(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Instruct GPT
InstructGPT Code - GitHub
(*참고 : openAI API 없으면 작동 안함)
State-of-the-art Large Language Models
- Language Models are Few-Shot Learners
- Prompting : instruction과 input을 어떻게 쓸 지를 설계해서 원하는 output을 유도하는 방법
- Zero-shot Prompting : 아무런 instruction없이 input만 주는것
- Few-shot prompting : Prompt 안에 (input, output) 예시들을 추가해주는 것
- Prompting도 Learning으로 봄
- In-context learning : context안에 있는 설명만으로 새로운 task를 수행할 수 있게 하는것
- ChatGPT는 여러 training을 추가하여 사용됨
- GPT-3 + (SFT, RLHF) = InstructGPT
- 왜 추가적인 작업이 필요한가? → LLM이 misalignment되어있기 때문에
- LLM은 generate하지 않거나, unhelpful하거나, untruthful 혹은 toxic한 생성을 하면 안되는데, 추가적인 training이 없으면 “follow the user’s instructions helpfully and safely”라는 목표에 적합하지 않게됨
- 핵심은 misalignment → alignment로 바꾸는 작업 (ex- hallucination)

- Labelers-based data와 User-based data를 모두 사용하여 Dataset을 Construction함
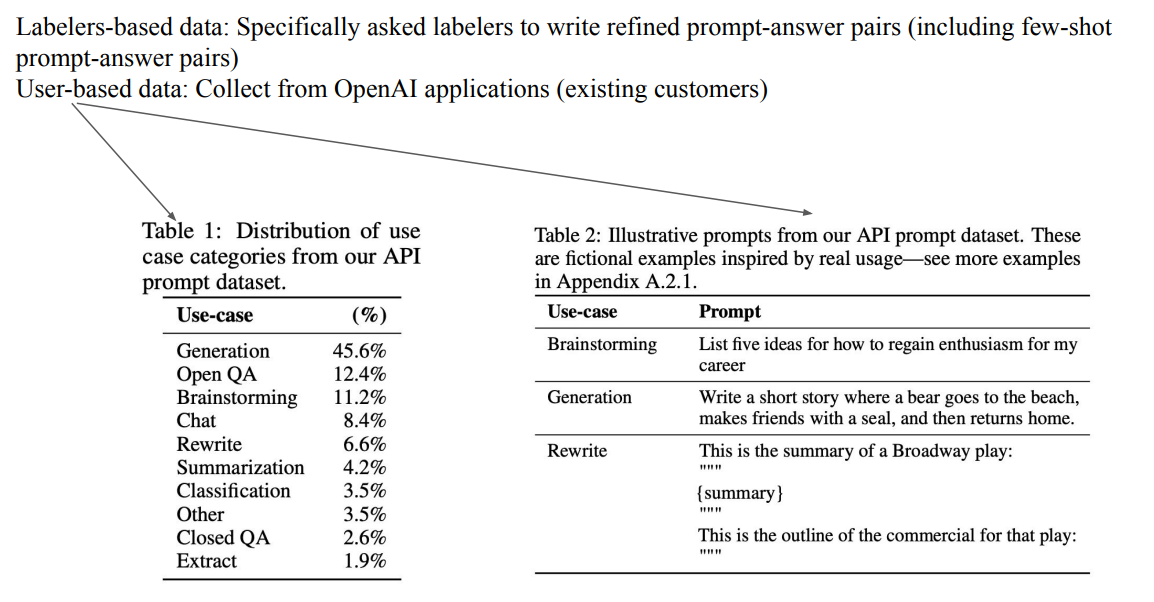
- SFT : 특정 query에 대한 answer를 잘 generative하게끔 training하는 것
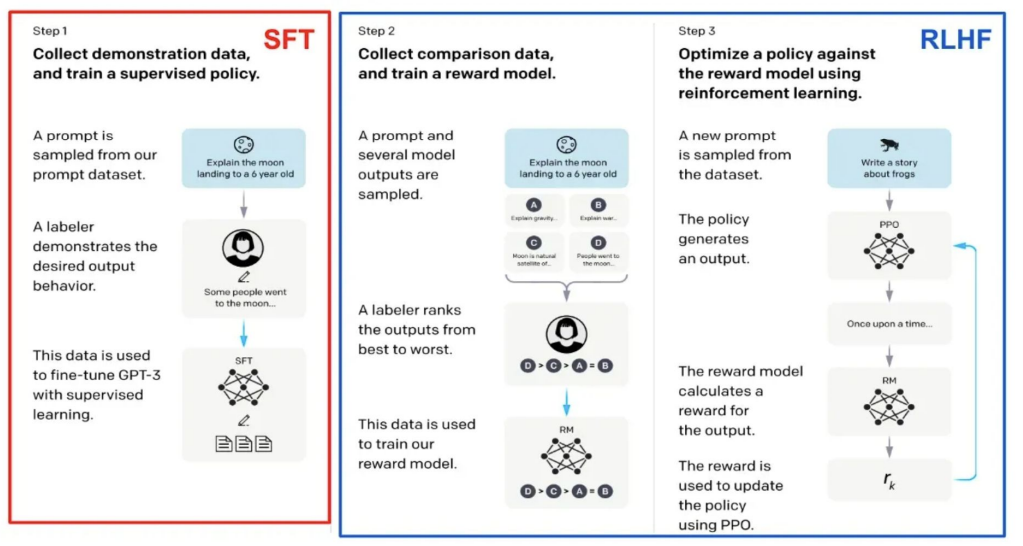
RLHF (Reinforcement Learning Human Feedback Paper)
- 크게 PPO vs DPO로 나뉨
- PPO (Proximal Policy Optimization)
- PPO는 policy(여기선 language model)를 fine-tuning하는 trainer(optimizer) 역할을 하며, Reward Model(RM)이 높게 점수 주는 출력을 더 잘 만들어 내도록 모델을 조정함.
- RM이 준 reward와 현재 language model의 출력을 받아서, 이 reward를 극대화하는 방향으로 모델 파라미터를 iterative하게 업데이트함.
