
Spark Application
Spark Application은 Driver Process 하나와 일련의 일련의 Executors로 구성된다.
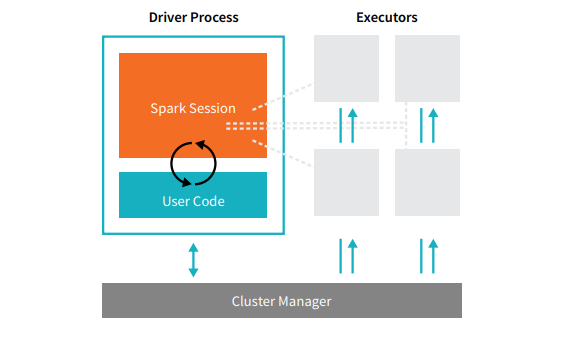
Driver Process
Driver Process는 main() 함수를 실행하고 클러스터 내 노드에서 세 가지 작업을 담당한다.
- Spark Application 관련 정보를 유지한다.
- 사용자의 프로그램이나 입력에 대응한다.
- Executor 작업을 분석, 배포, 예약한다.
Executor
Executor는 Driver가 할당한 작업을 실제로 실행하는 역할을 하는데, 두 가지 작업을 담당한다.
- Driver가 할당한 Task를 실행한다.
- Task의 상태와 결과를 Driver 노드에 보고한다.
Cluster Manager
실물 시스템을 제어하고 Spark Application에 리소스를 할당하는 작업은 Cluster Manager가 맡는다. Spark Application의 실행 과정에서 Cluster Manager는 Application이 실행되는 물리적인 머신을 관리한다. Spark Application은 클러스터에서 독립적인 프로세스로 실행되며, SparkContext 객체에 의해 조정된다.
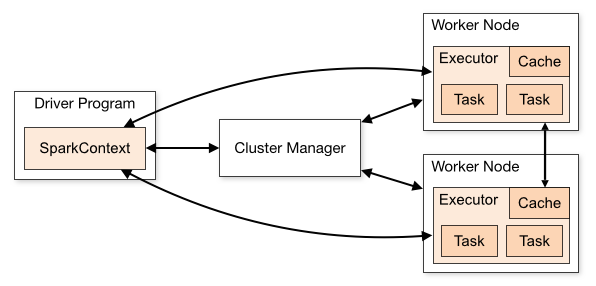
SparkContext는 여러 유형의 Cluster Manager(Standalone, YARN, Kubernetes)에 연결될 수 있으며, Application 간에 리소스를 할당한다. Spark가 연결되어 클러스터의 노드에서 Executor가 확보되면, SparkContext에 전달된 Application 코드가 Executor에게 전달된다.

Job
Spark Driver는 Spark Application을 하나 이상의 Spark Job으로 변환한다. 각 Job은 DAG로 변환되며, DAG 그래프에서 각각의 노드는 하나 이상의 Spark Stage에 해당한다.
Stage
어떤 작업이 연속적으로 또는 병렬적으로 수행되는지에 맞춰 Stage에 해당하는 DAG 노드가 생성된다. Spark 연산은 하나의 Stage 안에서 실행되지 않고 여러 Stage로 나뉘어 실행된다.
Task
각 Stage는 최소 실행 단위이며 Executor들 위에서 실행되는 Spark Task들로 이루어진다. 각 Task는 개별적인 CPU 코어에 할당되어 개별적인 파티션을 갖고 작업하기 때문에, 철저하게 병렬 처리가 이루어진다.
RDD(Resilient Distributed Data)
RDD는 탄력적인 분산 데이터셋이란 의미로, 분산 데이터를 병렬로 처리하고 장애가 발생할 경우 스스로 복구될 수 있는 내성을 가지고 있다. RDD는 Spark에서 정의한 분산 데이터 모델로, 여러 서버에 나누어 저장되어 각 서버에서 저장된 데이터를 동시에 병렬로 처리할 수 있다.
RDD 특징
RDD는 5가지 특징을 가지고 있다.
