딥러닝과 정책 함수가 결합하면 강력한 정책 네트워크를 만들어 냅니다. 이번 챕터에서는 보상 및 밸류 네트워크를 이용해 직접적으로 정책 네트워크를 학습하는 방법에 대해 알아보겠습니다. 이는 수많은 최신 강화학습 알고리즘의 뿌리가 되는 방법론입니다.
9.3 액터-크리틱
- Actor-Critic : 정책 네트워크와 밸류 네트워크를 함께 학습하는 이론
Q 액터-크리틱
- ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)∗Qπθ(s,a)]
- REINFORCE 알고리즘은 여기서 Qπθ(s,a) 자리에 그 샘플의 리턴 Gt를 사용함
- Qπθ(s,a)를 리턴 Gt로 대체하지 않고 그대로 사용한것이 Q 액터-크리틱임
- Qπθ(s,a)는 미지의 함수이기 때문에, w로 파라미터화된 뉴럴넷 Qw(s,a)≈Qπθ(s,a)를 도입함
- 즉, θ로 파라미터화된 정책 네트워크 πθ와 w로 파라미터화된 밸류 네트워크 Qw 이렇게 2개의 뉴럴넷을 함께 학습함
- πθ는 실행할 액션 a를 선택하는, 즉 행동하는 액터(actor) 역할이고, Qw는 선택된 액션 a의 밸류를 평가하는 크리틱(critic) 역할임
- 에이전트의 학습 과정에서 정책 πθ와 밸류 Q를 모두 학습하는 방식을 액터-크리틱이라고 함
Q Actor-Critic pseudo code
- 정책, 액션-밸류 네트워크의 파라미터 θ와 w를 초기화
- 상태 s를 초기화
- 액션 a∼πθ(a∣s)를 샘플링
- 스텝마다 다음(A~E)을 반복
- A. a를 실행하여 보상 r과 다음 상태 s'을 얻음
- B. θ 업데이트: θ←θ+α∇θlogπθ(s,a)∗Qw(s,a)
- C. 액션 a′∼πθ(a′∣s′)를 샘플링
- D. w 업데이트: w←w+β(r+γQw(s′,a′)−Qw(s,a))∇wQw(s,a)
- E. a←a′,s←s′
- 정책 네트워크 πθ와 밸류 네트워크 Qw가 함께 학습됨
- 핵심은 θ를 업데이트할 때 실제 보상 값이 전혀 쓰이지 않고 오로지 크리틱 Qw에 의존하여 학습이 이루어지는 점임
어드밴티지 액터-크리틱
- ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)∗Qπθ(s,a)]
- ∇θlogπθ(s,a)은 벡터이고, Qπθ(s,a)는 스칼라 값임 (상태 s에서 액션 a를 하고 얻게 되는 리턴의 기대값)
- 여기서 문제가 애초에 s'이 매우 좋은 상태일경우, s'에서 어떤 액션을 택하든 이후에 얻게 되는 리턴이 높은 상황이됨
- ex) Q(s′,a0)=1000, Q(s′,a1)=1050 인 상황
- 이때 policy gradient 식을 이용해 업데이트하면 둘 다 비슷하게 강화됨.
- a1이 근소하게 크기 때문에 확률차이가 발생하긴하는데 그러기 위해서는 수많은 샘플을 필요
- 샘플을 무한히 많이 모아서 계산하면 해결할 수 있긴 하지만 “효율적인가”하는 부분에서는 고민을 해야함
- 즉, s'에서는 a0보다 a1이 더 좋은 액션인데 둘 다 강화됨
- ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)∗{Qπθ(s,a)−Vπθ(s)}]
- 위와 같이 모든 상태에서 업데이트할 때, 각 상태의 밸류인 Vπθ(s)를 빼서 해결함
- Qπθ(s,a)−Vπθ(s)는 상태 s에 있는 것보다 액션 a를 실행함으로써 “추가”로 얼마의 가치를 더 얻게 되는 것인지를 의미함 → 이 값을 어드밴티지(advantage) Aπθ(s,a)라고 함
- Aπθ(s,a)≡Qπθ(s,a)−Vπθ(s)
- Vπθ(s)를 기저(baseline) 라고 함
- 상태 s에 도착하는 사건은 이미 벌어진 일이기 때문에 주어진 것으로 받아들이고, 거기서 액션 a를 했을 때 현재보다 미래가 어떻게 변화하는 가를 통해 액션의 확률을 수정하는 것
- Vπθ(s)를 빼도 되는가?