- 안정성 (KL penalty)
- fine-tuned 모델과 원래 pretrained 모델 사이의 분포 차이를 KL-divergence term으로 측정해서, 너무 멀리 벗어나지 않도록(regression 방지) regularization을 걸어줌.
- PPO-PTX (PPO with Pretrained Transformer Cross-Entropy)
- KL-divergence만으로는 pretrained 모델과의 거리를 충분히 통제하지 못할 수 있음.
- 현재 모델과 original pretrained 모델 사이에 cross-entropy loss를 추가로 걸어서, fine-tuning 동안 언어 모델이 원래 pretrained LM의 분포에서 너무 멀어지지 않도록 한 번 더 강하게 regularization 하는 방식.
- PPO-PTX = PPO(RLHF) + “pretrained LM와 비슷하게 말하게 만드는 CE loss” 를 더한 버전.
- RLHF를 쓰지않고 SFT만 쓰게 되면 overfitting됨

- Reward Model을 어떻게 학습하는가가 매우 중요함 → 너무 어렵고 오래걸림


- Evaluation metrics for InstructGPT
- 모델의 유용성(helpful or Appropriateness)
- 모델의 진실성(Truthfulness)
- 모델의 유해성(Toxicity)
- 참고) hugging face에서 LLM을 불러올땐 미리 신청하고 토큰을 발급받아야함

- 참고자료
HFRL Optimization
- Proximal Policy Optimization Algorithms
- PPO
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- DPO → PPO가 하던걸 RL없이 loss로 구현한 방법
- ARES: Alternating Reinforcement Learning and Supervised Fine-Tuning for Enhanced Multi-Modal Chain-of-Thought Reasoning Through Diverse AI Feedback
- ARES → PPO에 검수하는 teacher를 추가한 방법
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- GRPO → PPO를 Group별로 묶은 방법
- Perception-Aware Policy Optimization for Multimodal Reasoning
- PAPO → Visual Feature를 더 잘 이해할 수 있게 하기 위해 PPO에 LOSS term을 추가한 방법

AI & Robotics