-
Distributed Collection
데이터는 클러스터에 흩어져 있지만 하나의 파일인 것처럼 사용이 가능한다. 즉, 여러 군데의 데이터를 하나의 객체로 사용할 수 있다. -
Resilient & Immutable
데이터는 탄력적이고 불변하는 성질이 있다. RDD의 변환 과정은 DAG로 그릴 수 있기 때문에 문제가 생길 경우 쉽게 이전의 RDD로 돌아갈 수 있다. 연산 중 문제가 생겨도 다시 복원해서 연산하면 되기 때문에 탄력적인 성질을 가진다고 볼 수 있다. 또한, 여러 노드 중 하나의 노드에서 장애가 발생해도 복원이 가능하기 때문에 불변하다는 성질을 가진다고도 볼 수 있다. -
Type-Safe
RDD는 컴파일 시 타입을 판별할 수 있다. Integer RDD, String RDD, Double RDD 등으로 미리 판단할 수 있기 때문에 문제를 일찍 발견할 수 있다. -
Structured & Unstructured Data
정형 데이터인 테이블, RDB, DataFrame과 비정형 데이터인 텍스트, 로그, 자연어 등을 모두 담을 수 있다. -
Lazy Evaluation
분산 데이터의 Spark 연산은 Transformation과 Action으로 구분된다. Action을 할 때까지 Transformation을 실행하지 않는다. Action을 하게 되면 Transformation을 실행하는 게으른 연산 방식을 가진다.
Transformation
Transformation은 불변성의 특징을 가진 원본 데이터를 수정하지 않고 하나의 Spark DataFrame을 새로운 DataFrame으로 변형(Transform)한다. select() 나 filter() 같은 연산은 원본 DataFrame을 수정하지 않는다.
Transformation은 즉시 계산되지 않고 Lineage라 불리는 형태로 기록된다. 기록된 Lineage는 더 효율적으로 연산할 수 있도록 Transformation들끼리 재배열하거나 합치도록 최적화된다. Lazy Evaluation은 Action이 실행되는 시점이나 데이터에 실제 접근하는 시점까지 실제 실행을 미루는 전략이다.
Lazy Evaluation이 일련의 Transformation들을 최적화한다면, Lineage는 데이터 불변성 및 장애에 대한 내구성을 제공한다. Lineage에는 Transformation들이 기록되어 있고 실행 전까지 DataFrame이 변하지 않기 때문에, 단순히 기록된 Lineage를 재실행하는 것만으로 원래 상태를 다시 만들어낼 수 있다.
Transformation은 Narrow Transformation과 Wide Transformation으로 구분된다.
Narrow Transformation
Narrow Transformation은 하나의 입력 파티션을 연산하여 하나의 출력 파티션을 내놓는 경우다. 입력 파티션에 대한 연산이 독립적으로 이루어지며, 연산의 결과인 출력 파티션은 입력 파티션의 데이터에만 의존한다. 즉, 다른 파티션의 데이터를 참조할 필요가 없다는 것을 의미한다. filter() 와 contains() 등의 연산이 여기에 해당된다.
Narrow Transformation은 실행 비용이 상대적으로 낮고, 성능이 좋아 빠른 처리가 가능하다.
Wide Transformation
Wide Transformation은 입력 데이터의 여러 파티션 간에 데이터가 재분배되어야 하는 경우다. 다른 파티션으로부터 데이터를 읽어들여서 Shuffle(데이터 재분배)하는 과정이 필요하며, groupBy() 나 orderBy() 등의 연산이 여기에 해당된다.
Wide Transformation은 네트워크를 통한 대량의 데이터 이동을 발생시켜 실행 시간이 오래 걸리고 리소스 사용량이 많다.
Action
Action은 RDD로 결과 값을 계산하고, 연산 결과를 반환하거나 외부 스토리지(HDFS 등)에 저장한다. count() 나 show() 함수는 연산 결과를 반환하거나 출력하고, saveAsTextFile() 과 같은 함수로 연산 결과를 스토리지에 저장할 수 있다.
Action을 호출할 때마다 RDD가 처음부터 계산되는데, 반복적인 연산에 의한 비효율성을 피하기 위해 cache() 와 persist() 를 사용해 데이터를 메모리에 보관할 수 있다.
Web UI
스파크는 클러스터 상태와 리소스 사용을 모니터링하기 위해 Web UI를 제공한다. 기본적으로 4040 포트를 사용하는데 다음과 같은 내용을 볼 수 있다.
