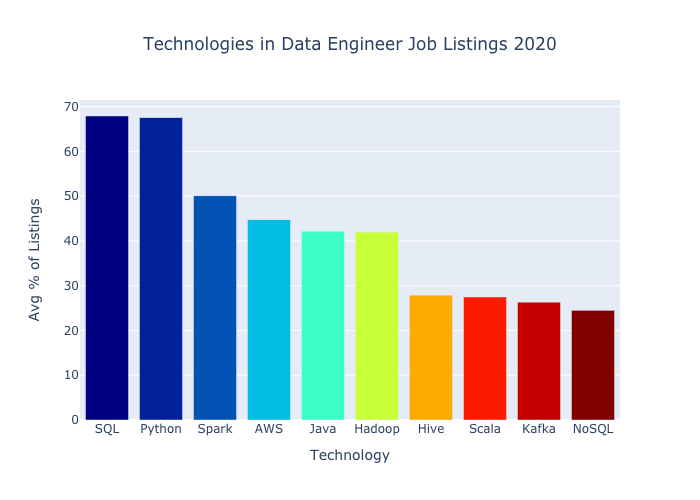
Data science task에 필요한 knowledge & skill을 hierarchy pyramid로 표현한 그림이다:
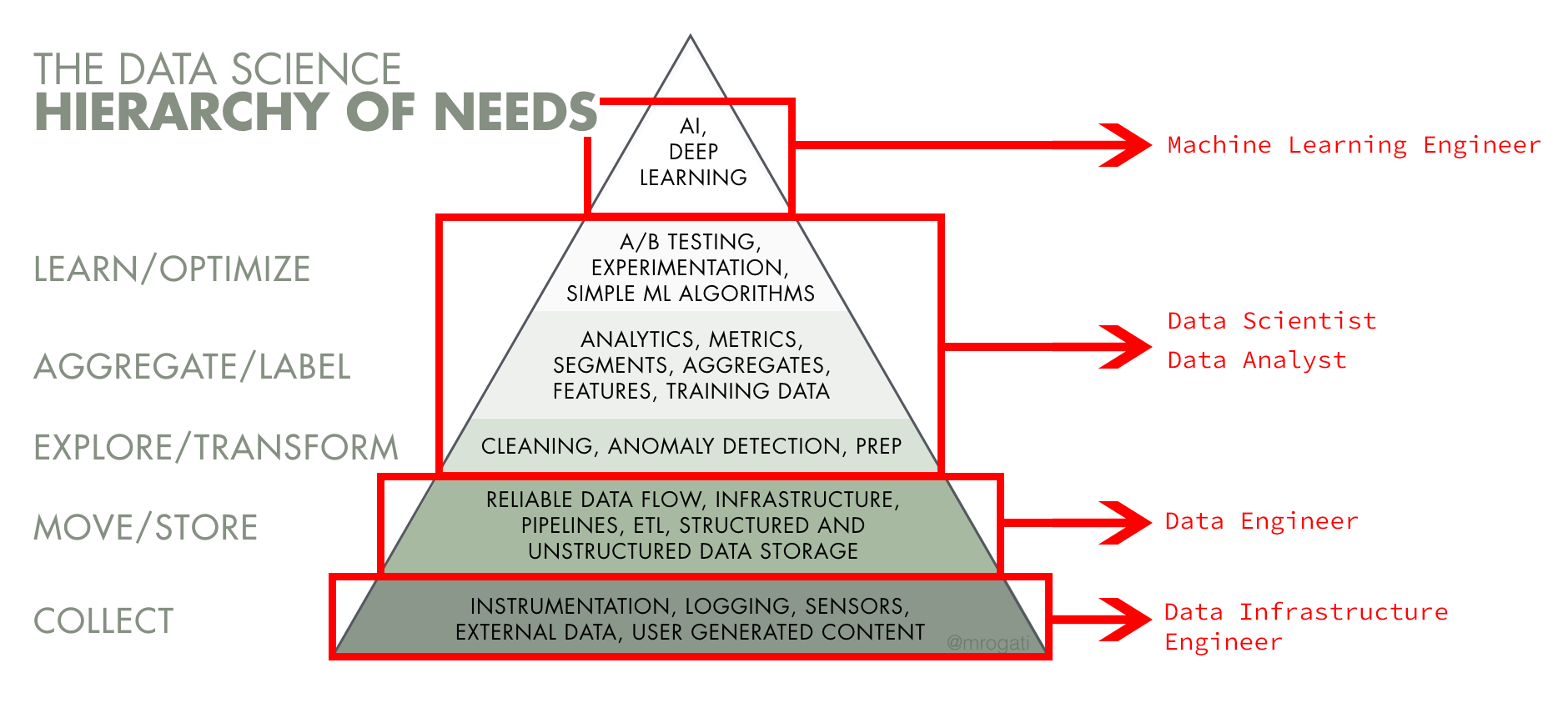 (created by Monica Rogati)
(created by Monica Rogati)
Pyramid의 가장위인 AI까지 도달하기위해서 가장 foundation에서 data engineer의 역할인 "collect"에서부서 시작한다. Data engineer가 data pipline을 통해 data를 이동, 변환시키고 Data Science team으로 사용할 수 있는 data를 전달한다. 여기서 data engineer는 Java, Scala, C++, Python등을 사용한다. Data scientist는 처리된 data를 analyze, test, aggregate, optimize하고 data의 의미를 정리해서 관계자들에게 present한다. 그 이후 AI engineer, Machine learning engineer, Deep learning engineer가 algorithm, model을 적용하면서 AI system을 개발해나아갈 수 있다.
