(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Retrieval Augmented Generation (RAG)
LoRA Code - GitHub
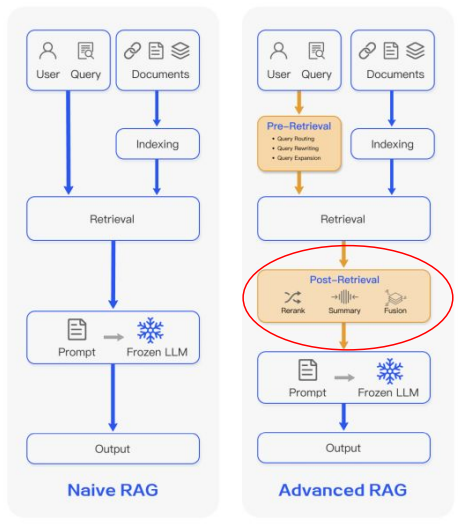
Enhancing RAG with Post-Retrieval Processing
- Retriever가 가져온 문서들을 그대로 LLM에 넣지 않고, 한 번 더 가공해서 품질을 올리는 단계
- Reranking(정확도 높은 순으로 재정렬), 필터링(중복·무관 문서 제거), chunk 병합/분할, 요약·하이라이트 생성 등을 통해 LLM이 볼 context를 더 짧고, 관련성 높고, 정보 밀도 높은 형태로 만들어 주는 것
Reranking (i.e., Relevance Estimator) (RE-RAG, EMNLP 2024)

Knowledge Refinement using Summarization and Reranking (RankCoT, ACL 2025)

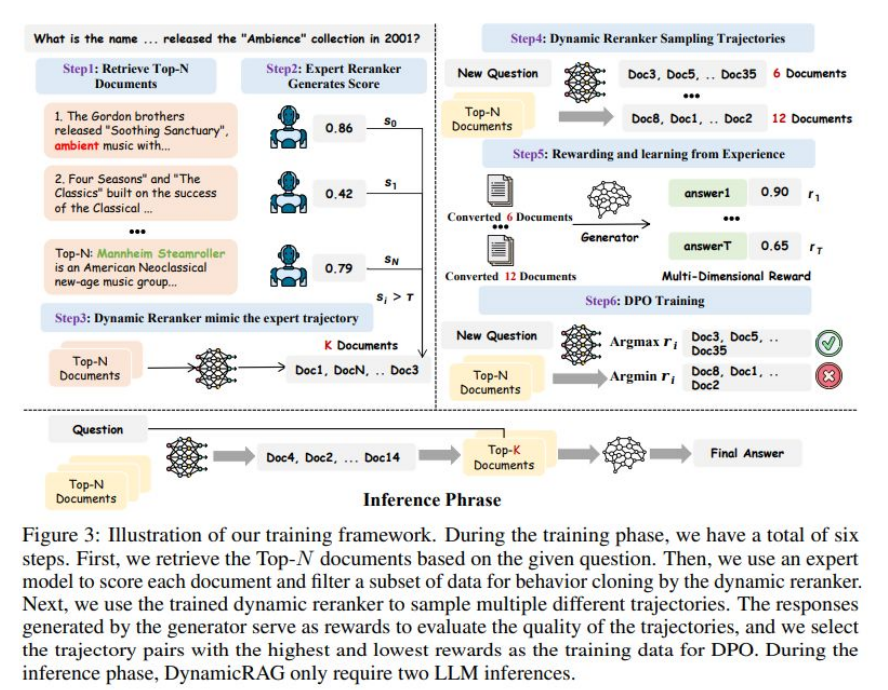
Advanced Reranker (DynamicRAG, Neurips 2025)
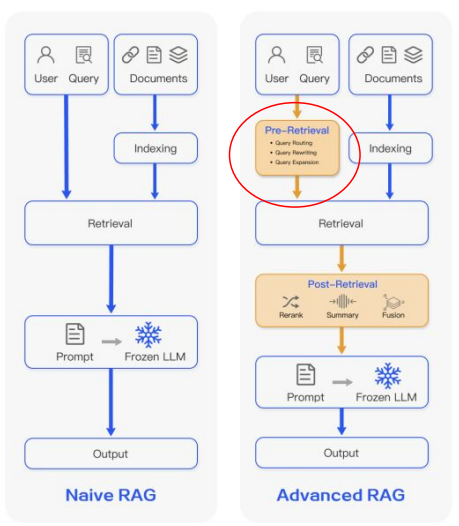
Enhancing RAG with Pre-Retrieval Processing
- 사용자의 raw query를 바로 검색하지 않고, retriever가 이해·매칭하기 좋은 형태로 사전 가공하는 단계
- Query normalization: 소문자 변환, 불용어 제거, 토큰 정규화 등
- Query rewriting / expansion: LLM으로 질문을 풀어서 쓰기, 동의어·관련 키워드 추가, 애매한 표현 명확화
- Query decomposition / routing: 복잡한 질문을 여러 sub-question으로 나누거나, 알맞은 index·도메인으로 라우팅
- 이런 pre-retrieval processing을 통해 retriever가 더 관련성 높은 문서들을 찾을 수 있게 만들어 RAG 전체 성능을 향상시킴.

