(SBERT는 깊게 다루지 않고 지식의 확장 정도로만 설명하고 넘어가겠습니다)
SBERT(SentenceBERT)
- SBERT : BERT를 기반으로 sentence embedding vector를 생성하는 모델
- SBERT (SentenceBERT) > SentenceTransformers로 이름이 바뀜
- sentence embedding vector 생성 방법
1) [CLS] 토큰의 임베딩 벡터를 문장 벡터로 사용
2) BERT의 모든 출력 벡터에 대해서 평균값을 구하여 문장 벡터로 사용
→ 모든 단어의 의미 반영 → “default”
3) BERT의 모든 출력 벡터 중에서 최대값을 구하여 문장 벡터로 사용 → 중요한 단어의 의미 반영
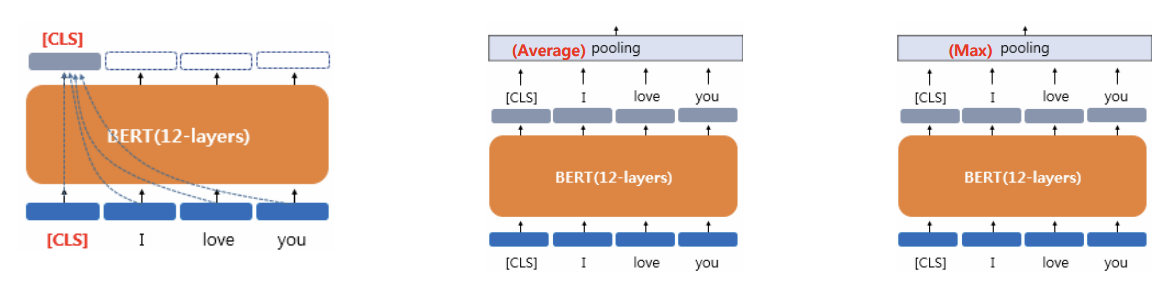
- 임베딩 벡터의 차이가 곧 성능차이로 연결됨
- 용도
- 두 문장 간의 유사도 계산
- 문장 간의 유사도를 이용한 검색 엔진이나 ChatBot 개발 등에 활용
+ 문장 하나 == 임베딩 벡터, 임베딩 벡터의 묶음 == 임베딩 행렬
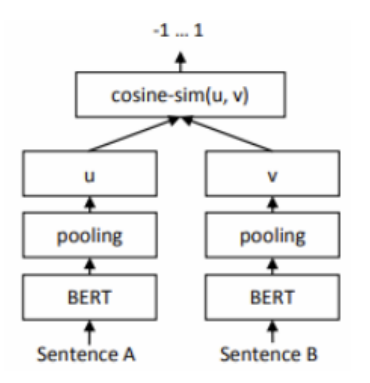
SBERT(SentenceBERT)를 이용한 문장 유사도 측정
- SBERT(SentenceBERT)를 이용한 문장 유사도 측정
- 사전 훈련된 한국어 SBERT 모델 객체 생성하기
- 문장 임베딩 벡터 생성
- 코사인 유사도 측정
- 문장 유사도를 이용한 추천시스템
- CountVectorizer와 코사인 유사도를 이용한 추천시스템
- SBERT와 코사인 유사도를 이용한 추천시스템
SentenceTransformer
- all-MiniLM-L12-v2 모델
- 미니로 축소화한 모델 기본 Transformer차원인 768의 절반인 384차원임
- 데이터 전처리 불필요
- encode함수를 활용 (BERT의 encode 함수와 기능이 다름)
- 문장을 그대로 임베딩 벡터로 만들어줌
- paraphrase-multilingual-mpnet-base-v2
- 다국어 모델
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
# 필요한 라이브러리 설치
!pip install sentence-transformersSentenceTransformer를 이용한 문장 유사도 측정 Code 1 (영어 문장 유사도 측정)
# 함수 임폴트
from sentence_transformers import SentenceTransformer
# pretrained model 생성
model_name="all-MiniLM-L12-v2"
model_eng=SentenceTransformer(model_name)
# 유사도 측정을 할 텍스트 데이터 생성
en_sentences = ["What should I do to be a great scientist?", "How can I be a good scientist?"]
# 문장 임베딩 행렬 생성
en_embeddings = model_eng.encode(en_sentences)
print(en_embeddings.shape)# 필요한 함수 임폴트
from sklearn.metrics.pairwise import cosine_similarity
# 1차원 배열 > 2차원 배열로 변환
em1 = en_embeddings[0,:].reshape(1,384)
em2 = en_embeddings[1,:].reshape(1,384)
# 코사인 유사도 측정
sim1 = cosine_similarity(em1, em2)
sim2 = cosine_similarity(en_embeddings, en_embeddings)
print(sim1)
print(sim2)SentenceTransformer를 이용한 문장 유사도 측정 Code 2 (한글 문장 유사도 측정)
# 한국어로 fine-tuning된 SentenceTransformer모델 생성
model_name='ddobokki/klue-roberta-base-nli-sts'
model_ko=SentenceTransformer(model_name)
# 유사도 측정을 할 텍스트 데이터 생성
ko_sentences1 = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?", "무단 퇴사한 직원에 대한 손해 배상 청구가 가능한가요?"]
ko_sentences2 = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?", "오늘도 날씨가 매우 덥고 소나기가 내리는 등 동남아 날씨같아요."]