data engineer task에 필요한 skill set이 pyramid에서 가장 기반이 되고있다. 거의 모든 산업에서 data의 활용도가 매우 높아지면서 data engineer의 역할이 그 어느때보다 더 vital해지고 있다. Data engineer은 data architect로 불려지기도 한다. 주로 computer engineering or science background를 가지고, system creation skill을 가지고있다. Data engineer가 갖추어야하는 tech skills에 대해 상세하게 알아보았다.
Data engineer은 data의 활용을 위한 data의 저장과 availability를 관리하는데에 필요한 거의 모든 task를 수행한다. 주요 task로는 data pipeline을 구축하는것이다. 이 pipline은 여러개의 다양한 source에서부터 받아오는 streaming & batch data를 소화하고, data의 활용도를 높이는 ETL(Extract, Transform, Load) 작업을 안정적으로 수행해야한다.
Data pipeline 구축은 크게 3단계로 나누어진다: Design - Build - Arrange.
-Design: big data infrastructure을 design하고 analyze될 수 있도록 준비한다.
-Build: pipelines를 구성하기위해 complex queries를 build한다.
-Arrange: 모든 problem들을 programmed system안에 arrange한다.
Data pipeline은 processing & analysis step들이 나열되는 sequence와 같다. 나열된 step들은 하나의 특정 목적을 이루기위해 data에 적용된다. 이런 pipeline은 production projects에 매우 유용하고, 또한 미래에 마주할 business question에 대한 답을 찾기위해 미리 data processing과 analysis를 진행하여서 시간과 cost를 save할 수 있는 목적으로도 유용하다. Pipline을 통한 data처리방식을 예를 들자면, 먼저 data의 outlier을 remove하고, dimensionality reduction technique을 적용한 후, 그 결과를 random forest classifier를 통해 매주 들어오는 dataset의 classification을 자동으로 얻을 수 있다. 이렇게 얻은 classification 결과물은 매주 축적되어 이후 business decision을 만드는데에 유용할게 활용될 수 있을것이다.
위 task들을 잘 수행하기위해서 data engineer는
-logical mind를 가지고,
-어떤 data를 extract할지 알고,
-관리 & 정리를 잘하고,
-cross functional team과의 협업을 잘 해야한다.
pipline을 통해 처리된 data는 data scientist 또는 data analyst의 analyses, processing 단계를 거치게되고, 결국 dashboard, reports, machine learning model에 적용된다.
Data scientist의 task는 크게 4가지로 구분된다: Analyse - test - create - present
Data scientist는 clean data를 다루고, available한 data를 사용하여 solution을 찾고, 분석한 결과를 team과 공유하여서 solution을 보정해나아가고 또는 새롭게 tackle할 problem을 찾는다.
위 task를 수행하기위해 data scientist는
-communicate을 잘하고,
-분석능력이 뛰어나고,
-타당한 가설을 잘 세우고,
-machine learning, data mining, statistics, big data infrastructure등에 관한 넓은 지식을 갖고있고,
-문제해결능력이 뛰어나야한다.
그리고 상황에 따라서 data engineer의 skill set또한 필요할 수도 있다.
