파이썬 머신러닝 완벽 가이드 - 9. Text Analytics(1) (Encoding, Vectorize)
[AI Study] 파이썬 머신러닝 완벽 가이드

Text Analytics 텍스트 분석
- TA(Text Analytics or Text Mining)
- 비정형 텍스트에서 의미있는 정보를 추출하는 것에 좀 더 중점을 두고 발전
- 머신러닝, 언어 이해, 통계 등을 활용해 모델을 수립하고 정보를 추출해 비즈니스 인텔리전스나 예측 분석 등의 분석 작업을 주로 수행한다.
- 텍스트 분류 : 문서가 특정 분류/카테고리에 속하는 것을 예측하는 기법 ← 지도학습
- 감성 분석 : 텍스트에서 나타나는 감정/판단/믿음/의견/기분 등의 주관적인 요소들을 분석하는 기법 ← 지도&비지도학습
- 텍스트 요약 : 텍스트 내에서 중요한 주제나 중심 사상을 추출하는 기법 ex) 토픽 모델링 (Topic Modeling)
- 텍스트 군집화와 유사도 측정 : 비슷한 유형의 문서에 대해 군집화를 수행하는 기법 ← 비지도학습
- NLP(Nature Language Processing)
- 머신이 인간의 언어를 이해하고 해석하는 데에 더 중점을 두고 발전
- 기계번역, 질의응답 시스템 등의 영역에서 텍스트 분석과 차별점 존재
1. 텍스트 분석의 이해
: 비정형 데이터인 텍스트를 분석하는 것. 머신러닝 알고리즘은 숫자형의 피처 기반 데이터만 입력받을 수 있기 때문에 비정형 텍스트 데이터를 피처 형태로 추출하고, 추출된 피처에 의미있는 값을 부여하는 게 중요하다.
- 피처 벡터화(Feature Vectorization), 피처 추출(Feature Extraction) : 텍스트를 word(or word의 일부분) 기반의 다수의 피처로 추출하고, 이 피처에 단어 빈도수와 같은 숫자값을 부여하면 텍스트는 단어의 조함인 벡터값으로 표현될 수 있는데, 이렇게 텍스트를 변환하는 것
- 방법: BOW(Bag of Words), Word2Vec (책에서는 BOW만 설명)
- 과정
- 텍스트 전처리
- 클렌징 : 대소문자 변경, 특수문자, 기호 삭제 등
- 토큰화 : 문장/단어
- 불용어, 필터링, 철자수정 : 의미없는 단어(stop word) 등 제거
- 어간/표제어 추출 : 단어에서 어간 및 표제어 추출
- 피처 추출 / 벡터화 (Encoding) : 피처를 추출하고 벡터값 할당
- BOW(Bag of Words) : Count 기반, TF-IDF 기반
- Word2Vec
- ML 모델 수립 및 학습/예측/평가
- 텍스트 전처리
- 파이썬 기반의 NLP, 텍스트 분석 패키지
-
NLTK(Natural Language Toolkit for Python): 가장 대표적인 NLP 패키지. 수행 성능, 속도, 신기술, 엔터프라이즈한 기능 지원 등에서 아쉬워 실제 업무에서는 잘 안쓰임
-
Gensim: 토픽 모델링 분야에서 가장 두각을 나타내는 패키지
-
SpaCy: 뛰어난 수행 성능으로 최근 가장 주목을 받는 NLP 패키지
⇒ 사이킷런과 더불어 이러한 NLP 전용 패키지와 결합해 애플리케이션을 작성하는 경우가 많다.
