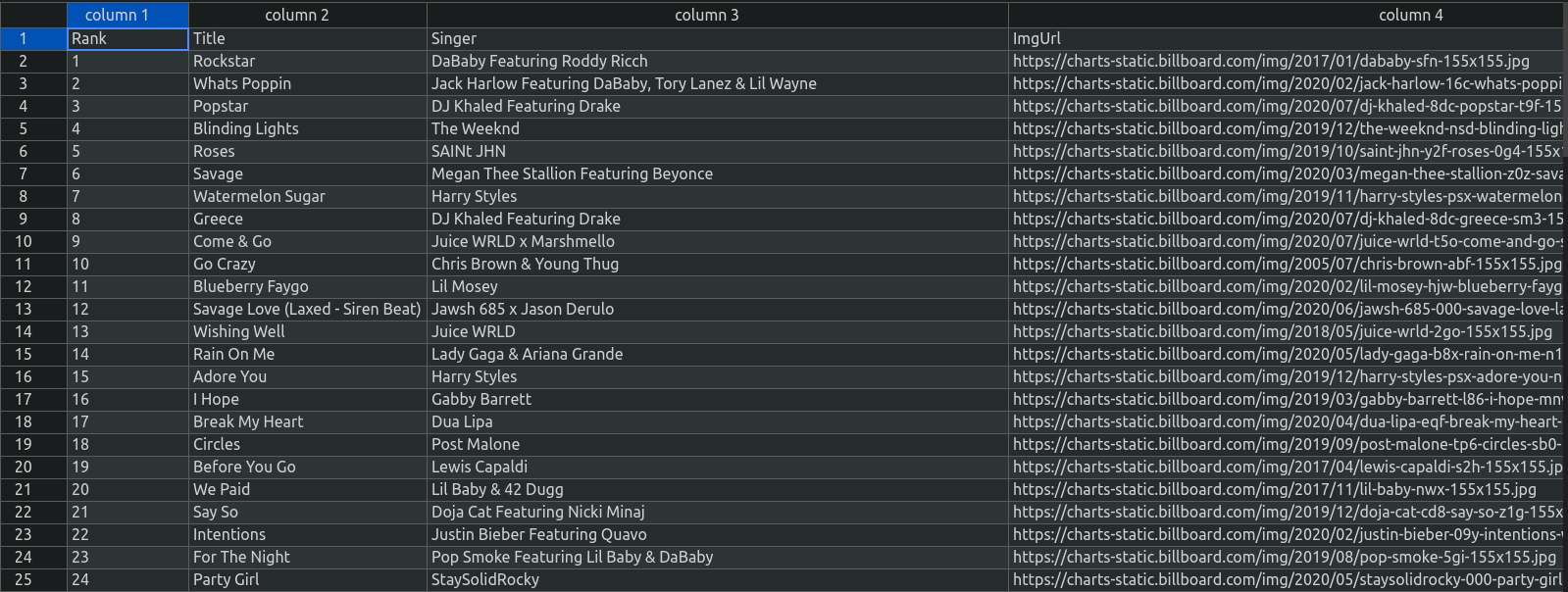
빌보드 차트로 웹크롤링에 대하여 알아보겠습니다.
