 재정렬해 효과적인 질의 계획으로 바꾸기가 어려웠다.
Spark DSL
Spark 2.x는 RDD의 한계를 극복하기 위해 고수준의 DSL을 도입했다. Spark DSL은 다음과 같은 네 가지 특징이 있다.
-
도메인 특화 언어
Spark DSL은 분산 데이터 처리와 분석에 최적화된 명령어와 함수를 제공하여, 대규모 데이터셋에 대한 복잡한 연산을 간결하게 표현할 수 있다. -
다중 언어 지원
Scala 언어 뿐 아니라, Java, Python, R 등 다양한 언어에서 Spark DSL의 기능을 사용할 수 있게 지원한다. -
함수형 프로그래밍 지원
람다 함수, 고차 함수 등 함수형 프로그래밍 기법을 활용하여 Transformation 및 Action을 간결하게 구현할 수 있다. -
SQL 통합
Spark SQ DSL을 통해 SQL 쿼리와 유사한 구문으로 DataFrame 및 Dataset을 조작할 수 있다.
고수준 DSL을 통한 Spark 구조를 갖추면서 더 나은 성능과 공간 효율성 등 많은 이득을 얻을 수 있었다. DataFrame API나 Dataset API를 다루면서 표현성, 단순성, 구성 용이성, 통일성 등의 장점도 가지게 되었다.
이름별로 모든 나이들을 모아서 그룹화하고, 나이의 평균을 구하는 예제를 저수준의 RDD API로 구현한다고 하면 다음과 같을 수 있다.
dataRDD = sc.parallelize([
("Brooke", 20), ("Denny", 31), ("Jules", 30), ("TD", 35), ("Brooke", 25)])
agesRDD = (dataRDD
.map(lambda x: (x[0], (x[1], 1)))
.reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
.map(lambda x: x[0], x[1][0]/x[1][1]))해당 코드를 Spark에게 쿼리를 계산하는 과정을 직접적으로 지시하여 의도가 전달되지 않는다. 동일한 질의를 Python의 고수준 DSL 연산자들과 DataFrame API를 사용하면 다음과 같다.
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg
# SparkSession 객체 생성
data_df = spark.createDataFrame(
[("Brooke", 20), ("Denny", 31), ("Jules", 30), ("TD", 35), ("Brooke", 25)])
avg_df = data_df.groupBy("name").agg(avg("age"))
avg_df.show()고수준 DSL은 표현력이 높고 저수준 DSL보다 간단하다. Spark는 groupBy, avg 등의 연산자들을 통해 사용자의 의도를 이해하고 효과적인 실행을 위해 연산자들을 최적화하거나 적절하게 재배열할 수 있다.
단순히 간단하기만 할 뿐 아니라 고수준 DSL은 언어 간에 일관성을 갖고 있다. 예를 들어 이름별로 나이의 평균을 집계하는 코드는 아래와 같다. 겉보기에도 똑같고 실제로 하는 일도 동일하다.
# 파이썬 예제
avg_df = data_df.groupBy("name").agg(avg("age"))// 스칼라 예제
val avgDf = dataDf.groupBy("name").agg(avg("age"))DataFrame API
pandas의 DataFrame에 영향을 받은 Spark DataFrame은 칼럼과 스키마를 가진 분산된 테이블처럼 동작하며, 각 칼럼은 정수, 문자열, 배열, 날짜 등 특정한 데이터 타입을 가질 수 있다.
기본 데이터 타입
데이터 타입은 Spark Application에서 선언하거나, 스키마에서 정의할 수 있다.
