밀집 표현(dense representation)
- 단어나 문장을 0이 아닌 일정한 크기의 실수로 표현하는 방법
- 0이 아닌 실수로 표현
- 희소 표현보다 벡터크기가 작아져 메모리 소모가 적음
① 적은 크기의 백터로도 다양한 종류의 문장 / 단어 표현이 가능
② 컴퓨터의 메모리 절약과 효율적 사용이 가능

word2vec
- 개념 : 주변에 사용된 이웃 단어가 비슷한 / 단어들이 비슷한 숫자를 갖도록 함
- 문장이 아닌 단어를 임베딩함
- BoW은 단어의 등장 빈도로만 표현하여 순서나 문맥이 고려되지 않지만, word2vec는 고차원 벡터로 모두 고려하여 벡터를 생성함
- 분포 가설을 바탕을 함
- 분포 가설 : 주변에 사용된 단어가 비슷한 단어들이 비슷한 의미를 갖는다
- 문맥(context) : 단어의 앞뒤 연결
- 예시
- 나는 어제 사과를 먹었다
- 나는 어제 피자를 먹었다
=> Word2Vec 알고리즘은 이러한 단어들의 관계를 학습하여, “사과”와 “피자”가 비슷한 숫자를 갖도록 한다- 종류
- CBOW
- skip-gram
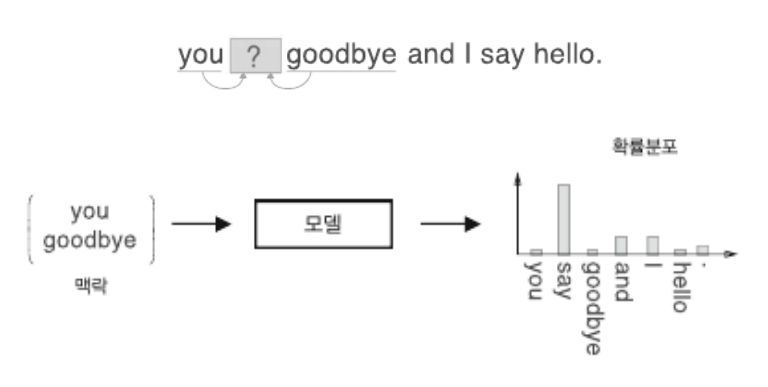