- 스케줄러의 Stage와 Task 목록
- RDD 크기와 메모리 사용의 요약
- 환경 정보
- 실행 중인 Executor 정보
- 모든 스파크 SQL 쿼리
아래는 AWS 문서에서 제공하는 화면이다. Web UI를 통해 Job, Stage, Task들이 어떻게 구성되는지 DAG 형태로 시각화해서 볼 수 있다. Stage 안에서 각각의 Task는 파란 박스로 표시되는데, 아래 예시에서 Stage 2는 2개의 Task로 구성되어 있음을 알 수 있다. Task가 여러 개라면 모두 병렬로 실행된다.
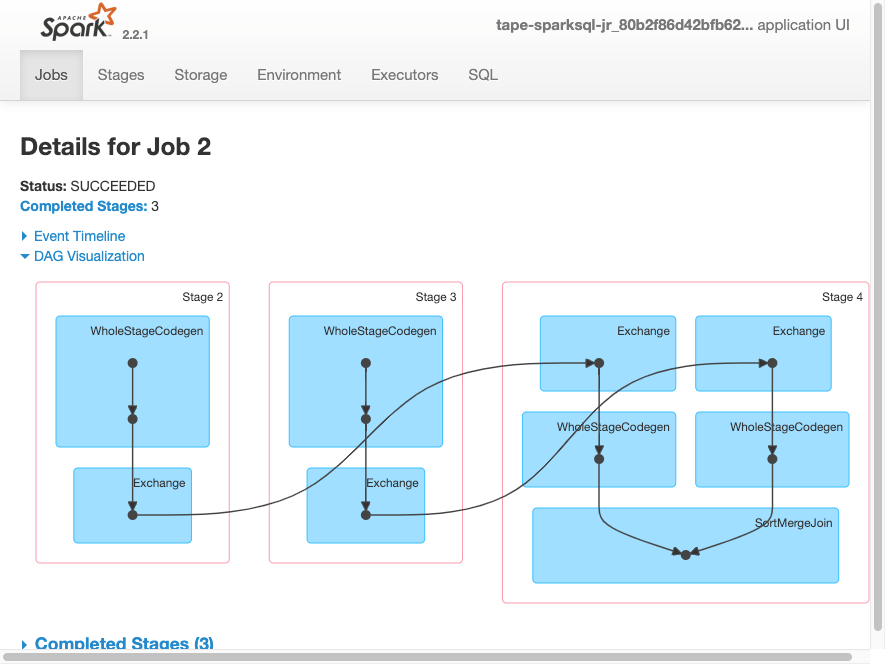
spark-submit
databricks/LearningSparkV2/chapter2 에서 각 주별로 학생들이 어떤 색깔의 M&M을 좋아하는지 알려주는 스파크 프로그램을 작성한 예제 mnmcount.py 를 가져온다. 동일한 위치의 data/ 경로에서 M&M 데이터셋 mnm_dataset.csv 을 확인할 수 있다.
M&M 개수 집계 (Python)
# src/mnmcount.py
from pyspark.sql import SparkSession
import sys
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: mnmcount <file>", file=sys.stderr)
sys.exit(-1)
# SparkSession 객체를 만든다.
spark = (SparkSession
.builder
.appName("PythonMnMCount")
.getOrCreate())
# 인자에서 M&M 데이터가 들어있는 파일 이름을 얻는다.
mnm_file = sys.argv[1]
# 데이터가 CSV 형식이며 헤더가 있음을 알리고 스키마를 추론하도록 한다.
mnm_df = (spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(mnm_file))
mnm_df.show(n=5, truncate=False)
# State, Color, Count 필드를 선택하고 State, Color를 기준으로 Count를 sum 집계한다.
# select, groupBy, sum, orderBy 메서드를 연결하여 연속적으로 호출한다.
count_mnm_df = (mnm_df.select("State", "Color", "Count")
.groupBy("State", "Color")
.sum("Count")
.orderBy("sum(Count)", ascending=False))
# 상위 60개 결과를 보여주고, 모든 행 개수를 count 집계해 출력한다.
count_mnm_df.show(n=60, truncate=False)
print("Total Rows = %d" % (count_mnm_df.count()))
# 위 집계 과정에서 중간에 where 메서드를 추가해 캘리포니아(CA) 주에 대해서만 집계한다.
ca_count_mnm_df = (mnm_df.select("*")
.where(mnm_df.State == 'CA')
.groupBy("State", "Color")
.sum("Count")
.orderBy("sum(Count)", ascending=False))
# 상위 10개 결과를 보여준다.
ca_count_mnm_df.show(n=10, truncate=False)
# SparkSession을 멈춘다.
spark.stop()Application 실행
spark-submit 스크립트에 파이썬 코드를 첫 번째 인자로, CSV 파일을 두 번째 인자로 전달한다.