먼저, Scala와 Python의 기본적인 데이터 타입은 아래와 같다.
| 데이터 타입 | 스칼라에서 할당되는 값 | 파이썬에서 할당되는 값 |
|---|---|---|
| ByteType | Byte | int |
| ShortType | Short | int |
| IntegerType | Integer | int |
| LongType | Long | int |
| FloatType | Float | float |
| DoubleType | Double | float |
| StringType | String | str |
| BooleanType | Boolean | bool |
| DecimalType | java.math.BigDecimal | decimal.Decimal |
정형화 타입과 복합 타입
복합 데이터 분석을 위해서는 기본적인 데이터 타입을 사용하지 않는다. 대상 데이터는 맵, 배열, 구조체 등 자체적 구조를 갖고 있기 때문에, 이를 다루기 위한 타입을 지원한다.
| 데이터 타입 | 스칼라에서 할당되는 값 | 파이썬에서 할당되는 값 |
|---|---|---|
| BinaryType | Array[Byte] | bytearray |
| TimestampType | java.sqlTimestamp | datetime.datetime |
| DateType | java.sql.Date | datetime.date |
| ArrayType | scala.collection.Seq | list, tuple, array 등 |
| MapType | scala.collection.Map | dict |
| StructType | org.apache.spark.sql.Row | list 또는 tuple |
| StructField | 해당 필드와 맞는 값의 타입 | 해당 필드와 맞는 값의 타입 |
Schema
스키마는 DataFrame의 칼럼명과 데이터 타입을 정의한 것이다. 보통 외부 데이터 소스에서 구조화된 데이터를 읽어 들일 때 사용한다. 미리 스키마를 정의할 경우 두 가지 장점이 있다.
- Spark가 스키마를 추측하기 위해 파일을 읽어들이는 과정을 방지한다. 파일이 큰 경우, 비용과 시간을 절약할 수 있다.
- 데이터가 스키마와 맞지 않는 경우, 조기에 발견할 수 있다.
스키마 정의
스키마를 정의하는 방법은 두 가지가 있다.
- 프로그래밍 스타일로 정의하는 것
// 스칼라 예제
import org.apache.spark.sql.types._
val schema = StructType(Array(
StructField("author", StringType, false),
StructField("title", StringType, false),
StructField("pages", IntegerType, false)))# 파이썬 예제
from pyspark.sql.types import *
schema = StructType([
StructField("author", StringType(), False),
StructField("title", StringType(), False),
StructField("pages", IntegerType(), False)])- DDL(Data Definition Language)을 사용하는 것
schema = "author STRING, title, STRING, pages INT"스키마 활용 (Python)
databricks/LearningSparkV2/chapter3 에서 스키마 활용 예제를 가져온다.
# src/example_schema.py
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# 프로그래밍 스타일로 스키마를 정의한다.
schema = StructType([
StructField("Id", IntegerType(), False),
StructField("First", StringType(), False),
StructField("Last", StringType(), False),
StructField("Url", StringType(), False),
StructField("Published", StringType(), False),
StructField("Hits", IntegerType(), False),
StructField("Campaigns", ArrayType(StringType()), False)])
# DDL을 사용해서 스키마를 정의할 수도 있다.
# schema = "'Id' INT, 'First', STRING, 'Last' STRING, 'Url' STRING, " \
# "'Published' STRING, 'Hits' INT, 'Campaigns' ARRAY<STRING>"
# 예제 데이터를 생성한다.
data = [
[1, "Jules", "Damji", "https://tinyurl.1", "1/4/2016", 4535, ["twitter", "LinkedIn"]],
[2, "Brooke","Wenig","https://tinyurl.2", "5/5/2018", 8908, ["twitter", "LinkedIn"]],
[3, "Denny", "Lee", "https://tinyurl.3","6/7/2019",7659, ["web", "twitter", "FB", "LinkedIn"]],
[4, "Tathagata", "Das","https://tinyurl.4", "5/12/2018", 10568, ["twitter", "FB"]],
[5, "Matei","Zaharia", "https://tinyurl.5", "5/14/2014", 40578, ["web", "twitter", "FB", "LinkedIn"]],
[6, "Reynold", "Xin", "https://tinyurl.6", "3/2/2015", 25568, ["twitter", "LinkedIn"]]]
if __name__ == "__main__":
spark = (SparkSession
.builder
.appName("Example-3_6")
.getOrCreate())