-
2. 텍스트 전처리
- 텍스트 정규화 : 텍스트를 머신러닝 알고리즘이나 NLP 애플리케이션에 입력 데이터로 사용하기 위해 클렌징, 정제, 토큰화, 어근화 등의 다양한 텍스트 데이터의 사전작업을 수행하는 것 → 클렌징, 토큰화, 필터링 | 스톱워드 제거 | 철자 수정, Stemming, Lemmatization
- 클렌징(Cleansing) : 대소문자 변경, 특수문자, 기호 삭제 등
- 토큰화(Tokenization)
- 문장 토큰화
- 문서에서 문장을 분리
- 문장의 마침표(.), 개행문자(\n) 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 게 일반적
- 정규 표현식에 따른 문장 토큰화도 가능
- 각 문장이 가지는 시맨틱적 의미가 중요한 요소로 사용될 때 사용
- NLTK의 경우 단어 사전과 같이 참조가 필요한 데이터 세트의 경우 인터넷으로 다운 받을 수 있다.
nltk.download('punkt') --- from nltk import sent_tokenize sent_tokenize(text=텍스트 파일) # 각각의 문장으로 구성된 list 객체 반환
- 단어 토큰화
-
문장을 단어로 토큰화 하는 것
-
공백, 콤마(,), 마침표(.), 개행문자 등으로 단어를 분리하지만, 정규표현식으로 다양한 유형으로 토큰화 수행 가능
from nltk import word_tokenize word_tokenize(문장) # 각각의 단어로 구성된 list 객체 반환 -
단점 : 문맥적 의미가 무시된다.
-
n-gram
- 위의 단점을 보완하기 위해 도입됨
- 연속된 n개의 단어를 하나의 토큰화 단위로 분리하는 것
- n개 단어 크기 윈도우를 만들어 문장의 처음부터 오른쪽으로 움직이면서 토큰화 수행
- 예) Agent Smith knocks the door 를 2-gram(bigram)으로 만들면,
(Agent, Smith), (Smith, knocks), (knocks, the), (the, door)로 토큰화
-
- 문장 토큰화
- 불용어(Stop Word) 제거
-
불용어 : 분석에 큰 의미가 없는 단어 (예: 영어에서 is, the, a, will 등)
-
제거하는 이유 : 스톱워드는 문법적인 특성으로 인해 빈번하게 텍스트에 나타나므로 제거하지 않으면 빈번함으로 인해 중요 단어로 인식된다.
-
언어별로 불용어가 목록화 되어 있다.
nltk.download('stopword') nltk.corpus.stopwords.words('english') # 이후 for, if문을 이용하여 스톱워드를 제거한다.
-
- 추출(Stemming, Lemmatization) : 문법적, 의미적으로 변화하는 단어의 원형을 찾는 것
- 어간 추출(Stemming): 원형 단어로 변환 시 일반적인 방법을 적용하거나 더 단순화된 방법을 적용해 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 있음
-
어간 추출은 품사 정보를 갖고 있지 않음 : 단어의 뜻이 분명한 경우
from nltk.stem import LancasterStemmer stemmer = LancasterStemmer() stemmer.stem('working') # -> work 로 변환
-
- 표제어 추출(Lemmatization) : 표제어 추출은 Stemming보다 정교하며 의미론적인 기반에서 단어의 원형을 찾음, 단어의 [품사 정보]를 포함하고 있음
-
정확한 원형 단어 추출을 위해 단어의 품사를 입력해줘야 한다. 동사=’v’, 형용사=’a’
-
명사 / 동사로 쓰일 때 반어의 뜻이 완전히 달라지는 경우 ex) bear, taxi,
-
시간은 좀 더 걸린다.
from nltk.stem import WordNetLemmatizer lemma = WordNetLemmatizer() lemma.lemmatize('amusing', 'v') # -> amuse로 변환
-
- 어간 추출(Stemming): 원형 단어로 변환 시 일반적인 방법을 적용하거나 더 단순화된 방법을 적용해 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 있음
3. 피처 추출 / 피처 벡터화 (Encoding) - BOW(Bag of Words) & Word2Vec
-
피처 벡터화(Encoding) : ML알고리즘에 입력할 수 있도록, 텍스트를 특정 의미를 갖는 숫자형인 벡터값으로 변환하는 것
-
각 문서의 텍스트를 단어로 추출해 피처로 할당
-
각 단어의 발생빈도와 같은 값을 피처 값으로 부여
⇒ 각 문서를 단어 피처의 발생 빈도값으로 구성된 벡터로 만드는 기법
: 기존 텍스트 데이터를 또 다른 형태의 피처의 조합으로 변경하는 것이기 때문에 피처 추출에 포함하기도 한다. (TA에서는 피처 벡터화와 피처 추출을 같은 의미로 사용하곤 한다.)