우선, 빌보드 차트를 한번 보시죠~
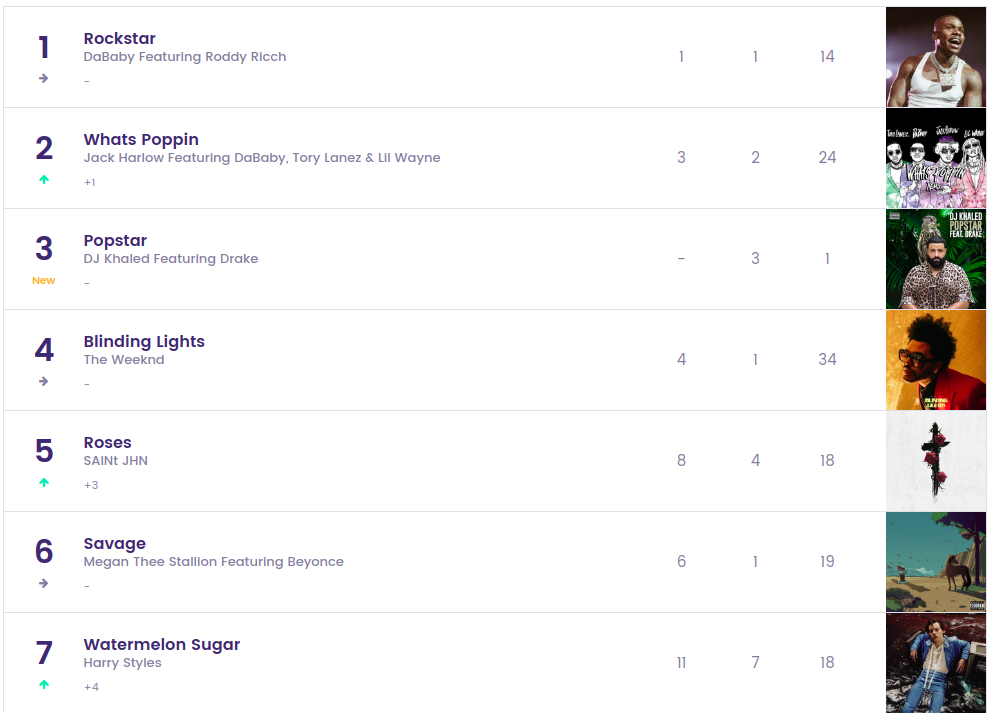
짜쟌~ 이런식으로 구성되어있습니다.
빌보드차트에서 순위, 곡, 아티스트 정보, 이미지를 BeutifulSoup/셀레니움을 이용하여 크롤링 해보겠습니다~!
가상환경 생성 및 세팅
우선, 크롤링을 위한 새로운 가상환경을 설정하고, 그 위에 필요한 프로그램들을 설치해보겠습니다. 가상환경을 미니콘다를 사용하여 생성하였습니다.
conda create -n web-crawling python=3.8
# web-crawling은 제가 설정한 가상환경의 이름입니다.이제 가상환경에서 필요한 라이브러리들을 설치해볼게요.
conda activate web-crawling # 가상환경 실행
pip install beautifulsoup4
pip install seleniumselenium은 사용할 브라우저의 웹드라이버를 필요로 합니다. 저는 크롬 웹드라이버를 사용하여 보겠습니다. 웹드라이버 설치시 꼭 버전확인을 해주세요! 본인의 크롬 버전과 웹 드라이버의 크롬 버전이 일치해야합니다.
버전 확인은
chrome://version/ 다음과 같이 주소창에 치시면 확인하실 수 있습니다!
웹드라이버는 이곳에서 다운받아주세요.
이제 본격적으로 크롤링을 시작해볼게요~
import
우선 필요한 것들을 import시켜보겠습니다.
from selenium import webdriver
from bs4 import BeautifulSoup
import csv
import time
from selenium.webdriver.common.keys import Key #스크롤을 내릴때 필요한 라이브러리csv file
csv_filename = "billboard_chart.csv"
csv_open = open(csv_filename, "w+", encoding='utf-8')
csv_writer = csv.writer(csv_open)
csv_writer.writerow( ('Rank', 'Title', 'Singer', 'ImgUrl'))우선 크롤링을 하기위해서는 개발자 페이지 창을 잘 살펴보아야합니다.