- 기존 수식에서 Vπθ(s)를 뺄 수 있으려면 다음이 성립해야함
Eπθ[∇θlogπθ(s,a)∗Qπθ(s,a)]
=Eπθ[∇θlogπθ(s,a)∗{Qπθ(s,a)−Vπθ(s)}]
=Eπθ[∇θlogπθ(s,a)∗Qπθ(s,a)]−Eπθ[∇θlogπθ(s,a)∗Vπθ(s)]
즉, Eπθ[∇θlogπθ(s,a)∗Vπθ(s)]=0
증명
- 사실 Vπθ(s)를 빼도 괜찮을 뿐만 아니라 상태 s에 대한 그 임의의 함수를 빼도됨
- 어떤 함수가 액션 a에 대한 함수가 아니기만하면 됨
- 상태 s에 대한 임의의 함수를 B(s)라고 할때, B(s)는 상태 s를 넣었을때 숫자 값 하나를 리턴하는 함수임
- Vπθ(s)는 B(s)의 특별한 경우
- 상태 s에 관한 임의의 함수 B(s)에 대해 다음이 성립함
- Eπθ[∇θlogπθ(s,a)∗B(s)]=0
- 먼저 상태 분포(state distribution) dπ(s)를 정의
- 상태 분포는 정책 π를 따라서 움직이는 에이전트가 각 상태에 평균적으로 머무는 비율을 나타내는 분포 → 즉, 정책 π가 정해져야 정의될 수 있는 분포임
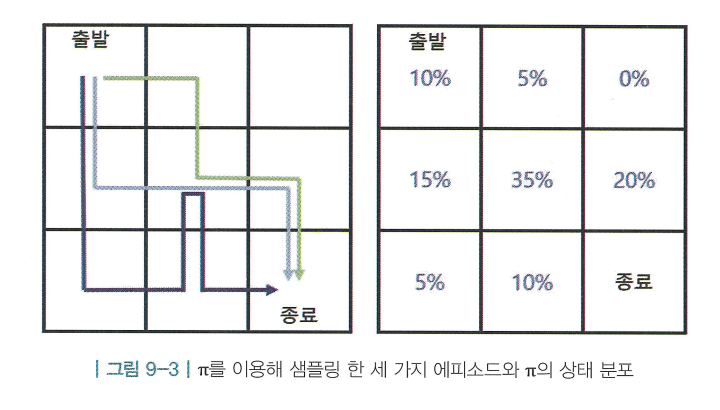
- 어떤 정책 π를 이용해 움직이는 에이전트를 출발점에 놓고 종료 상태에 도착할 때까지 그 경로를 총 3번 그린것 → 상태별 방문 빈도를 나타낸 것이 dπ(s)임
- 이 상태 분포 dπθ(s)를 이용해 기존에 구했던 기댓값을 풀어 쓸 수 있음
- 이 dπ(s)는 1-스텝 MDP의 d(s)와 같음 → 1-스텝에서는 시작하는 상태에서 바로 종료 상태로 가기 때문에 시작하는 상태의 분포가 곧 dπ(s)이기 때문
- Eπθ[∇θlogπθ(s,a)∗B(s)]=∑s∈Sdπθ(s)∑a∈Aπθ(s,a)∇θlogπθ(s,a)∗B(s)
- 존재하는 모든 상태에 대해 각 상태에 있을 확률과 각 상태에서 어떤 액션을 선택할 확률을 곱하여 더해줌 (기대값의 정의)
- 증명
∑s∈Sdπθ(s)∑a∈Aπθ(s,a)∇θlogπθ(s,a)∗B(s)
=∑s∈Sdπθ(s)∑a∈Aπθ(s,a)πθ(s,a)∇θπθ(s,a)∗B(s)
=∑s∈Sdπθ(s)∑a∈A∇θπθ(s,a)∗B(s)
=∑s∈Sdπθ(s)B(s)∑a∈A∇θπθ(s,a)
=∑s∈Sdπθ(s)B(s)∇θ∑a∈Aπθ(s,a)
=∑s∈Sdπθ(s)B(s)∇θ1
= 0
∴Eπθ[∇θlogπθ(s,a)∗B(s)]=0
- 어드밴티지 액터-크리틱의 Policy gradient는 다음과 같게 됨
- ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)∗Aπθ(s,a)]
- Aπθ(s,a)=Qπθ(s,a)−Vπθ(s)
- 어드밴티지를 사용하여 policy gradient를 계산하면 분산이 줄어들어 훨씬 안정적인 학습이 가능함
- Qπθ≈Qw , Vπθ≈Vϕ(s)
- 실제 가치 함수를 알 수 없기 때문에 뉴럴넷을 이용하여 근사함
- 즉, 학습을 위해선 3개의 뉴럴넷을 필요함
- 정책 함수 πθ(s,a)의 뉴럴넷 θ
- 액션-가치 함수 Qw(s,a)의 뉴럴넷 w
- 가치 함수 Vϕ(s)의 뉴럴넷 ϕ
Advantage Actor-Critic pseudo code
- 3쌍의 네트워크 파라미터 θ, w, ϕ를 초기화
- 상태 s를 초기화
- 액션 a∼πθ(a∣s)를 샘플링
- 스텝마다 다음(A~F)을 반복