# 문장 임베딩 행렬 생성
ko_embeddings1 = model_ko.encode(ko_sentences1)
ko_embeddings2 = model_ko.encode(ko_sentences2)
print(ko_embeddings1.shape)
print(ko_embeddings2.shape)# 1차원 배열 > 2차원 배열로 변환
em11 = ko_embeddings1[0,:].reshape(1,768)
em12 = ko_embeddings1[1,:].reshape(1,768)
em21 = ko_embeddings2[0,:].reshape(1,768)
em22 = ko_embeddings2[1,:].reshape(1,768)
# 코사인 유사도 측정
sim11 = cosine_similarity(em11, em12)
sim12 = cosine_similarity(ko_embeddings1, ko_embeddings1)
sim21 = cosine_similarity(em21, em22)
sim22 = cosine_similarity(ko_embeddings2, ko_embeddings2)
print(sim11)
print(sim12)
print()
print(sim21)
print(sim22)SentenceTransformer를 이용한 문장 유사도 측정 Code 3 (다국어 문장 유사도 측정)
# 텍스트 데이터 생성
sentences = ['What should I do to be a great scientist?', '훌륭한 과학자가 되려면 어떻게 해야 할까요?']
# 모델 생성
model_name='paraphrase-multilingual-MiniLM-L12-v2'
model_mul = SentenceTransformer(model_name)#임베딩 행렬 생성
embeddings = model_mul.encode(sentences)
print(embeddings.shape)
# 1차원 배열 > 2차원 배열로 변환
em1 = embeddings[0,:].reshape(1,384)
em2 = embeddings[1,:].reshape(1,384)
# 코사인 유사도 측정
sim1 = cosine_similarity(em1, em2)
sim2 = cosine_similarity(embeddings, embeddings)
print(sim1)
print(sim2)문장 유사도를 이용한 추천 시스템 Code 1 (영화 데이터파일경로 설정 및 전처리)
# 라이브러리 임폴트
import pandas as pd
# 파일 경로 설정
file_path = '/content/drive/MyDrive/NLP/movies_metadata.csv'
# DataFrame 생성
df = pd.read_csv(file_path)# 영화 소개(overview), 제목(title) 컬럼 추출 > 팬시 인덱싱
df1 = df.loc[:,['overview', 'title']]
# 누락 데이터 제거 > dropna()
df2 = df1.dropna(ignore_index=True)
# data의 수를 10000개로 축소
df_data = df2.iloc[0:10000,:]
df_data문장 유사도를 이용한 추천 시스템 Code 2 (SentenceTransformer 모델 생성)
# 사전 학습된 SentenceTransformer 모델 생성
model_name='all-MiniLM-L12-v2'
model = SentenceTransformer(model_name)# overview 컬럼 추출 > 입력 데이터 생성
sentences = df_data.loc[:, 'overview'].values
print(sentences)
# encode 함수 호출
embeddings = model.encode(sentences)
print(embeddings.shape)문장 유사도를 이용한 추천 시스템 Code 3 (코사인 유사도 측정)
# 10000개의 영화 소개글에 대한 코사인 유사도 측정
# 함수 임폴트
from sklearn.metrics.pairwise import cosine_similarity
# 코사인 유사도 측정
sim = cosine_similarity(embeddings, embeddings)
print(sim)
print()
print(sim.shape)- sklearn cosine similarity
- 2차원 배열일 때만 사용이 가능
# index, column 설정
movie_index = df_data.loc[:,'title'].values
movie_columns = df_data.loc[:,'title'].values
# 코사인 유사도 측정의 결과 > DataFrame 생성
df_sim = pd.DataFrame(data=sim, index=movie_index, columns=movie_columns)
# 결과 확인
df_sim# 특정 영화 선택 > 코사인 유사도를 내림차순으로 정렬
# 특정 영화 선택 > 특정 컬럼 추출(인덱싱) > 컬럼의 값을 내림차순으로 정렬 > top_n 추출
n = 10
df_sim.loc[:,'Toy Story'].sort_values(ascending=False).iloc[1:n+1]문장 유사도를 이용한 추천 시스템 Code 4 (영화 추천 함수 생성)
# 특정 영화 기준 > 줄거리가 유사한 영화 추천 함수 생성
def recommend_topn(title, n):
top_n = df_sim.loc[:,title].sort_values(ascending=False).iloc[1:n+1]
return top_n# 영화 추천 함수 실행
title = 'GoldenEye'
n = 10
recommend_topn(title, n)참고 자료

AI & Robotics