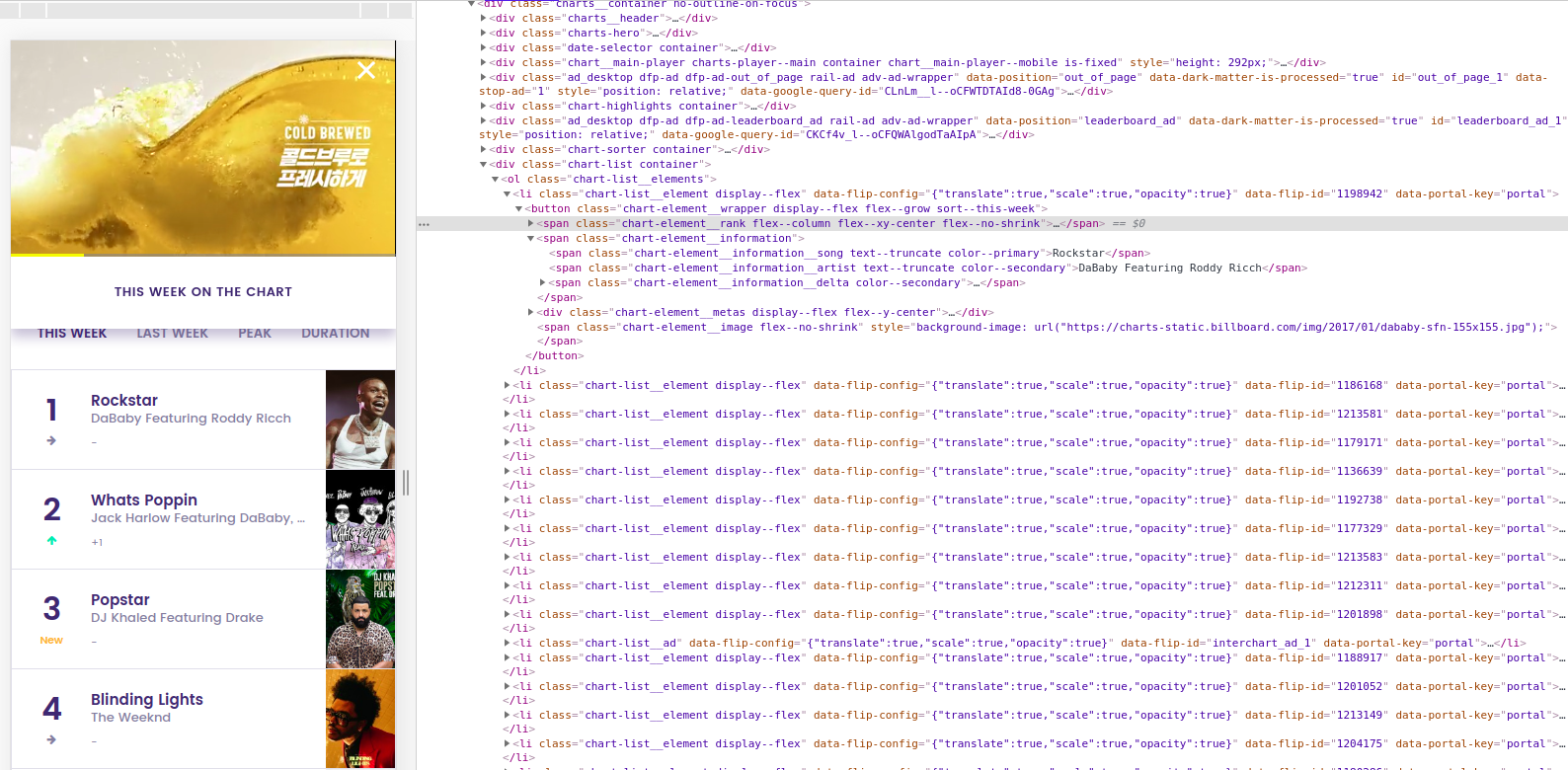
크게 find와 select함수를 이용할 수 있는데 저는 find함수를 선택하였습니다!
웹 드라이더 사용하기
chrome_driver_path = "/home/kimhyunwoo/Downloads/chromedriver" # 크롬드라이버 경로 지정
insert_url = "https://www.billboard.com/charts/hot-100"
browser = webdriver.Chrome(chrome_driver_path) # 크롬 웹드라이버 객체를 얻는다.
browser.get(insert_url) # get 메소드에 원하는 url 경로를 넣어준다.
browser.implicitly_wait(5) 해당 url을 열자마자 바로 소스를 가져오면 request / reply 시간보다 코드가 빨리 실행되어서 이미지의 url을 찾지 못하는 경우가 있으므로 browser.implicitly_wait(5)을 사용합니다.