word2vec : CBOW(Continuous Bag of Word)
- 주변에 있는 단어들을 입력으로 / 중간에 있는 단어를 예측하는 모델
- 기본구조는 얕은 신경망(shallow neural network)
- 깊은 신경망은 은닉층이 굉장히 많음 (얕은 신경망은 1개)
word2vec : skip-gram 모델
- 중간에 있는 단어들 → 입력 → 주변에 있는 단어들을 예측하는 모델
(skip-gram 모델은 이론을 깊게 다루지 않고 CBOW와의 차이점을 비교하기 위해 코드로만 작성하였습니다)
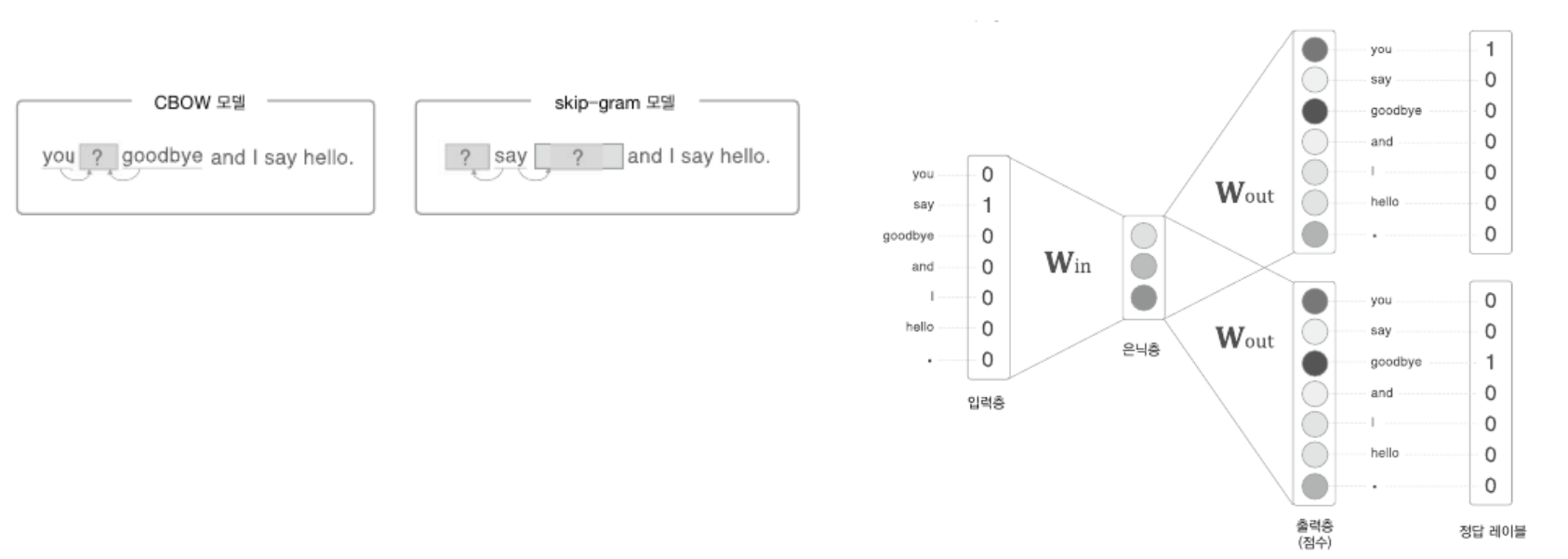
CBOW 모델 기본 구조 : 얕은 신경망(shallow neural network)
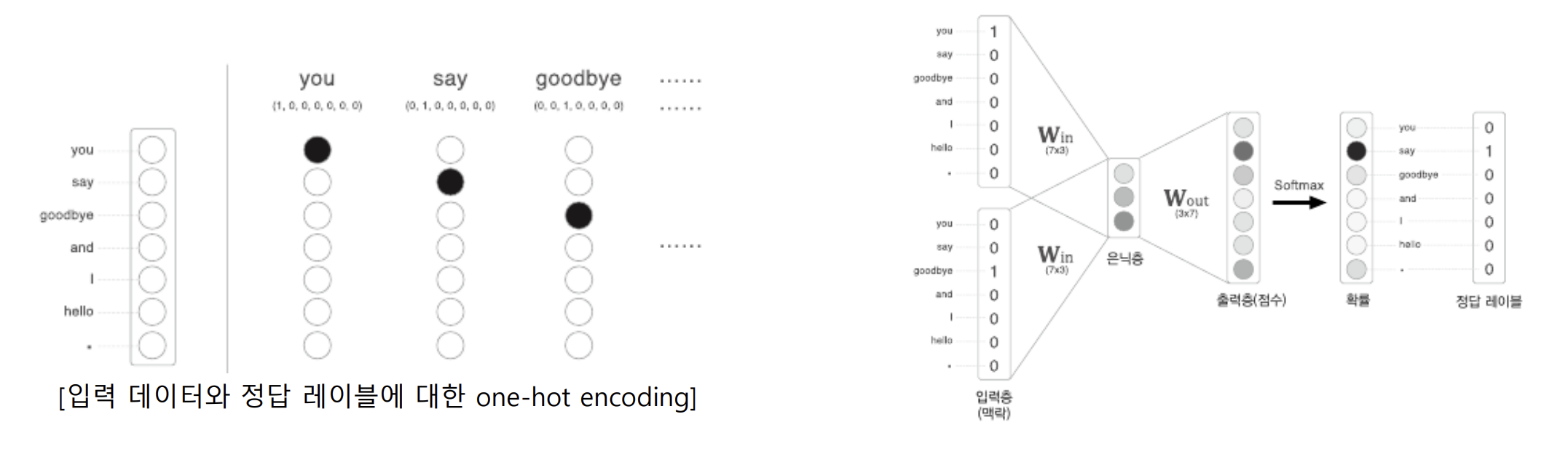
- 단어들을 고유한 희소표현으로 인덱스를 설정함 (입력층)
- 문맥 단어 원핫 벡터(One-hot Vector)로 변환하여 입력(Input Layer)
- 윈도우의 크기(예측을 위한 활용 범위)가n일때, 활용하는 단어의 수 는 2n개