A. a를 실행하여 보상 r과 다음 상태 s'을 얻음
B. θ 업데이트 : θ←θ+α1∇θlogπθ(s,a)∗{Qw(s,a)−Vϕ(s)}
C. 액션 a′∼πθ(a′∣s′)를 샘플링
D. w 업데이트: w←w+α2(r+γQw(s′,a′)−Qw(s,a))∇wQw(s,a)
E. ϕ 업데이트: ϕ←ϕ+α3(r+γVϕ(s′)−Vϕ(s))∇ϕVϕ(s)
F. a←a′,s←s′
- 즉, 정책 네트워크와 밸류 네트워크, 액션-밸류 네트워크가 함께 학습함
TD 액터-크리틱
- Q 액터-크리틱에 비해 어드밴티지 액터-크리틱은 그라디언트 추정치의 변동성을 줄여줌으로써 학습 효율에 이점이 있지만, πθ, Vϕ, Qw 이렇게 3쌍의 뉴럴넷을 필요로 하기 때문에 구현이 복잡하고 학습이 오래걸리는 단점이 존재함
- V(s)의 TD 에러 δ는 다음과 같음
- δ=r+γV(s′)−V(s)
- 여기서 상태 s에서 어떤 액션 a를 실행했을 때 δ의 기댓값을 계산하면
- Eπ[δ∣s,a]=Eπ[r+γV(s′)−V(s)∣s,a]
=Eπ[r+γV(s′)∣s,a]−V(s)
=Q(s,a)−V(s)=A(s,a)
- 즉, TD 에러인 δ의 기댓값이 어드밴티지 A(s,a)와 동일함
- δ는 A(s,a)의 불편 추정량(unbiased estimate)임
- δ 값은 같은 상태 s에서 같은 액션 a를 선택해도 상태 전이 확률에 따라 매번 다른 값을 얻는데, 이 값을 모아서 평균내면 그 값이 A(s,a)로 수렴한다는 뜻임
- ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)∗δ]
- δ는 상태 가치 함수 V만 있으면 계산할 수 있는 값이기 때문에 Q가 없어도 계산이 가능함
TD Actor-Critic pseudo code
- 정책, 밸류 네트워크의 파라미터 θ와 ϕ를 초기화
- 액션 a∼πθ(a∣s)를 샘플링
- 스텝마다 다음(A~E)을 반복
A. a를 실행하여 보상 r과 다음 상태 s'을 얻음
B. δ를 계산: δ←r+γVϕ(s′)−Vϕ(s)
C. θ 업데이트: θ←θ+α1∇θlogπθ(s,a)∗δ
D. ϕ 업데이트: ϕ←ϕ+α2δ∇ϕVϕ(s)
E. a←a′,s←s′
Summary
∇θJ(θ)
=Eπθ[∇θlogπθ(s,a)∗Qπθ(s,a)]# Policy Gradient Theorem
=Eπθ[∇θlogπθ(s,a)∗Gt]# REINFORCE
=Eπθ[∇θlogπθ(s,a)∗Qw(s,a)]# Q Actor Critic
=Eπθ[∇θlogπθ(s,a)∗Aw(s,a)]# Advantage Actor Critic
=Eπθ[∇θlogπθ(s,a)∗δ]# TD Actor Critic
- 앞의 ∇θlogπθ(s,a)까지는 같고 뒤에 어떤 값이 곱해지느냐에 따라 차이가 생김
- policy gradient : 실제 가치 함수인 Qπθ를 사용하여 계산하면 그것이 곧 목적 함수 J(θ)의 그라디언트와 같음을 이용
- REINFORCE : 리턴 Gt가 Qπθ의 샘플이었기 때문에 Gt를 대신 사용
- Q Actor-Critic : Qπθ 자리에 뉴럴넷을 이용해 학습한 Qw를 사용
- Advantage Actor-Critic : Q Actor-Critic에서 그라디언트 추정치의 분산을 줄이고자 Advantage(Aw)를 사용
- TD Actor Critic : δ가 Advantage의 샘플임을 이용하여 δ를 대신 사용