페이지 스크롤 다운 및 html가져오기
pagedowns = 1 # 스크롤을 20번 진행
element = browser.find_element_by_tag_name("body") # body태그부터 시작
while pagedowns < 20:
# PAGE_DOWN(스크롤)에 따라서 결과가 달라짐.
# 기본적으로 브라우저 조작을 통해 값을 얻어올 때는 실제 브라우저에 보이는 부분이어야 요소를 찾거나 특정 이벤트를 발생시킬 수 있다.
element.send_keys(Keys.PAGE_DOWN)
# 페이지 스크롤 타이밍을 맞추기 위해 sleep
time.sleep(1)
pagedowns += 1
html = browser.page_source # html을 문자열로 가져온다.
browser.close()
bs = BeautifulSoup(html,'html.parser')페이지 스크롤 다운 기능을 추가한 이유는 창을 열고 그냥 단순히 html 소스만 받아오면, 이미지들이 제한적으로 불러오기 때문입니다.
이 이유는 아마도, 페이지 제작시 javascript가 동적으로 작동하는지 정적으로 작동하는지에 따라 달라집니다.
다음 포스팅에는 스타벅스를 이용한 웹스크롤링을 진행 할 것입니다. 그때 차이를 살펴보기로해요~!
데이터 저장 및 csv파일 저장
for data in wrap_data:
img_tag = data.find('span', attrs={'class':'chart-element__image'})
src_tag = img_tag.get("style")
imgUrl_list = src_tag.split('\"')[1]
# print(s)
rank_list = data.find('span', attrs={'class':'chart-element__rank__number'})
songTitle_list = data.find('span', attrs={'class':'chart-element__information__song'})
artist_list = data.find('span', attrs={'class':'chart-element__information__artist'})
csv_writer.writerow( (rank_list.text, songTitle_list.text, artist_list, imgUrl_list) )이미지 url 출력
위의 코드에서src_tag를 출력하여보면,
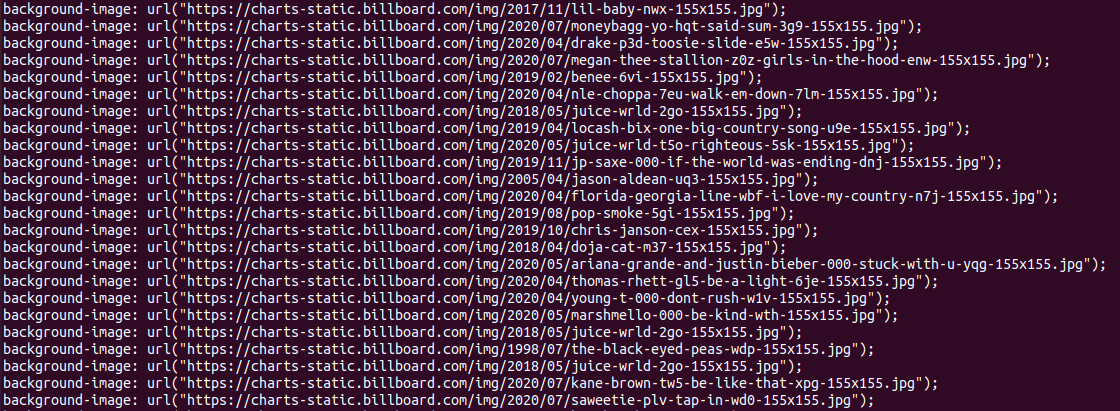 출력값을 확인해 볼 수 있고,
출력값을 확인해 볼 수 있고,
이 중에서 url부분만 출력되야하므로"을 기준으로 문자열을 split하여 추출해낸다.
순위, 곡, 아티스트 정보 출력
순위, 곡, 아티스트 정보은 .text를 활용하여 text값을 받아오면 된다.
출력 결과