- 입력된 원핫 벡터는 가중치 행렬과 곱해져 고정된 크기의 임베딩 벡터로 변환 (은닉층)
- 모든 문맥 단어의 임베딩 벡터를 평균하여 하나의 벡터로 결합함
- 모델의 예측을 위한 정보로 사용됨 (Projection Layer)
- 단어 집합(vocabulary) 내에서 타겟 단어의 확률 분포를 계산 (출력층)
- 출력 레이어는 소프트맥스(softmax) 함수를 사용함
- 가장 높은 확률을 가진 단어가 예측 결과로 출력
- 학습 결과 : 가중치 update → 학습이 완료된 가중치 → 임베딩 벡터(단어 사전)
- 입력층과 은닉층의 관계 : y = X(2,7) ⅹ (7,3) → 행렬 곱
- 은닉층과 출력층의 관계 : z = y(1,3) ⅹ (3,7) → 행렬 곱
- CBOW 학습과정 요약
- 윈도우 크기에 따라 입력노드 개수 결정됨
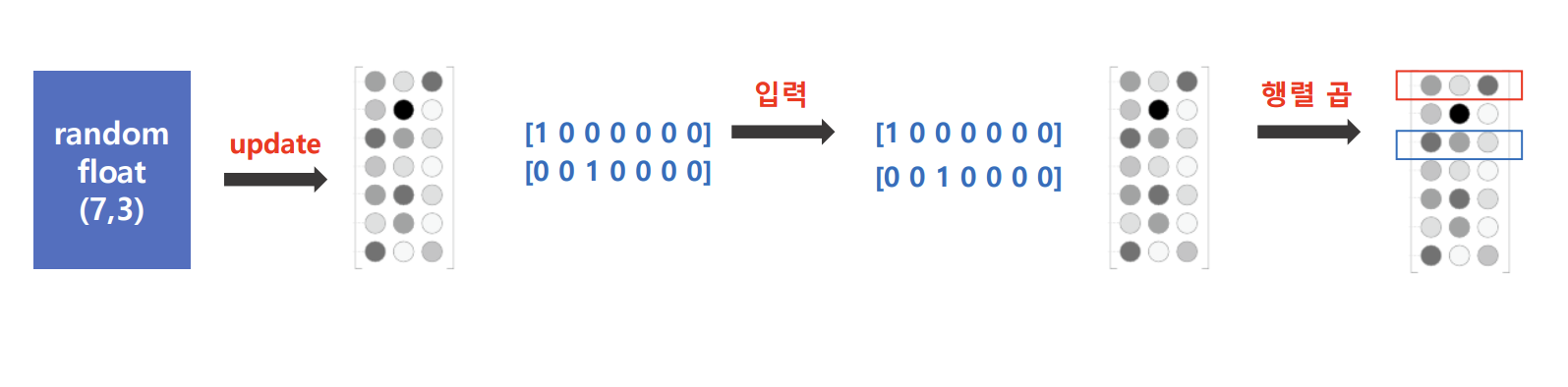
- 입력값을 원 핫 벡터로 변경후 랜덤한 가중치가 곱해짐 (행렬 곱 기반)
- 은닉층에서 평균을 냄 (백터 내적 기반)
- 은닉층의 출력값을 원 핫 벡터의 크기와 맞추기 위해 랜덤한 출력 가중치를 곱합
- 정답 행렬과 비교를 통해 가중치를 계산해 나감 == “학습”