실행 과정에서 불필요한 INFO 로그를 무시하고 싶다면, $SPARK_HOME/conf/ 경로에서 log4j2.properties.template 파일의 이름을 log4j2.properties 로 변경하고 파일 내용에서 rootLogger.level = info 부분의 값을 warn 으로 변경하면 된다.
(spark) % $SPARK_HOME/bin/spark-submit src/mnmcount.py data/mnm_dataset.csv
+-----+------+-----+
|State|Color |Count|
+-----+------+-----+
|TX |Red |20 |
|NV |Blue |66 |
|CO |Blue |79 |
|OR |Blue |71 |
|WA |Yellow|93 |
+-----+------+-----+
only showing top 5 rows
+-----+------+----------+
|State|Color |sum(Count)|
+-----+------+----------+
|CA |Yellow|100956 |
|WA |Green |96486 |
|CA |Brown |95762 |
|TX |Green |95753 |
|TX |Red |95404 |
|CO |Yellow|95038 |
|NM |Red |94699 |
|OR |Orange|94514 |
|WY |Green |94339 |
|NV |Orange|93929 |
|TX |Yellow|93819 |
|CO |Green |93724 |
|CO |Brown |93692 |
|CA |Green |93505 |
|NM |Brown |93447 |
|CO |Blue |93412 |
|WA |Red |93332 |
|WA |Brown |93082 |
|WA |Yellow|92920 |
|NM |Yellow|92747 |
|NV |Brown |92478 |
|TX |Orange|92315 |
|AZ |Brown |92287 |
|AZ |Green |91882 |
|WY |Red |91768 |
|AZ |Orange|91684 |
|CA |Red |91527 |
|WA |Orange|91521 |
|NV |Yellow|91390 |
|UT |Orange|91341 |
|NV |Green |91331 |
|NM |Orange|91251 |
|NM |Green |91160 |
|WY |Blue |91002 |
|UT |Red |90995 |
|CO |Orange|90971 |
|AZ |Yellow|90946 |
|TX |Brown |90736 |
|OR |Blue |90526 |
|CA |Orange|90311 |
|OR |Red |90286 |
|NM |Blue |90150 |
|AZ |Red |90042 |
|NV |Blue |90003 |
|UT |Blue |89977 |
|AZ |Blue |89971 |
|WA |Blue |89886 |
|OR |Green |89578 |
|CO |Red |89465 |
|NV |Red |89346 |
|UT |Yellow|89264 |
|OR |Brown |89136 |
|CA |Blue |89123 |
|UT |Brown |88973 |
|TX |Blue |88466 |
|UT |Green |88392 |
|OR |Yellow|88129 |
|WY |Orange|87956 |
|WY |Yellow|87800 |
|WY |Brown |86110 |
+-----+------+----------+
Total Rows = 60
+-----+------+----------+
|State|Color |sum(Count)|
+-----+------+----------+
|CA |Yellow|100956 |
|CA |Brown |95762 |
|CA |Green |93505 |
|CA |Red |91527 |
|CA |Orange|90311 |
|CA |Blue |89123 |
+-----+------+----------+처음에는 mnm_dataset.csv 의 상위 5개 행을 보여주고, 이어서 각 주별, 색깔별 합계를 출력한다. 그리고, 캘리포니아(CA)에 대한 결과만 별도로 출력한다.
References
- https://www.oreilly.com/library/view/learning-spark-2nd/9781492050032/
- https://www.databricks.com/en/glossary/what-are-spark-applications
- https://spark.apache.org/docs/latest/cluster-overview.html
- https://velog.io/@dbgpwl34/Spark-스파크-애플리케이션의-아키텍처-스파크-애플리케이션의-생애-주기
- https://spark.apache.org/docs/latest/rdd-programming-guide.html
- https://6mini.github.io/data%20engineering/2021/12/12/rdd/
- https://mengu.tistory.com/27
- https://sunrise-min.tistory.com/entry/Apache-Spark-RDD
- https://docs.aws.amazon.com/glue/latest/dg/monitor-spark-ui.html
- https://github.com/databricks/LearningSparkV2