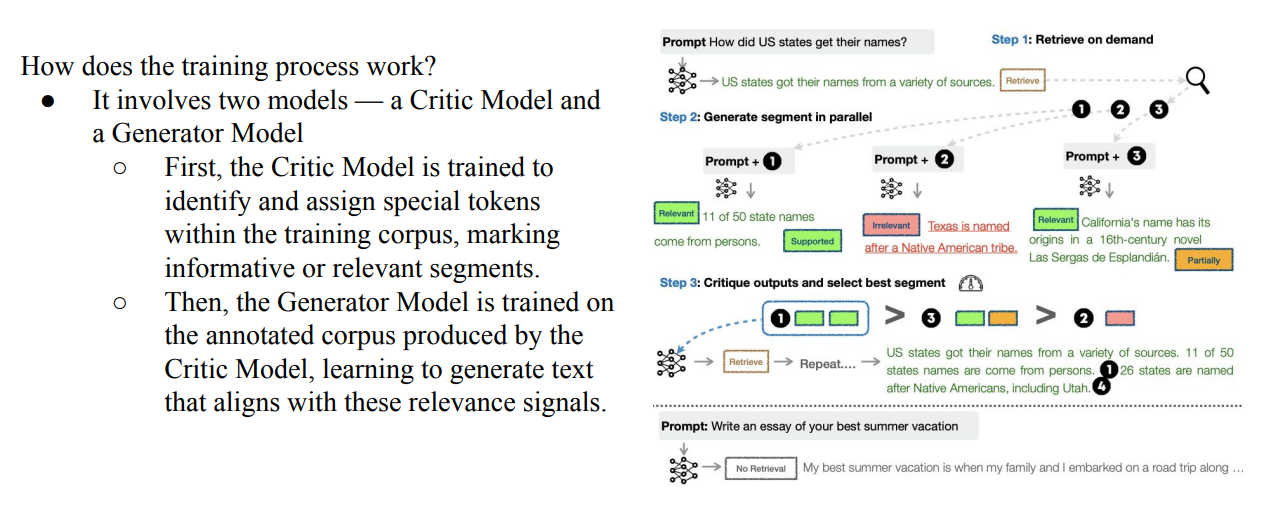
Enhancing the Generator in RAG → Generator자체를 향상시키는것도 방법임
Reflection-based RAG (Self-RAG, ICLR 2024)
Noisy Robustness of RAG LLMs (ACL 2024)
PA-RAG (NAACL 2025)
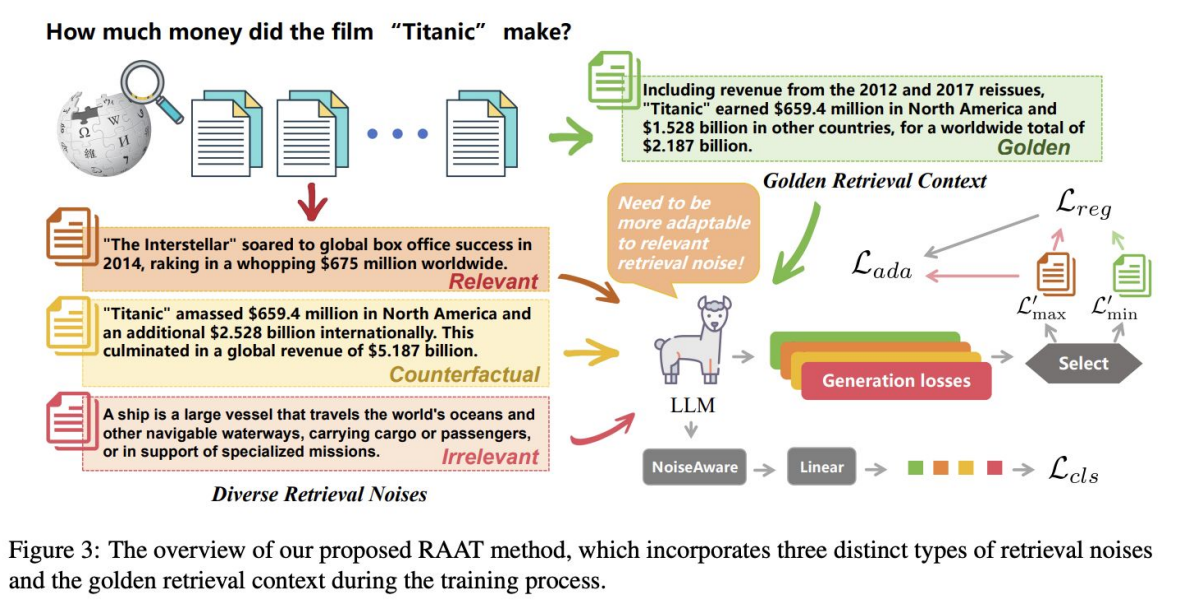

RAG for Specialized Domains (RAG-Studio EMNLP findings 2024)