-
-
BOW : 문서가 갖는 모든 단어(words)를 문맥이나 순서를 무시하고 일괄적으로 단어의 빈도 값을 부여해 피처값을 추출하는 모델
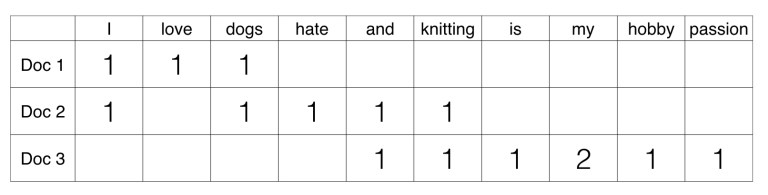
- 방식
- 문장 1과 문장 2에 있는 모든 단어에서 중복을 제거하고, 각 단어(feature or term)를 컬럼 형태로 나열
- 각 단어에 고유의 index를 부과 ex) ‘I’ : 0, ‘love’ : 1, ‘dogs’ : 3, ‘hate’ : 4 …
- 개별 문장을 로우로 잡고, 해당 단어가 나타나는 횟수(Occurrence)를 각 단어(단어 인덱스)에 기재합니다.
- 즉 M 개의 문장과 N 개의 단어 피처들로 이뤄진 MxN행렬이 구성되게 됨
- 장점 : 쉽고 빠른 구축
- 단점
- 문맥의미(Semantic context) 반영 부족: 단어의 순서를 고려하지 않기 때문에 n-gram 기법 활용 가능하나 제한적이다.
- 희소행렬 문제(희소성, 희소행렬): BOW로 피처 벡터화를 수행하면 희소행렬 형태의 데이터 세트가 만들어지기 쉽다. 희소행렬은 일반적으로 ML알고리즘의 수행시간과 예측 성능을 떨어뜨린다. (그래서 희소행렬을 위한 기법 마련되어 있음)
- 방식
-
CountVectorizer : 단어에 피처 값을 부여 할 때, 각 문서에 해당 단어가 등장하는 횟수 Count로 Vector화
- CountVectorizer에서는 카운트 값이 높을 수록 중요한 단어로 인식
- 그러나 카운트만 부여할 경우, 그 문서의 특징을 나타내기 보다, 언어 특성상 자주 사용될 수 밖에 없는 단어까지 높은 값을 부여받게 됨
- 이러한 문제를 보완하기 위해 TF-IDF (Term Frequency Inverse Document Frequency) Vectorizer를 사용 함
-
TF-IDFVectorizer : 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에 전반적으로 자주 나타나는 단어에 대해서는 패널티를 주는 방식으로 값을 부여
-
문서마다 텍스트 길이가 길고, 문서의 갯수가 많은 경우에는, Count보다 TF-IDF 방식을 사용하느 것이 더 좋은 성능을 낼 가능성이 높음

-
3.1. CountVectorizer (카운트 기반 벡터화)
: 단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는 횟수를 부여하는 경우
- 카운트 값이 높을 수록 중요한 단어로 인식한다.
