
Data Engineers
비즈니스 decision을 만들기위한 data processing에 필요한 infrastructure과 framework를 만들고 관리하는 역할을 수행한다. Data engineers는 BI(Business Intelligence) tool에 대한 이해가 깊고, 필요한 data를 쉽게 access할 수 있도록 database를 관리한다.
Data를 모으고, 변환하고, 보관하고, Data가 넓고 다양한 범위에서 활용될 수 있도록 준비하는 데에 필요한 일을 수행한다. Data engineer의 daily work routine에는 artificial intelligence를 개발하는 작업과 직접적인 연관은 적지만, organization의 AI-readiness 척도는 data engineer의 task를 통해 판단할 수 있다. Data science 또는 machine learning process가 진행되기위해 반드시 필요한 기반을 만드는 역할을 하기때문이다.
Data engineer에게 던져지는 질문들의 예시:
"다양한 ingestion/ serve rate을 감당하기 위해 어떤 타협점이 만들어져야하는지?"
"고객들에게 실시간 stream을 제공해야하는지?"
"어떻게 더 효율적이게 data query를 수행할 수 있을까?"
"Vital metrics를 어떻게 모니터 및 관리할 수 있을까?"Data engineers task에 필요한 basic skill set은 다음과 같다:
-SQL
-Python
-Cloud services(AWS, Google Cloud, etc)
-Java, Scala
-Database architecture concept (data modeling, data warehousing, etc)에 대한 이해
Basic skills에서 더 나아가서 Hadoop, Kafka, Spark, Tableau, ElasticSearch, Flink, Caassandra, Redshift와 같은 tool/framework도 사용할 줄 알아야한다. 그리고 어떤 tool을 사용해야지 적절한지를 판단하고 장,단점을 고려하여 production system에 구현해야한다.
Data engineer의 daily task는 새로운 project challenge를 해결하기위해 data system을 만들기, 현 architecture를 개선하고 maintain하기, 더 나은 방향으로 system을 개선해 나아가기위해 새로운 tool을 system에 통합하기, syncing with team members to ensure quality work & product flow, 등 이 포함된다.
Data engineer의 경력으로는 어떤 규모의 data를 처리해보았냐가 매우 중요하다. 더 큰 기업에서 큰 amount의 data를 다루어 보았다면 갖고있는 skill set과 experience의 수준이 더욱 높을 것이기때문이다.
Data engineer은 AI관련 project외에도 data process가 필요한 모든 작업에 꼭 필요한 specialist이다. Data engineer의 역할은 data infrastructure을 만드는것으로, 기업이 가장 effective하게 data를 처리하고 보관해서 미래의 project에 활용할 수 있도록 기반이되는 능력을 확보하는 것이다.
특히 big data project를 진행하기위해서는 여러 source들을 하나의 data warehouse로 연결시키는 data pipeline과 stream을 디자인하는 역할이 매우 중요하다. 많은 양의 다양한 종류의 data가 주어져도 여러 tool들을 사용하여 data를 처리하고, 하나의 data system으로 통합 될 수 있도록 해야한다.
예를 들어, 새(bird)의 소리 나 사진으로 새를 recognize할 수 있는 app에 필요한 data system를 생각해보자. 이 app의 database는 소리, 이미지, 등의 여러 종류의 data를 보관해서 neural network을 훈련시키고, data의 특징을 연결시켜서 원하는 새에 대한 정보를 찾아 user에게 전달해야한다. 이렇게 완전히 다른 형태의 data를 모아서 함께 처리하여 의미있는 결과물을 찾아내는 기술은 간단한 app에서부터 의료산업, 사회복지, 공공 sector, 제조업 등 여러 분야에서 활용 될 수 있다.
Data Scientist
Data scientist는 부분적으로 수학자이면서 컴퓨터 과학자이며, data analyst이다. Data engineer가 data solution의 architecture와 infrastructure을 제공하는 역할을 수행하는 동안, data scientist는 그 solution의 'soul'을 제공한다. 즉, solution의 model이나 algorithm을 만들어서 data가 원하는 방식으로 사용되어 자동으로 필요한 task가 수행될 수 있도록 하는것이다. 자동으로 필요한 data를 dataset에서 scrape하고 order할 수 있는 model을 제공한다.
Data scientist는 목표한 task가 수행될 수 있도록 data annotation과 model의 training을 진행한다. 어떤 기업에서 어떤 task를 목표하는지에따라 model training이 얼마나 정교하고 복잡해지 정해진다. 그래서 model을 training하는 작업은 하루안에 끝날 수 있는 간단한 작업에서 여러 주 동안의 지속적인 computing을 거쳐야하는 매우 복잡한 작업까지 variation이 크다.
