앞에서는 빌보드 차트로 웹크롤링을 해보았다...!
스타벅스 웹크롤링은 빌보드 차트보다 조금 더 수월하게 느껴졌다.
방식은 거의 동일하니 구현해보도록하자!
이번에는 스타벅스 코리아에 있는 MENU에 음료에 있는 모든 음료의 제목과 이미지를 크롤링해서 csv로 저장해 봅시다.
구성은 아래와 같습니다!
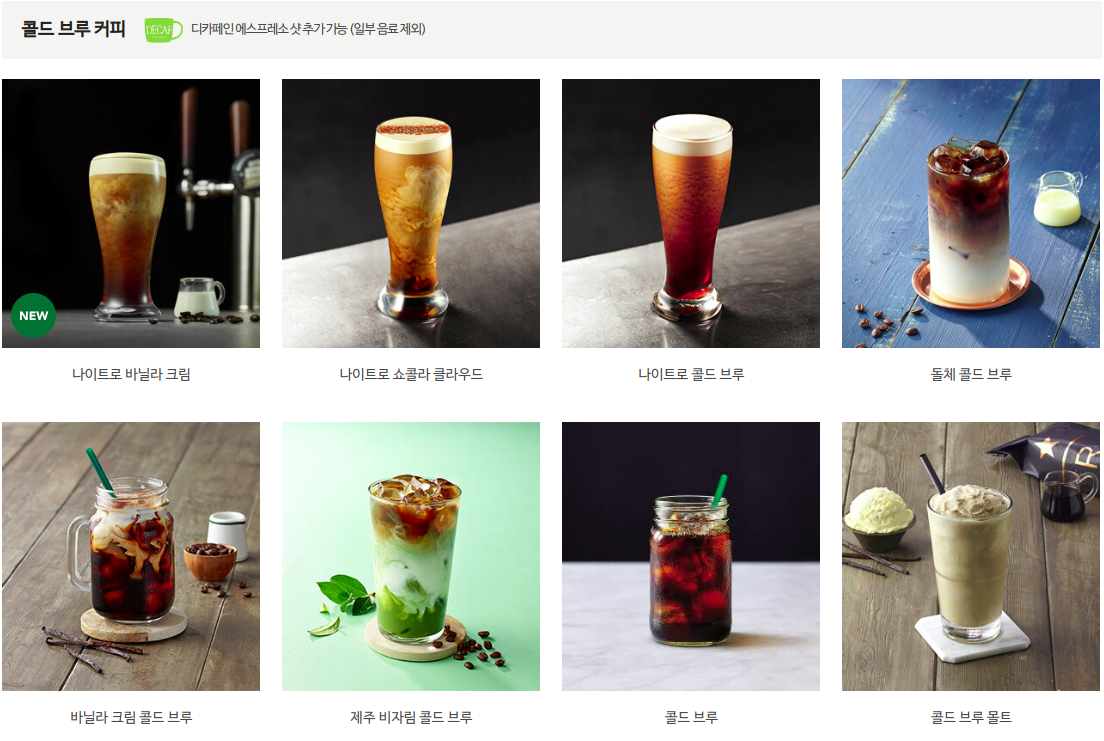
제가 크롤링 할 부분의 개발자 도구로 들어가 html, css을 살펴보도록 하죠!
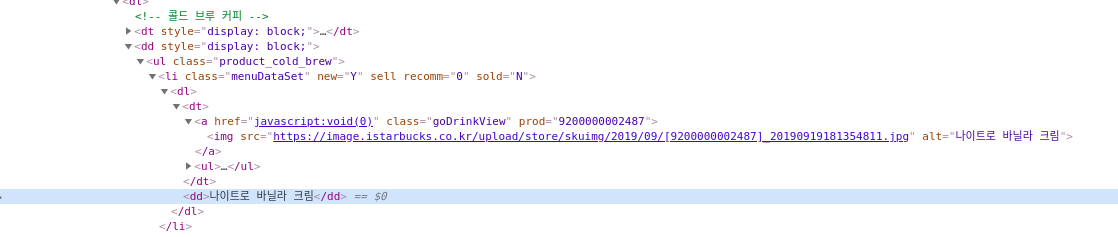
첫번쨰 메뉴인 나이트로 바닐라 크림을 살펴보면,
li태그와 classmenuDataSet을 활용해 볼 수 있겠다는 생각이 듭니다!