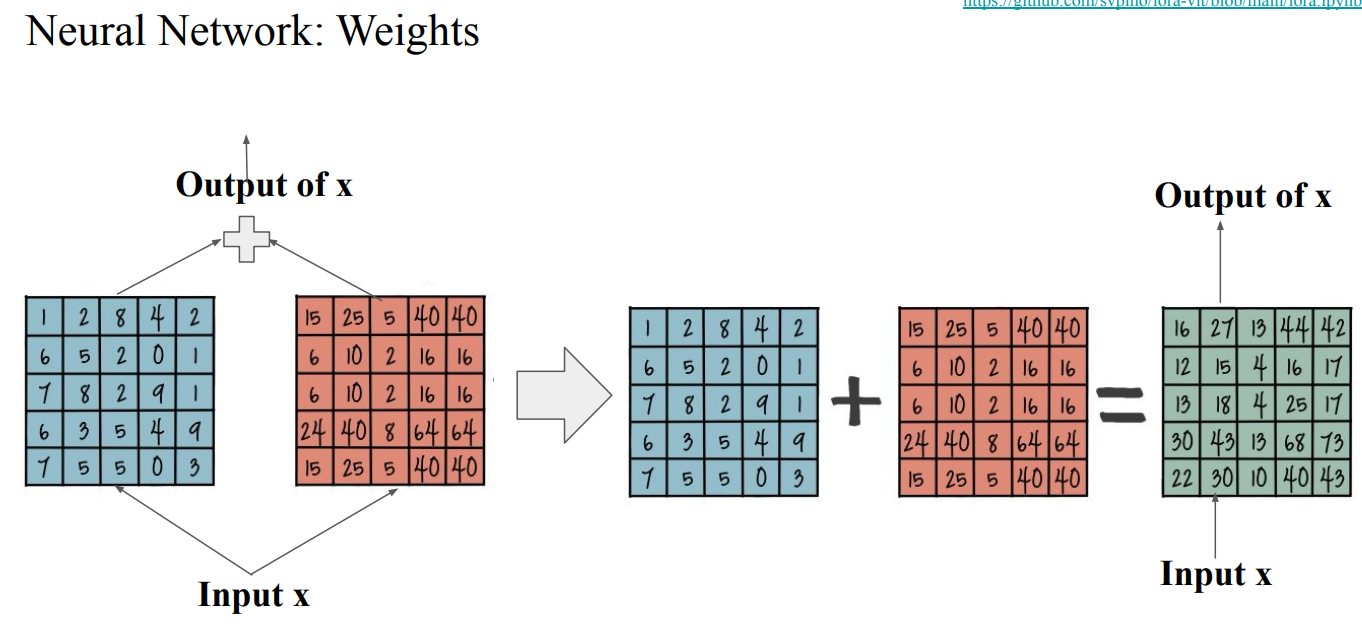
Low Rank Adaptation (LoRA)
- Zero Inference Latency
- 기존엔 input 마다 추가로 계산해야함
- W1이 설정된 이후엔 Only one-time addition이 가능
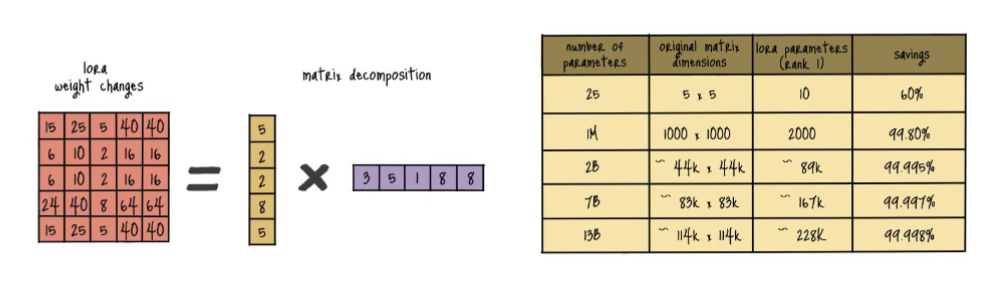
- 전체 weights를 Full Fine-tuning하는 대신, 적은 수의 파라미터만 학습하고도 동일한 효과를 보임
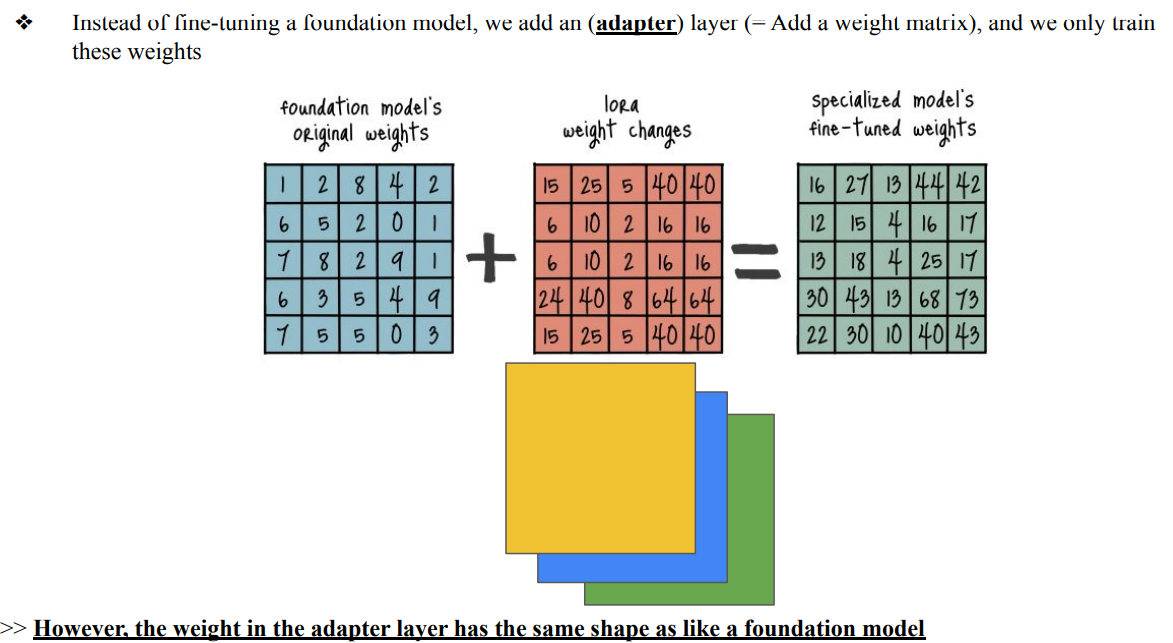
Adapter Layer
- Foundation Model's Original Weights