# 위에서 정의한 스키마로 DataFrame을 생성하고 상위 행을 출력한다.
blogs_df = spark.createDataFrame(data, schema)
blogs_df.show()
# DataFrame 처리에 사용된 스키마를 출력한다.
print(blogs_df.printSchema())
spark.stop()예제 데이터에 대해 프로그래밍 스타일과 DDL을 사용하는, 두 가지 스타일로 스키마를 정의할 수 있다. DataFrame 생성 시 스키마를 전달하고, printSchema() 를 실행하여 어떤 스키마가 적용되었는지 출력해 볼 수 있다.
spark-submit 에 예제 파일을 전달하면 아래와 같은 결과를 확인할 수 있다.
(spark) % spark-submit src/example_schema.py
+---+---------+-------+-----------------+---------+-----+--------------------+
| Id| First| Last| Url|Published| Hits| Campaigns|
+---+---------+-------+-----------------+---------+-----+--------------------+
| 1| Jules| Damji|https://tinyurl.1| 1/4/2016| 4535| [twitter, LinkedIn]|
| 2| Brooke| Wenig|https://tinyurl.2| 5/5/2018| 8908| [twitter, LinkedIn]|
| 3| Denny| Lee|https://tinyurl.3| 6/7/2019| 7659|[web, twitter, FB...|
| 4|Tathagata| Das|https://tinyurl.4|5/12/2018|10568| [twitter, FB]|
| 5| Matei|Zaharia|https://tinyurl.5|5/14/2014|40578|[web, twitter, FB...|
| 6| Reynold| Xin|https://tinyurl.6| 3/2/2015|25568| [twitter, LinkedIn]|
+---+---------+-------+-----------------+---------+-----+--------------------+
root
|-- Id: integer (nullable = false)
|-- First: string (nullable = false)
|-- Last: string (nullable = false)
|-- Url: string (nullable = false)
|-- Published: string (nullable = false)
|-- Hits: integer (nullable = false)
|-- Campaigns: array (nullable = false)
| |-- element: string (containsNull = true)DataFrame에 할당된 스키마를 다른 곳에서 사용하고 싶다면, blogs_df.schema 와 같이 호출하여 스키마 객체를 반환할 수 있다. 스키마 객체는 스키마를 정의할 때 사용했던 것과 동일한 pyspark.sql.types.StructType 타입이다.
Scala를 사용하는 경우에도 Python과 동일하게 정의한 스키마를 JSON 파일을 읽는데 적용한다면 아래와 같이 표현할 수 있다.
// 스칼라 예제
val blogsDF = spark.read.schema(schema).json(jsonFile)Column
칼럼은 pandas의 DataFrame과 유사하게 어떤 특정한 타입의 필드를 나타내는 개념이다. RDBMS를 다루는 것처럼 관계형 표현이나 계산식 형태의 표현식으로 칼럼 단위의 값들에 연산을 수행할 수 있다.
칼럼명에 대해 expr("columnName * 5") 같은 단순한 표현식으로 연산을 수행할 수 있다. 파이썬에서 expr() 은 pyspark.sql.functions 패키지에서 가져올 수 있다.
표현식 활용 (Python)
스키마 활용 예제에서 만든 blogs_df 객체를 사용한다.
# src/example_schema.py
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
if __name__ == "__main__":
# SparkSession 및 blogs_df 객체 생성
# 표현식을 사용해 값을 계산하고 결과를 출력한다. 모두 동일한 결과를 보여준다.
blogs_df.select(expr("Hits") * 2).show(2)
blogs_df.select(col("Hits") * 2).show(2)
blogs_df.select(expr("Hits * 2")).show(2)
# 블로그 우수 방문자를 계산하고 결과를 출력한다.
blogs_df.withColumn("Big Hitters", (expr("Hits > 10000"))).show()spark-submit 에 예제 파일을 전달하면 아래와 같은 결과를 확인할 수 있다.