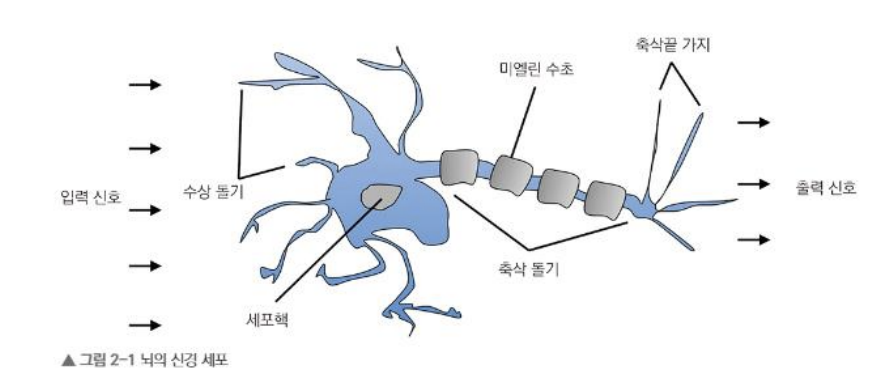
(보충) 퍼셉트론(perceptron)
- 퍼셉트론(perceptron) - 인공뉴런, 논리회로
1) perceive → perception
2) 신경세포 → neuron
3) perception + neuron → perceptron(인공 뉴런, 논리 회로)
4) perceptron(인공 뉴런) 정의 : 다수의 입력 신호를 받아서 하나의 신호를 출력하는 인공 뉴런 (인공 신경망의 기초)
5) 가중치(weight) : 뉴런의 출력 신호를 낼 지 말지를 결정하기 위해 입력 신호에 곱하는 계수 → 신경세포체에서 합쳐진 신호가 특정 임계 값을 넘을 지 말지를 결정
- 입력 레이어 (Input Layer)
- 데이터를 수집하는 역할, 각 입력은 특정 값을 가짐
- 가중치 (Weights)
- 입력 데이터에 대해 가중치를 곱하여 가중 합계를 계산함. 입력의 중요도를 조절하는 파라미터이며, 학습 과정에서 조정이 가능함
- 활성화 함수 (Activation Function)