- 사이킷런 - CountVectorizer 클래스 제공
from sklearn.feature_extraction.text import CountVectorizer- 소문자 일괄 변환, 토큰화, 스톱워드 필터링 등 텍스트 전처리도 함께 수행해줌
- 파라미터 (TF-IDF도 동일)
파라미터 설명 max_df 전체 문서에 걸쳐서 너무 높은 빈도수를 가지는 단어 피처를 제외하기 위한 파라미터, int 입력: 주어진 값 이하로 나타나는 단어만 피처로 추출, float 입력: 빈도가 0~주어진 값% 까지만 피처로 추출 min_df 전체 문서에 걸쳐서 너무 낮은 빈도수를 가진 단어 피처를 제외하기 위한 파라미터, int 입력: 주어진 값 이하로 나타나는 단어는 피처로 추출하지 않음, float 입력: 하위 주어진 값% 이하의 빈도를 가지는 단어는 피처로 추출하지 않음 max_features int 입력 : 추출하는 피처의 개수를 제한, 가장 높은 빈도수를 가지는 단어순으로 정렬해 주어진 값 개수까지만 피처로 추출 stop_words ‘english’로 지정하면 영어의 스톱워드로 지정된 단어는 추출에서 제외 n_gram_range 단어 순서를 어느 정도 보강하기 위한 n_gram 범위 설정, 튜플 형태 (범위 최소값, 범위 최대값) analyzer default = ‘word’, 피처 추출을 수행할 단위 지정, character의 특정 범위를 피처로 만드는 특정 경우에 사용 token_pattern default = ‘\b\w\w+\b’ 공백 또는 개행 문자 등으로 구분된 단어 분리자(\b) 사이의 두 문자(영숫자) 이상의 단어를 토큰으로 분리, 정규 표현식 패턴 지정, analyzer=’word’일때만 변경 가능 (거의 변경X) tokenizer 토큰화를 별도의 커스텀 함수로 이용시 적용, 일반적으로 CountTokenizer 클래스에서 어근 변화시 이를 수행하는 별도의 함수를 tokenizer 파라미터 적용하면 된다. - fit(), transform()을 통해 피처 벡터화된 객체 반환
-
반드시 학습 데이터를 이용해 fit()이 수행된 객체를 이용해 테스트 데이터를 변환(transform)해야 한다.
-
그래야만 학습시 설정된 CountVectorizer의 피처 개수와 테스트 데이터를 CountVectorizer로 변환한 피처 개수가 같아진다.
-
테스트 데이터의 피처 벡터와 시 fit_transform() 사용 X
cnt_vect = CountVectorizer() cnt_vect.fit(X_train) X_train_cnt_vect = cnt_vect.transform(X_train) X_text_cnt_vect = cnt_vect.transform(X_test)
-
- Process
- 사전 데이터 가공(전처리): 모든 문자를 소문자로 변경 등
- 토큰화: 디폴트는 단어기준(analyzer = True), n_gram_range를 반영하여 토큰화 수행
- 텍스트 정규화
-
stop words 필터링 수행
-
Stemmer, Lemmatizer는 지원 X
이를 위한 함수를 만들어 tokenizer 파라미터에 적용하거나 외부 패키지로 미리 텍스트 정규화 수행 필요
-
피처 벡터화: 토큰화 된 단어 피처로 추출, 단어 빈도수 벡터 값을 적용
-
- 단점: 문서의 특징을 나타내기 보다는 언어 특성상 문장에서 자주 사용될 수 밖에 없는 단어까지 높은 값을 부여 받는다.
3.2. TF-IDF (Term Frequency-Inverse Document Frequency) Vectorizer
: 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 패털티를 주는 방식으로 값을 부여한다.
- 문서마다 텍스트가 길고 문서의 개수가 많을 경우 카운트 방식보다 TF-IDF 방식을 사용하는 게 좋다.
- : 개별 문서에서 단어 i 빈도, : 단어 i를 가지고 있는 문서 개수, N: 전체 문서 개수
- 사이킷런 - TfidfVectorizer 클래스 제공
-
파라미터와 변환 방법은 CountVectorizer와 동일
from sklearn.feature_extraction.text import TfidfVectorizer
-
3.3. 희소행렬
: 희소행렬(Sparse Matrix)은 행렬의 값이 대부분 0인 경우를 가리키는 표현 ↔ 밀집행렬(Dense Matrix)
: 모든 문서로 피처 벡터화를 수행하면 + n-gram (1,2) , (1,3) 등 주면 칼럼 수가 더욱 증가
: 희소행렬은 일반적으로 ML알고리즘의 수행시간과 예측 성능을 떨어뜨림
→ 메모리 공간이 많이 필요하고, 연산 시간이 오래 걸린다. 따라서, 물리적으로 적은 메모리 공간을 차지할 수 있도록 변환해야 한다.