Towards data science(@Medium)에서 가져온 2020년 data engineer job listing에서 요구하는 Top 30 기술이다:
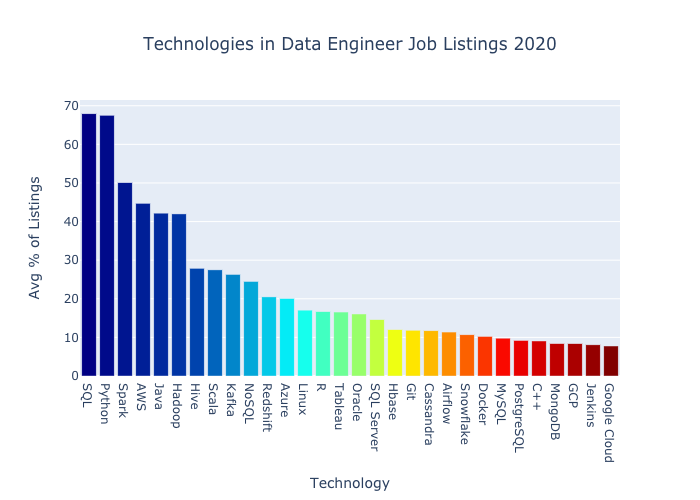 (by Jeff Hale based on scraped information from SimplyHired, Indeed, Monster job listings of 2020 in the U.S)
(by Jeff Hale based on scraped information from SimplyHired, Indeed, Monster job listings of 2020 in the U.S)
1. Python은 data, websites, scripting 관련 작업에 가장 많이 사용되는 언어로 분석되었다. 특히 beginner로서 basic python을 배운 후, pandas library를 먼저 master하는 것이 좋다. Pandas는 data cleaning, manipulating 작업에 많이 사용된다.
2. SQL은 relational database에서 사용하는 query 언어로서 아주 오랜시간동안 꾸준히 사용되고있다.
3. Spark(Apache)는 아주 큰 사이즈의 datasets와 일할 때에 유용하다. Spark는 "unified analytics engine for big data processing, with built-in modules for streaming, SQL, machine leanring and graph processing."
4. AWS는 Amazon's cloud computing platform으로서 현재 cloud platform 시장에서 가장 큰 marketshare을 가지고 있다.
5. Java(Oracle) & 6. Hadoop(Apache)
Hadoop은 MapReduce programming model과 함께 big data를 위한 server cluters를 사용한다.
7. Hive(Apache)는 data warehouse software이다. "Hive facilitates reading, writing, and managing large datasets residing in distributed storage using SQL."
8. Scala는 big data처리를 위해 많이 사용되는 프로그래밍 언어이다. (Spark was built with Scala)
9. Kafka(Apache)는 distributed streaming platform이다. Streaming data를 다룰 때에 주로 사용된다.
10. NoSQL database는 non-relational, unstructured, horizontally scalable database를 다룬다. Big data boom으로 인해 NoSQL의 활용도가 높아지고있다. 그러나 가장 보편적으로 많이 사용되는 database는 아직 RDB이다.
위에서 list한 top 10 technologies중에서 8개는 data engineer과 data scientist listing에서 공통적으로 확인된다 - SQL, Python, Spark, AWS, Java, Hadoop, Hive, Scala
아래 chart에서는 data engineer과 data scientist job listing에서 공통적으로 필요로하는 technologies의 빈도%를 비교하고 있다.
15 most common data engineer terms along with their prevalence in data scientist listings:
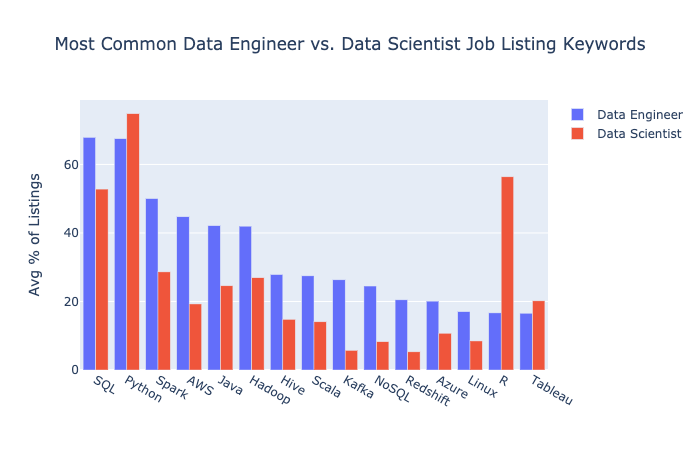 (by Jeff Hale based on scraped information from SimplyHired, Indeed, Monster job listings of 2020 in the U.S)
(by Jeff Hale based on scraped information from SimplyHired, Indeed, Monster job listings of 2020 in the U.S)
References:
1. Data Engineer vs. Data Scientist by Christopher Bolard from towards data science @Medium
2. Most In-Demand Tech Skills for Data Engineers by Jeff Hale from towards data science @Medium