- 가중 합계에 대해 활성화 함수를 적용하여 최종 출력을 결정함. 주로 계단 함수(Step Function)를 활용하여 특정 임계값(threshold)을 넘으면 1을 출력하고, 그렇지 않으면 0을 출력함
- 출력 (Output)
- 최종적으로 활성화 함수의 결과를 출력. 퍼셉트론은 이진 분류 문제를 해결하는 데 사용됨
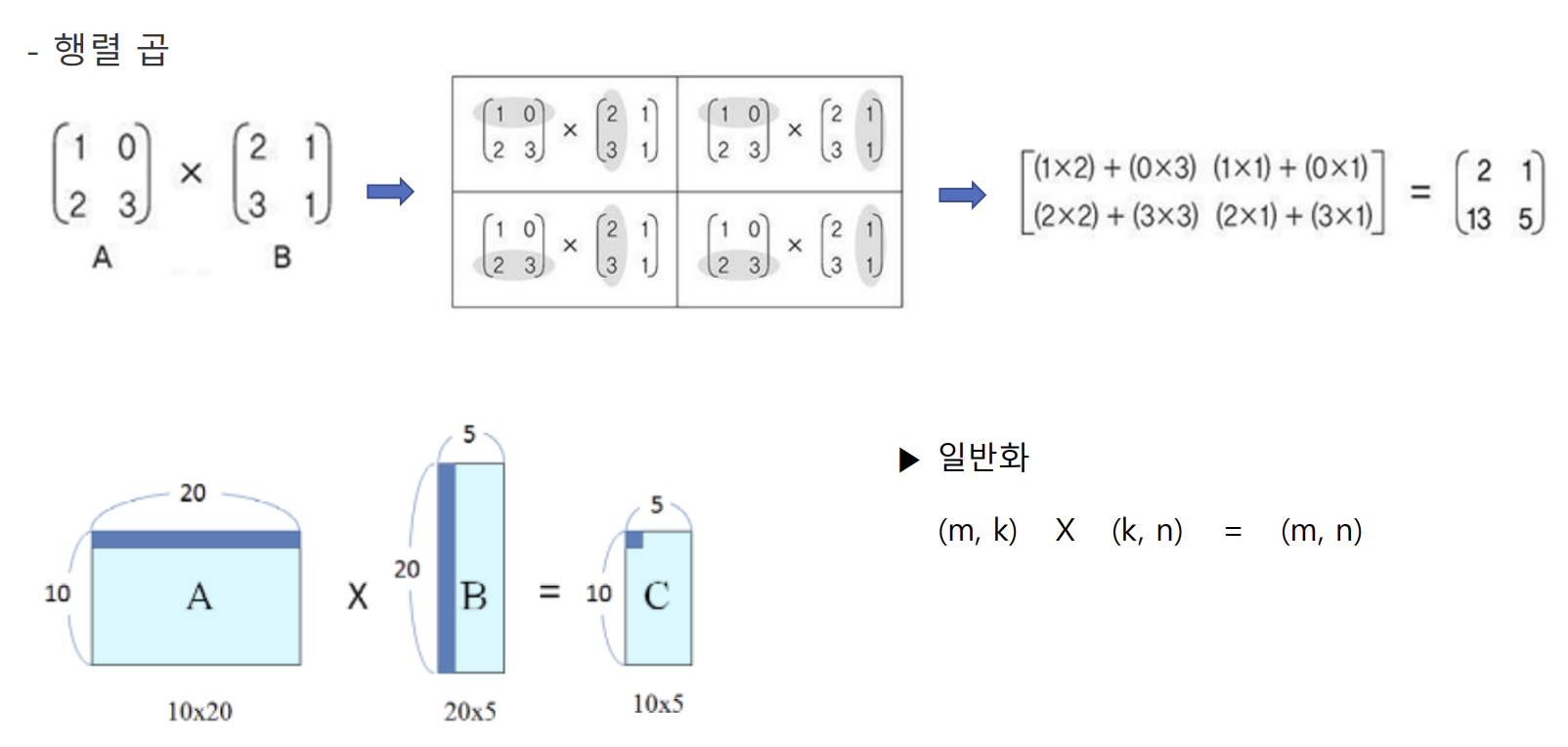
(보충) 행렬 곱 / 벡터 내적
- 행렬 곱 - 결과도 행렬. 두 행렬의 크기에 따라 결과 행렬의 크기가 결정됨
- (m, k) X (k, n) = (m, n) (일반화) - k가 같아야만 함
- 백터 내적 - 결과는 스칼라(단일 숫자)임
+ CBOW 연산 과정 분석
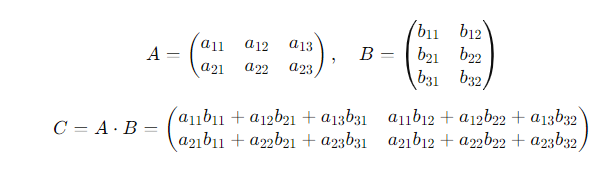
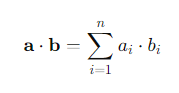
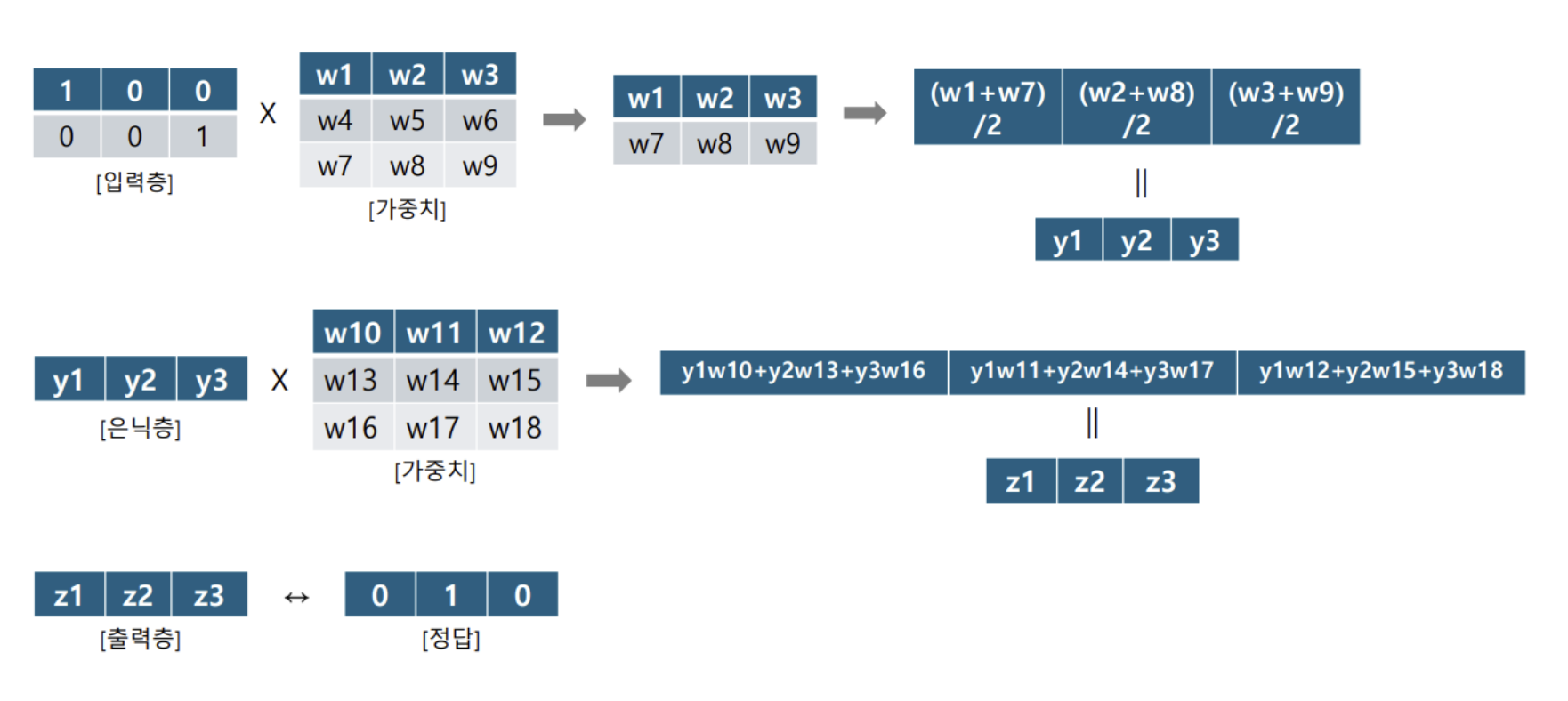
+ CBOW 신경망 구조 (심화)
- 입력층의 개수 - 윈도우의 크기에 따라 정해짐
- 은닉층의 개수 - 모델에 따라 직접 정함
- CBOW 신경망 구조
- 입력층