(spark) % spark-submit src/example_schema.py
+----------+
|(Hits * 2)|
+----------+
| 9070|
| 17816|
+----------+
only showing top 2 rows
+---+---------+-------+-----------------+---------+-----+--------------------+-----------+
| Id| First| Last| Url|Published| Hits| Campaigns|Big Hitters|
+---+---------+-------+-----------------+---------+-----+--------------------+-----------+
| 1| Jules| Damji|https://tinyurl.1| 1/4/2016| 4535| [twitter, LinkedIn]| false|
| 2| Brooke| Wenig|https://tinyurl.2| 5/5/2018| 8908| [twitter, LinkedIn]| false|
| 3| Denny| Lee|https://tinyurl.3| 6/7/2019| 7659|[web, twitter, FB...| false|
| 4|Tathagata| Das|https://tinyurl.4|5/12/2018|10568| [twitter, FB]| true|
| 5| Matei|Zaharia|https://tinyurl.5|5/14/2014|40578|[web, twitter, FB...| true|
| 6| Reynold| Xin|https://tinyurl.6| 3/2/2015|25568| [twitter, LinkedIn]| true|
+---+---------+-------+-----------------+---------+-----+--------------------+-----------+첫 번째 표현식으로 계산한 결과는 모두 동일하여 하나만 출력했다. expr() 또는 col() 표현식으로 칼럼 연산을 수행할 수 있다.
withColumn() 을 호출하면 새로운 칼럼을 추가할 수 있다. 기존의 "Hits" 칼럼에 표현식을 사용해 블로그 우수 방문자를 분류하고, "Big Hitters" 라는 새로운 칼럼을 붙여서 출력했다.
Scala에서는 col() 대신에 칼럼명 앞에 $ 를 붙여서 Column 타입으로 변환할 수도 있다.
// "Id" 칼럼값에 따라 역순으로 정렬한다.
blogsDF.sort(col(.desc).show()
blogsDF.sort($"Id".desc).show()Row
Spark에서 하나의 행은 하나 이상의 칼럼을 갖고 있는 Row 객체로 표현된다. Row 객체에 속하는 칼럼들은 동일한 타입일 수도 있고 다른 타입일 수도 있다. Row는 순서가 있는 필드 집합 객체이므로 0부터 시작하는 인덱스로 접근한다.
# 파이썬 예제
from pyspark.sql import Row
blog_row = Row(6, "Reynold", "Xin", "https://tinyurl.6", 255568, "3/2/2015", ["twitter", "LinedIn"])
# 인덱스로 개별 값에 접근한다.
blog_row[1]
'Reynold'Row 객체들을 DataFrame으로 만들 수 있다.
# 파이썬 예제
rows = [Row("Matei Zaharia", "CA"), Row("Reynold Xin", "CA")]
authors_df = spark.createDataFrame(rows, ["Authors", "State"])
authors_df.show()DataFrame 작업
읽기/쓰기
데이터 소스에서 DataFrame으로 로드하기 위해 DataFrameReader 를 사용할 수 있다. JSON, CSV, Parquet, 텍스트, Avro, ORC 같은 다양한 포맷의 데이터 소스를 지원한다. 반대로 특정 포맷으로 DataFrame을 내보낼 때는 DataFrameWriter 를 사용할 수 있다.
Python과 Scala에서 spark.read.csv() 함수로 CSV 파일을 읽을 수 있다.
# 파이썬 예제
sf_fire_file = "data/sf-fire-calls.csv"
fire_df = spark.read.csv(sf_fire_file, header=True, schema=fire_schema)// 스칼라 예제
val sfFireFile = "data/sf-fire-calls.csv"
val fireDF = spark.read.schema(fireSchema).option("header", "true").csv(sfFireFile)DataFrame을 외부 데이터 소스에 내보내려면 DataFrame 객체가 가진 write() 메서드를 사용할 수 있다. 기본 포맷으로 인기있는 포맷은 칼럼 지향적인 Parquet 포맷이다. Parquet에는 스키마가 메타데이터에 들어있어 수동으로 스키마를 적용할 필요가 없다.