또한, website또는 app에 적용하여 고객들에게 data를 기반의 서비스를 제공하는 제품을 만드는데에도 관여한다.(e.g., Facebook의 user-specific news feed 또는 LinkedIn의 "people you may know" 서비스)
기업의 내부 인원들 외에도 외부 관계자들과 함께 협업하며 비즈니스를 운영하는데에 직접적인 영향을 주는 문제에 답을 제시하기도 한다. 질문들의 예시:
"어떻게 우리 고객들을 더 잘 이해하고 더 나은 서비스를 제공할 수 있을까?"
"어떻게 우리 기업의 서비스 또는 제품을 최적화할 수 있을까?"
"왜 새로운 서비스 또는 제품을 출시해야하는가?"Data scientist task에 필요한 basic skill set은 다음과 같다:
-python guru: 거의 모든 data science는 python으로 진행된다.(python은 language중 가장 versatile하고 flexible하며 data processing과 statistical analysis에 중점을 두고있기때문에)
-python data science stack(e.g., NumPy, SciPy, pandas, scikit-learn, Statsmodels, etc)
-Deep learning frameworks (e.g., TensorFlow, Theano, Torch, Deeplearning4j, etc)
-Jupyter notebook으로 heavy analyses를 수행하고 여러 framework에서 data visualization을 만든다.
-AI development에 대한 research paper & analysis를 꾸준하게 숙지하고 최신 트랜드를 파악하고있어야한다. 가장 최신 top-notch model이나 component들은 현재 연구활동에서 사용되고있기때문에 관련 지식이 frseh할 수록 기업에게 관련 내용을 business outcome으로 적용할 수 있는 기회를 앞당기고 cost를 줄일 수 있다.
-solid mathematical background는 data scientist에게 매우 유용한 배경지식이다. (Math, physics, chemistry, 또는 다른 과학 분야의 background가 유용할 수 있다.)
-정교함과 끈기가 매우 중요한 덕목이다. 많은 노력을 쏟아부웠던 model이 결국 원하는 결과물을 제공하지 못하는 경우도 발생한다. 절망하지않고 실패속에서 새로 배울점을 찾고 다시 도전해가는 마인드 컨트롤이 중요하다.
Data scientist의 daily task는 cleaning & manipulating lots of data, scoping and testing out high ROI projects, building out customized algorithm, 기업 내부 및 외부(고객) 관련자들과 project의 결과물을 communicate하기, 등이 있다.
Data scientist는 data engineer와 비교해보자면 조금 더 spotlight을 받는 위치에있다. Data engineer가 data model이 제대로 동작하기위해 필요한 infrastructure과 architecture을 제공하고 사용할 수있는 data를 준비하는 backstage director 역할이라면, data scientist는 그 model과 neural network을 만들어서 solution을 제공하는 stage conductor 같은 역할을 하기때문이다. AI project를 보는 고객 또는 외부 관계자 입장에선 바로 data scientist의 역할만 눈에 들어올 수 있지만, data engineer & data scientist 각각의 역할과 두 그룹간의 collaboration이 잘 수행되야지만 project에서 의미있는 outcome을 얻을 수 있다.
Machine Learning Engineers
Data engineer와 data scientist의 역할을 합친 느낌이다. (DevOps가 coding + administration skill set을 모두 갖고있는듯이) Machine learning에 대한 extensive knowledge를 가지고 필요시 project을 혼자서도 진행 할 수 있는 능력을 갖고있다.
기업에서 machine learning engineer를 hire하는 목적은 주로 machine learning model의 implementation이다. Machine learning engineer는 data engineer가 만든 data architecture와 data scientist가 만든 model을 이해하고 이 둘을 함께 다루면서 business에 필요한 결과물을 구현해내는 역할을 수행한다.
Machine learning engineer task에 필요한 basic skill set은 다음과 같다:
-data engineer & data scientist의 주요 skill set이 모두 필요하다. (frameworks, programming, cloud tools, neural network training, evaluating models, etc)
-machine learning engineer은 고객의 needs를 파악해서 혼자서도 필요한 solution을 디자인하고 performance를 제공할 수 있어야한다. 그래서 지식과 경험을 통해 insight를 가지는것이 매우 중요하다.
Machine learning engineer은 data scientist가 만든 model을 개선해서 더 현실적인 방향으로 project에 구현될 수 있도록 리드한다. 그래서 Model과 algorithm에 대한 이해가 충분히 깊어야 한다. Algorithm이 project, infrastructure, 그리고 solution에 더 현실적으로 잘 맞도록 구현하는 역할을 수행한다.