희소행렬을 COO, CSR 형태의 희소행렬로 압축해줘야 함 (CSR을 더 많이 사용함)
: CountVectorizer, TfidfVectorizer 은 희소행렬을 반환(CSR 형태)
3.3.1. COO(Coordinate : 좌표) 형식
: 0이 아닌 데이터만 별도의 데이터 배열에 저장하고, 그 데이터가 가르키는 행과 열의 위치를 별도의 배열에 저장하는 방식
예) [ [3, 0, 1], [0, 2, 0] ] → (row, col): (0, 0), (0, 2), (1, 1) → row: [0, 0, 1], col: [0, 2, 1]
- 희소행렬 변환은 주로 Scipy의 sparse 패키지 사용
import numpy as np # BOW에서 좌표 기반으로 밀집행렬 추출 dense = np.array( [ [ 3, 0, 1 ], [0, 2, 0 ] ] ) from scipy import sparse # 0 이 아닌 데이터 추출 data = np.array([3,1,2]) # 행 위치와 열 위치를 각각 array로 생성 row_pos = np.array([0,0,1]) col_pos = np.array([0,2,1]) # sparse 패키지의 coo_matrix를 이용하여 COO 형식으로 희소 행렬 생성 # 매개변수로 채워넣을 숫자인 순차적 data와, (row_pos, col_pos)의 좌표 정보를 tuple 형태로 주는 듯 sparse_coo = sparse.coo_matrix((data, (row_pos,col_pos))) sparse_coo.toarray() > array([3, 0, 1], [0, 2, 0]) - 단점: 행과 열의 위치를 나타내기 위해서, 반복적인 위치 데이터를 사용해야 한다.
3.3.2. CSR(Compressed Sparse Row) 형식
: 행 위치 배열 내에 있는 고유한 값의 시작 위치만 다시 별도의 위치 배열로 가지는 변환 방식
from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
# 0 이 아닌 데이터 값 배열
data2 = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1])
# 열 위치와 행 위치를 각각 array로 생성
col_pos = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0])
row_pos = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5])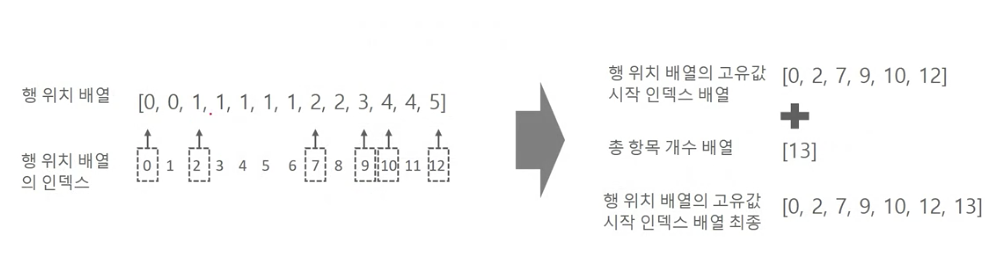
# 행 위치 배열의 고유한 값들의 시작 위치 index를 배열로 생성
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13])
# sparse 패키지의 csr_matrix를 이용하여 CSR 형식으로 희소 행렬 생성
# 매개변수로 채워넣을 숫자인 순차적 (data, row_pos_ind인 좌표의 위치 정보, col_pos인 좌표 정보) 를 tuple로
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))
print('COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_coo.toarray())
print('CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_csr.toarray())
> COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
> [[0 0 1 0 0 5]
> [1 4 0 3 2 5]
> [0 6 0 3 0 0]
> [2 0 0 0 0 0]
> [0 0 0 7 0 8]
> [1 0 0 0 0 0]]
> CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
> [[0 0 1 0 0 5]
> [1 4 0 3 2 5]
> [0 6 0 3 0 0]
> [2 0 0 0 0 0]
> [0 0 0 7 0 8]
> [1 0 0 0 0 0]]- 실제 사용로 사용할 때 ⇒ 밀집 행렬을 매개변수(생성 파라미터)로 입력하면 COO나 CSR 희소 행렬로 생성한다.