# 파이썬 예제
fire_df.write.format("parquet").save(parquet_path)// 스칼라 예제
fireDF.write.format("parquet").save(parquetPath)프로젝션/필터
프로젝션은 필터를 이용해 특정 관계 상태와 매치되는 행들만 반환하는 방법이다. 프로젝션은 select(), 필터는 filter() 또는 where() 메서드로 표현된다.
# 파이썬 예제
few_fire_df = (fire_df
.select("IncidentNumber", "AvailableDtTm", "CallType")
.where(col("CallType") != "Medical Incident"))
few_fire_df.show(5, truncate=False)칼럼 변경
칼럼의 이름을 변경하거나 추가 또는 삭제하는 경우가 있다.
컬럼명을 변경할 때는 withColumnRenamed() 함수를 사용할 수 있다. 아래 예제는 "Delay" 칼럼의 명칭을 "ResponseDelayedinMins" 라고 변경한다.
# 파이썬 예제
new_fire_df = fire_df.withColumnRenamed("Delay", "ResponseDelayedinMins")
(new_fire_df
.select("ResponseDelayedinMins")
.where(col("ResponseDelayedinMins") > 5)
.show(5, False))기존 칼럼을 가공해 새로운 칼럼을 만들 때는 withColumn() 메서드를 사용할 수 있다. 이때, spark.sql.functions 패키지에 있는 to_timestamp() 또는 to_date() 같은 함수들을 같이 사용할 수 있다. 가공된 칼럼을 추가한 후 필요하지 않은 칼럼을 제거하려면 drop() 메서드를 사용할 수 있다.
# 파이썬 예제
fire_ts_df = (new_fire_df
.withColumn("IncidentDate", to_timestamp(col("CallDate"), "MM/dd/yyyy")).drop("CallDate")
.withColumn("OnWatchDate", to_timestamp(col("WatchDate"), "MM/dd/yyyy")).drop("WatchDate")
.withColumn("AvailableDtTs", to_timestamp(col("AvailableDtTm"), "MM/dd/yyyy hh:mm:ss")).drop("AvailableDtTm"))
(fire_ts_df
.select("IncidentDate", "OnWatchDate", "AvailableDtTs")
.show(5, False))집계 연산
groupBy(), orderBy(), count() 와 같은 Transformation 또는 Action을 사용하여 칼럼명을 가지고 집계할 수 있다. 아래 예제는 "CallType" 칼럼을 기준으로 행 개수를 세는 연산을 표현한다. 내림차순으로 정렬하여 가장 일반적인 신고 타입(CallType)을 확인할 수 있다.
# 파이썬 예제
(fire_ts_df
.select("CallType")
.where(col("CallType").isNotNull())
.groupBy("CallType")
.count()
.orderBy("count", ascending=False)
.show(n=10, truncate=False))집계 함수로는 min(), max(), sum(), avg() 등의 통계 함수들을 지원한다.
# 파이썬 예제
import pyspark.sql.functions as F
(fire_ts_df
.select(F.sum("NumAlarms"), F.avg("ResponseDelayedinMins"),
F.min("ResponseDelayedinMins"), F.max("ResponseDelayedinMins"))
.show())Dataset API
Dataset는 정적 타입 API와 동적 타입 API의 두 가지 특성을 모두 가진다.