자세한 설명은 앞에 포스팅한 빌보드 차트 웹크롤링을 보시고, 지금은 간단하게 살펴보겠습니다.
import
from selenium import webdriver
from bs4 import BeautifulSoup
import csv csv파일
csv_filename = "starbuck_menu.csv"
csv_open = open(csv_filename, "w+", encoding='utf-8')
csv_writer = csv.writer(csv_open)
csv_writer.writerow( ('Title', 'ImgUrl') )웹 드라이더 사용하기
chrome_driver_path = "/home/kimhyunwoo/Downloads/chromedriver"
insert_url = "https://www.starbucks.co.kr/menu/drink_list.do"
browser = webdriver.Chrome(chrome_driver_path) # 크롬 웹드라이버 객체를 얻는다.
browser.get(insert_url) # get 메소드에 원하는 url 경로를 넣어준다데이터 받아오기
browser.implicitly_wait(5)
html = browser.page_source
# print(html)
bs = BeautifulSoup(html, 'html.parser')
wrap_data = bs.findAll("li", {"class": "menuDataSet"})
for data in wrap_data:
img_tag = data.find("img")
src_tag = img_tag.get("src")
# print(src_tag)
csv_writer.writerow( (data.text, src_tag) 빌보드 차트와의 차이점
빌보드 차트는 스크롤 가능을 추가하였지만, 스타벅스의 경우
html = browser.page_source
bs = BeautifulSoup(html, 'html.parser')
위와같이, 단순히 받아와도 문제가 없다.
그 이유는 빌보드 차트 포스팅에서 말했던 것과 같이, 스타벅스 페이지는 제작시에 페이지를 여는 순간 모든 html 정보를 통신 할 수 있도록 만든 것 같다는 추측을 해보았다.
결론적으로,
페이지가 열리고 바로 html 정보를 모두 받을 수 있다면, 구지 스크롤 기능은 추가할 필요가 없고
만약 그렇지 않고 정보를 제한적으로 받을 수 있다면, 수동적으로 스크롤 기능을 통하여 정보를 받아와야 한다!
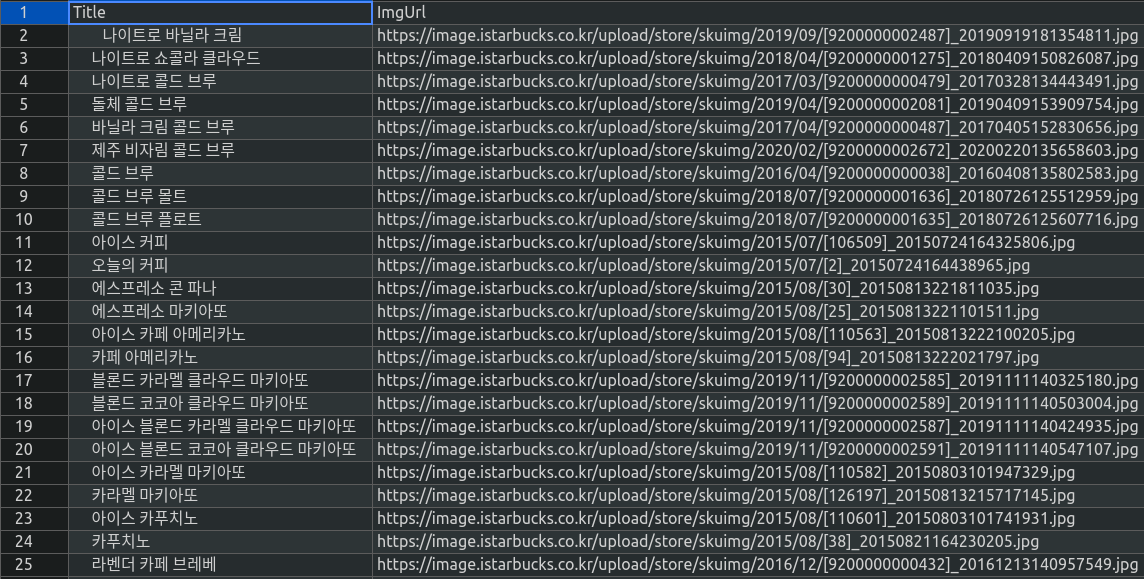
결과는 다음과 같다

코딩을 잘하는 개발자가 되자!