- 예측하려는 단어의 주변 단어들이 문맥단어로 사용됨
- 각 문맥 단어들은 원 핫 인코딩 방식으로 벡터표시됨 =>
- 입력층의 노드의 개수는 윈도우 크기에 따라 달라짐
- 은닉층 (1개일때)
- 원 핫 벡터()와 가중치 행렬()이 곱해져 임베딩 벡터가 생성됨 =>
- 각 은닉층의 노드의 임베딩 벡터들을 평균하여 하나의 벡터로 결합함 =>
- 벡터 가 은닉층의 최종 결과로 출력됨
- 출력층 (1개일때)
- 벡터 를 바탕으로 타겟 단어를 예측함
- 출력 벡터 를 소프트 맥스 함수를 통해 변환하여 중심 단어일 확률을 계산함
- 출력층에서 단어 집합()에 있는 모든 단어에 대해 확률 분포를 계산하여 가장 높은 확률을 가진 단어를 중심 단어로 예측함
- 출력가중치()가 있어야 하는 이유
- 결과값으로 확률계산하여 정답 레이블을 추측하기 위해선 원 핫 벡터와 모양이 같아야 하기 때문
- 은닉층의 노드가 많아질수록 모델의 표현력(복잡한 데이터 패턴을 학습할 수 있는 능력)이 증가하지만, 과적합의 위협도가 증가하여 적절한 기법을 활용하여 방지해야함
(수학적인 표현들은 추후 RNN에서 더 자세하게 다루겠습니다)
참고자료

AI & Robotics