Dataset
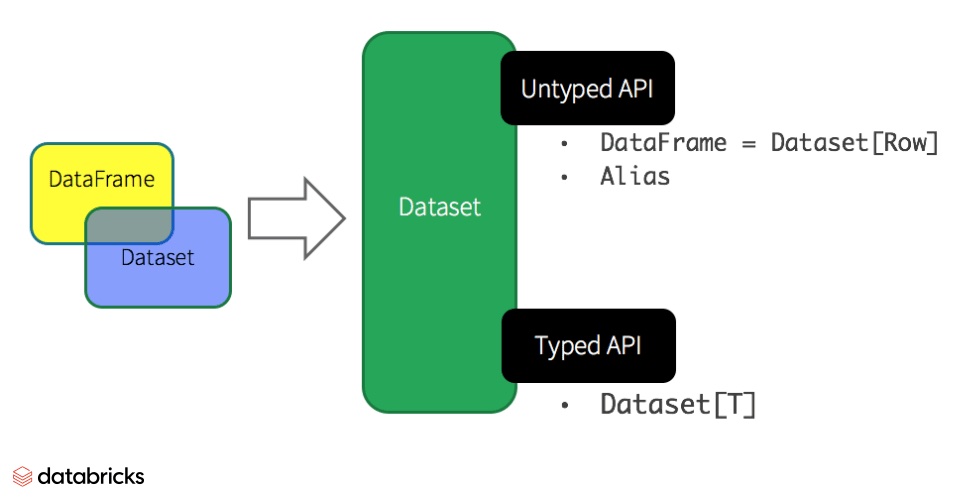
DataFrame은 Dataset[Row] 로 표현할 수 있다. Row는 서로 다른 타입의 값을 저장할 수 있는 JVM 객체다. 반면에 Dataset는 엄격하게 타입이 정해진 JVM 객체의 집합으로, Java의 클래스와 유사하다.
Dataset는 Java와 Scala에서만 사용할 수 있고, Python과 R에서는 DataFrame만 사용할 수 있다. 이것은 Python과 R이 컴파일 시 타입의 안전을 보장하는 언어가 아니기 때문이다. 반대로 Java는 컴파일 시점에 타입 안정성을 제공하기 때문에 Dataset만 사용할 수 있다. Scala는 DataFrame을 Dataset[Row] 로 표현하며, Dataset[T] 도 같이 사용할 수 있다.
Case Class
DataFrame에서 스키마로 데이터 타입을 정의한느 것처럼, Scala에서 Dataset를 만들 때 스키마를 지정하기 위해 케이스 클래스를 사용할 수 있다. Java에서는 JavaBean 클래스를 쓸 수 있다.
예제로, IoT 디바이스에서 JSON 파일을 읽어 들일 때 케이스 클래스를 아래와 같이 정의한다.
// 스칼라 예제
case class DeviceIoTData (
battery_level: Long,
c02_level: Long,
cca2: String,
cca3: String,
cn: String,
device_id: Long,
device_name: String,
humidity: Long,
ip: String,
latitude: Double,
longitude: Double,
scale: String,
temp: Long,
timestamp: Long
)
val ds = spark.read.json("iot_devices.json").as[DeviceIoTData]Dataset는 DataFrame과 같은 연산이 가능하다. 예제로, filter() 에 함수를 인자로 전달하는 질의는 아래와 같다.
// 스칼라 예제
val filterTempDS = ds.filter(d => d.temp > 30 && d.humidity > 70)DataFrame vs Dataset
DataFrame과 Dataset을 사용 중 오류가 발생하는 시점을 정리하면 아래 표와 같다. Dataset가 DataFrame과 다른점은 컴파일 시점에 엄격한 타입 체크를 한다는 것이다. 반대로, SQL과 유사한 질의를 쓰는 관계형 변환을 필요로 한다면 DataFrame을 사용한다.