- pre-trained model의 원래 weight metrics
- LoRA fine-tuning 과정에서 이 weight metrics은 Frozen 상태로 유지되며, 업데이트되지 않음
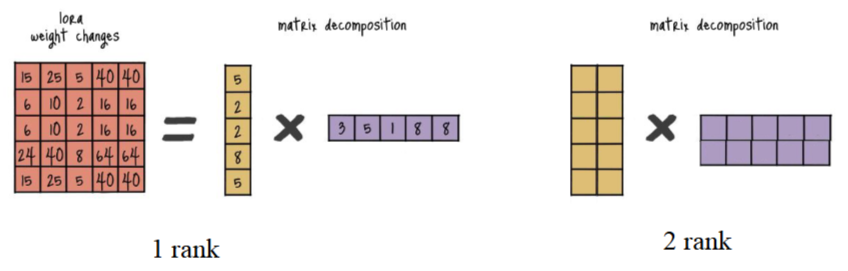
- LoRA Weight Changes
- 특정 작업을 학습하며 얻은 weights의 변화량
- Specialized Model's Fine-tuned Weights
- 원래 가중치()와 학습된 변화량()을 더하여 만들어진 Output weight metrics(W)
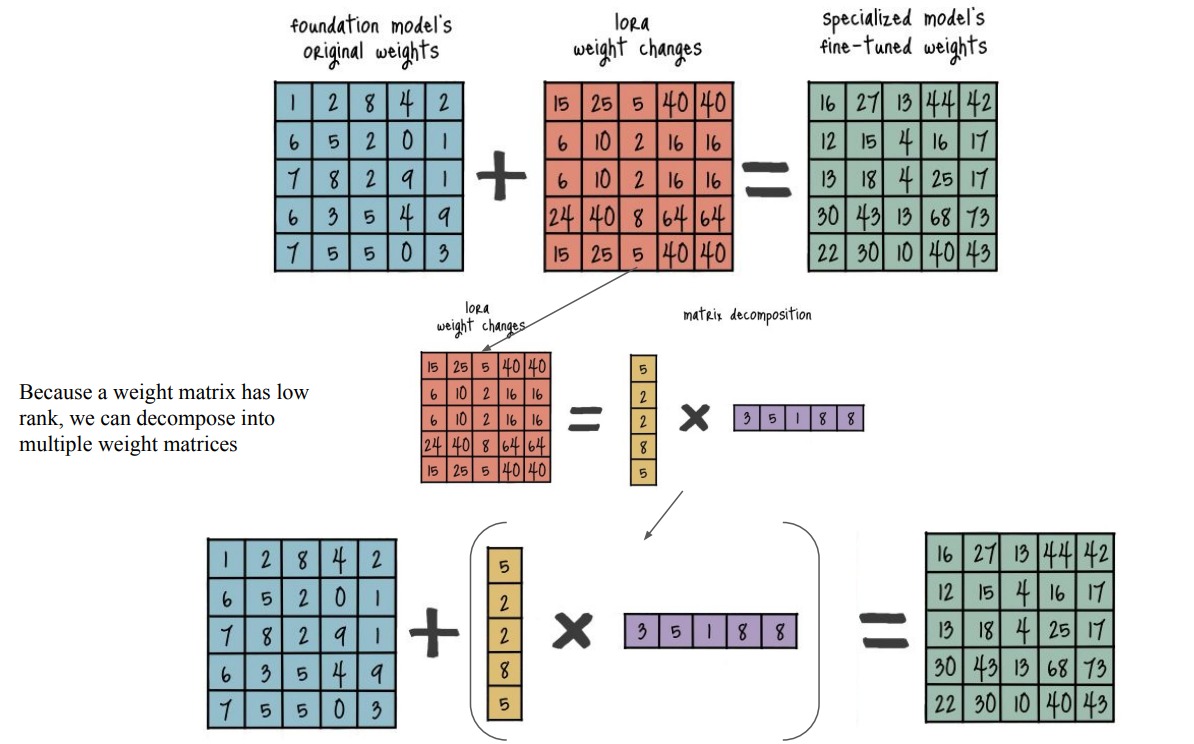
Low Rank Adaptation (LoRA)
- LoRA의 핵심은 weight metrics를 그대로 학습하는 대신, multiple weight metrics로 decomposition하여 학습 파라미터 수를 줄이는 것임.
LoRA : Rank
- Rank(r)는 분해된 두 행렬 사이의 중간 차원을 의미함
- rank를 8에서 256 사이로 설정할 때 Approximation 성능에 유의미한 차이가 없음
- 즉, 모델의 특징을 학습하는 데 Low Intrinsic Rank만으로도 충분함
끝!

AI & Robotics