About AI-related roles
AI professionals은 실제 기업에서 여러가지 title을 가지고있다: Deep Learning Engineer, Computer Vision Researcher, NLP Scientist, Machine Learning Engineer, etc...
위에서 언급한 machine learning engineer도 포함이 되는데, 이들의 공통점은 모두 specific problem을 해결하기위해 복잡한 최신 model을 만드는 역할을 담당한다는 것이다. 이런 역할을 수행하려면 탄탄한 engineering knowledge와 machine learning principles에 대한 깊은 지식이 필수이며 담당하는 팀이나 제품에 따라서 특정 분야 또는 tool을 다루는 강점을 가지는 것이 유리하다.
어떤 AI role은 연구에 더 집중해서 project에 더 적절한 model을 찾는데에 노력해야하고, 어떤 AI role은 model을 training시키고 monitoring해서 제품에 AI system을 구현하는것에 더 집중해야할 수도 있다. AI role이 맡게되는 project의 주제는 specific 질문을 중심으로 진행된다.
예시:
"시간이 오래 걸리고 복잡한 비즈니스 결정 process를 단축하기위해
어떻게 관련 대상의 전문지식을 요약할 수 있을까?"
"자동 고객 응답 시스템을 어떻게 더 실제 상담사와의 대화 같이 구현할 수 있을까?"
"새로운 형태의 streaming data를 어떻게 분석해서
숨어있는 패턴을 찾고 어려운 결정을 내리는데에 활용할 수 있을까?"Overlap
Data Landscape에서는 아래 그림과 같이 3가지 position의 overlap이 존재한다.
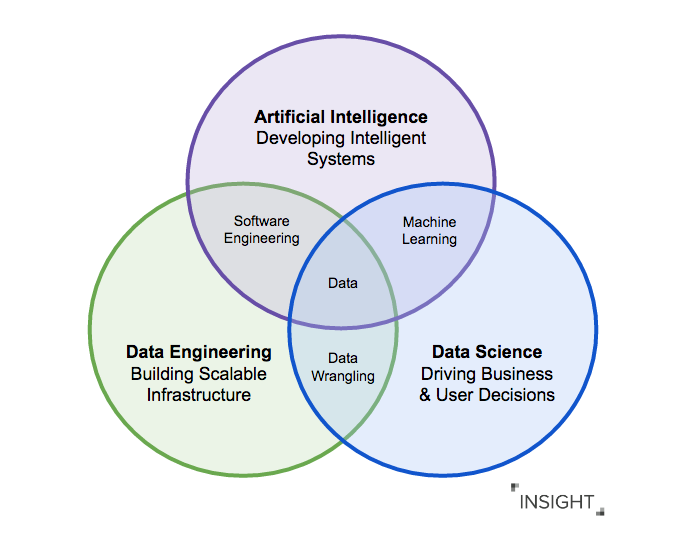
Data scientist role에는 최신 data engineering skill set이 필요할 때도 있고, data engineer role에는 점점 더 analyses와 machine learning을 pipline 구축 작업에 포함해야 하는 경우가 많아지고있다. Data scientist가 analyses를 수행하기 위해 사용하는 core idea 또는 knoweldge가 AI model을 만드는데에 핵심적인 역할을 맡기도 한다. 그리고 이런 model을 구축하고 활용하기 위해서는 아주 많은 양의 dataset이 필요한데, 대량의 data를 효율적이게 manipulate하고 사용하기위해서 data engineer의 역할이 중요하다. 가장 기반이 되는 탄탄한 data engineer의 역할이 state-of-the-art AI system을 만드는데에 필수적인 요소이다.
이렇게 위 3가지 역할은 긴밀하게 연관되어 있지만, 이들 사이의 fundamental한 차이점은 결국 AI project의 주목적이 무엇이냐에 따라 정해진다. AI system의 주목적은 human expert level 이상의 수준의 performance를 제공하기 위해 특정 domain의 knowledge와 feature을 생성해내는 intelligent system을 만드는 것이다. 이를 위해 필요한 model과 technique에 집중된 skill set이 구분된다. Model & technique을 함께 활용해서 frontier research의 발전 뿐만이 아니라 practical implementation 또한 가능해진다.
References:
- Hiring: Machine Learning Engineer vs. Data Engineer vs. Data Scientist from Ideamotive
- Data Engineers: The New Kings and Queens of Artificial Intelligence by Saket Saurabh from Nexla
- Will AI Assist Data Engineers or Replace Them? by Inna Tokarev Sela from Sisense
- How AI Careers Fit into the Data Landscape by Jeremy Karnowski from Insight [Medium]