| SQL | DataFrame | Dataset | |
|---|---|---|---|
| 문법 오류 | 실행 시점 | 컴파일 시점 | 컴파일 시점 |
| 분석 오류 | 실행 시점 | 실행 시점 | 컴파일 시점 |
Spark SQL
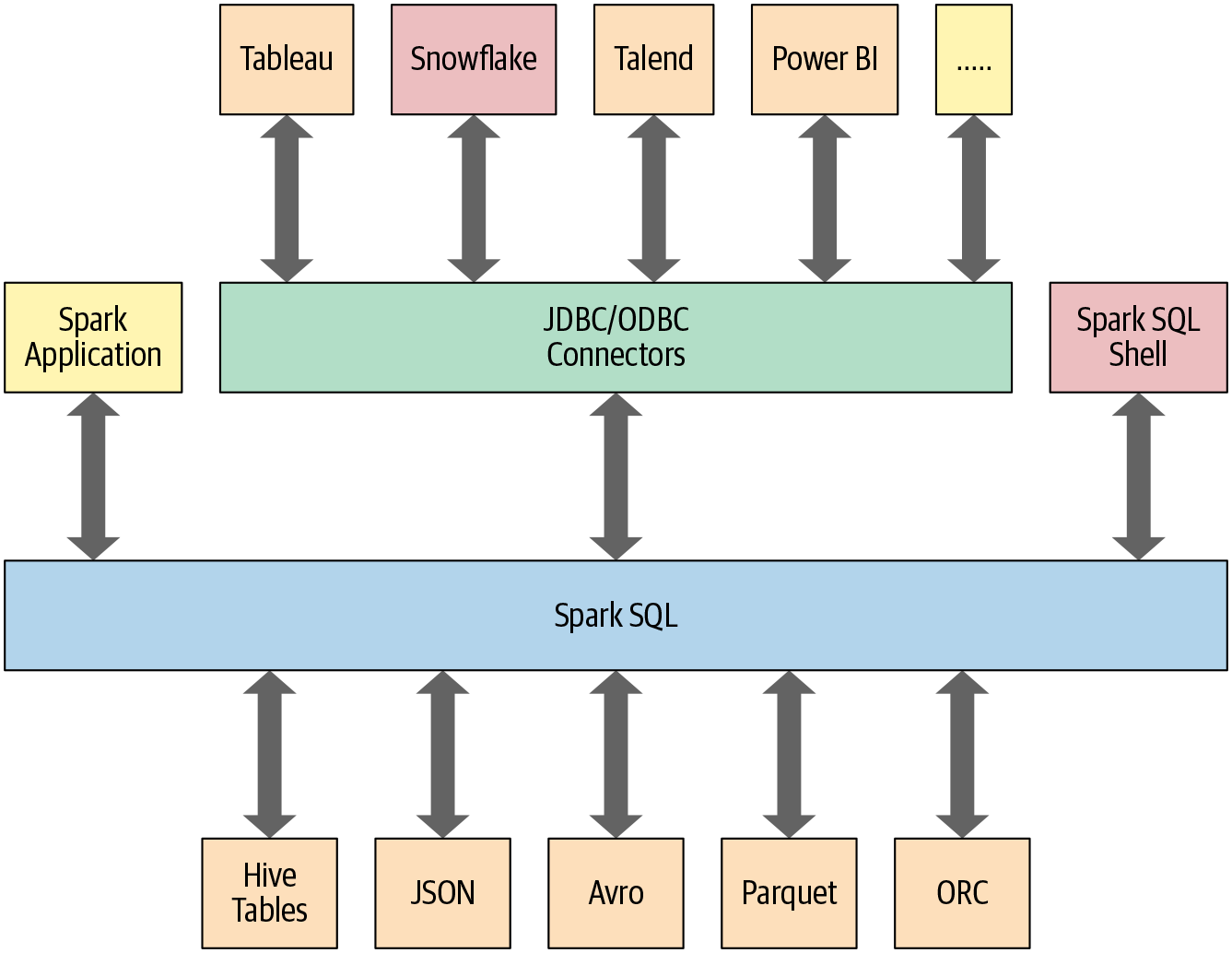
Spark SQL은 고수준 정형화 기능들이 구축되도록 하는 방대한 엔진으로 진화해 왔다. Spark SQL 엔진은 다음과 같은 일을 한다.
- 스파크 컴포넌트들을 통합하고 DataFrame/Dataset 관련 작업을 단순화할 수 있도록 추상화를 한다.
- 정형화된 파일 포맷(JSON, CSV 등)을 읽고 쓰며 데이터를 임시 테이블로 변환한다.
- 빠른 데이터 탐색을 위한 대화형 Spark SQL 쉘을 제공한다.
- JDBC/ODBC 커넥터를 통해 외부의 도구들과 연결할 수 있는 중간 역할을 한다.
- JVM을 위한 최적화된 코드를 생성한다.
Catalyst Optimizer
Spark SQL 엔진의 핵심은 Catalyst Optimizer다. Catalyst Optimizer는 두 가지 목적으로 설계되었다.
- Spark SQL에 최적화 기법을 쉽게 추가한다.
- 개발자가 최적화 프로그램을 확장할 수 있도록 한다.
예시로, 데이터 소스별 규칙을 추가하거나 새로운 데이터 유형을 지원하는 것 등이 있다.
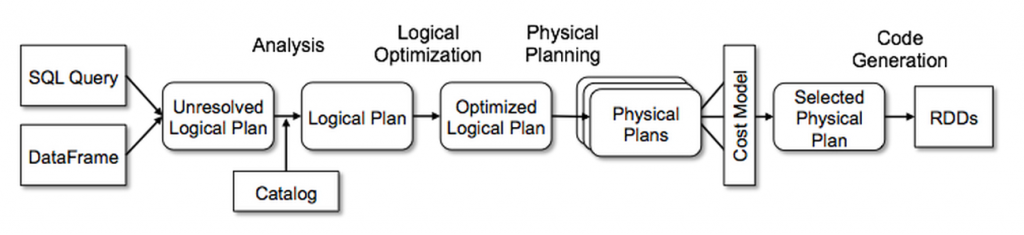
Catalyst Optimizer는 연산 쿼리를 받아 실행 계획으로 변환한다. 그 과정은 아래 그림과 같이 4단계의 과정을 거친다.
-
분석
제공된 코드가 유효하고 오류가 없는지 확인한다. 칼럼, 데이터 타입, 함수, 테이블, 데이터베이스 이름 목록을 갖고 있는 Catalog 객체를 참조한다. 분석 단계를 성공적으로 통과하면 Spark에서 이해하고 해결할 수 있는 요소만이 포함되어 있다는 의미를 가진다. -
논리적 최적화
표준적인 규칙을 기반으로 최적화 접근 방식을 적용하여 효율성을 향상시킨다. 최적화를 위한 여러 계획들을 수립하는데, 예를 들면 조건절 하부 배치, 칼럼 걸러내기, 부울 표현식 단순화 등이 포함된다. 논리 계획은 물리 계획 수립의 입력 데이터가 된다. -
물리 계획 수립
논리 계획을 바탕으로 대응되는 물리적 연산자를 사용해 최적화된 물리 계획을 생성한다. CPU, 메모리, I/O 활용을 포함한 컴퓨팅 리소스 비용을 기반으로 실행 전략을 평가한다. 리소스 가용성을 기반으로 가장 비용이 적게 드는 계획을 선택한다. -
코드 생성
물리 계획을 Java 바이트 코드로 변환한다. 최신 컴파일러 기술을 활용해 최적화된 바이트 코드를 생성한다. Spark가 JIT(Just-In-Time) 컴파일러처럼 작동하여 런타임 성능을 최적화하고 실행 속도를 크게 향상시킨다.
References
- https://www.oreilly.com/library/view/learning-spark-2nd/9781492050032/
- https://itwiki.kr/w/아파치_스파크_DSL
- https://github.com/databricks/LearningSparkV2
- https://www.databricks.com/spark/getting-started-with-apache-spark/datasets
- https://www.databricks.com/glossary/catalyst-optimizer
- https://blog.det.life/apache-spark-sql-engine-and-query-planning-37cafb2b98f6
