(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU)
LSTM&GRU Code - Github
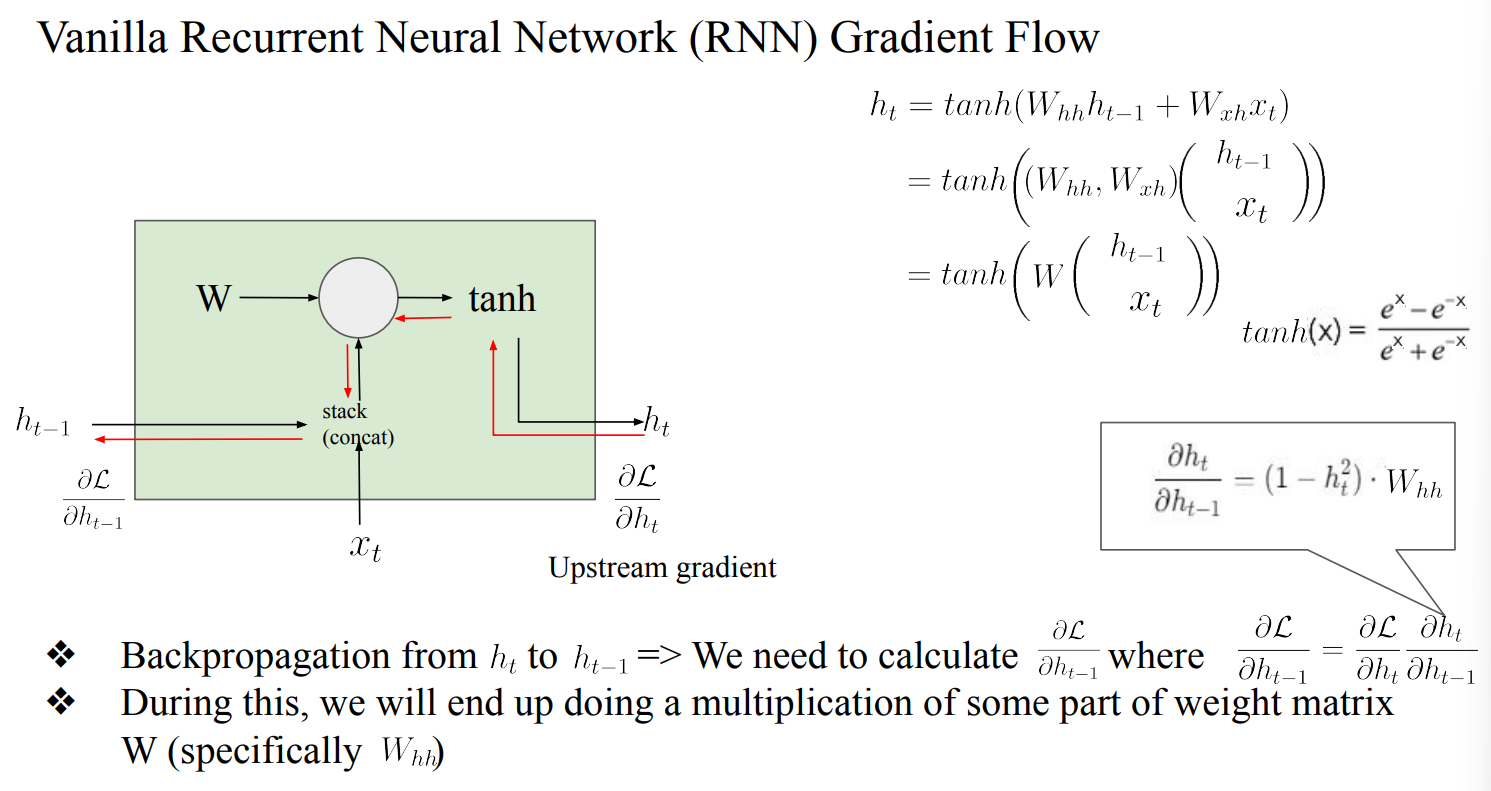
RNN
- Gradient를 통해 update를 진행해야 하는데, flow상 Gradient가 폭발하거나 없어져서 Gradient 소실이 발생함
- W_hh가 지속적으로 곱해지기 때문에 무한히 작아지거나, 무한이 커짐
- Solution 1 : Gradient Clipping
- Gradient의 범위를 정해서 소실을 최소화함 → task마다 너무 다름
- Solution 2 : Change RNN architecture → Long Short Term Memory (LSTM)

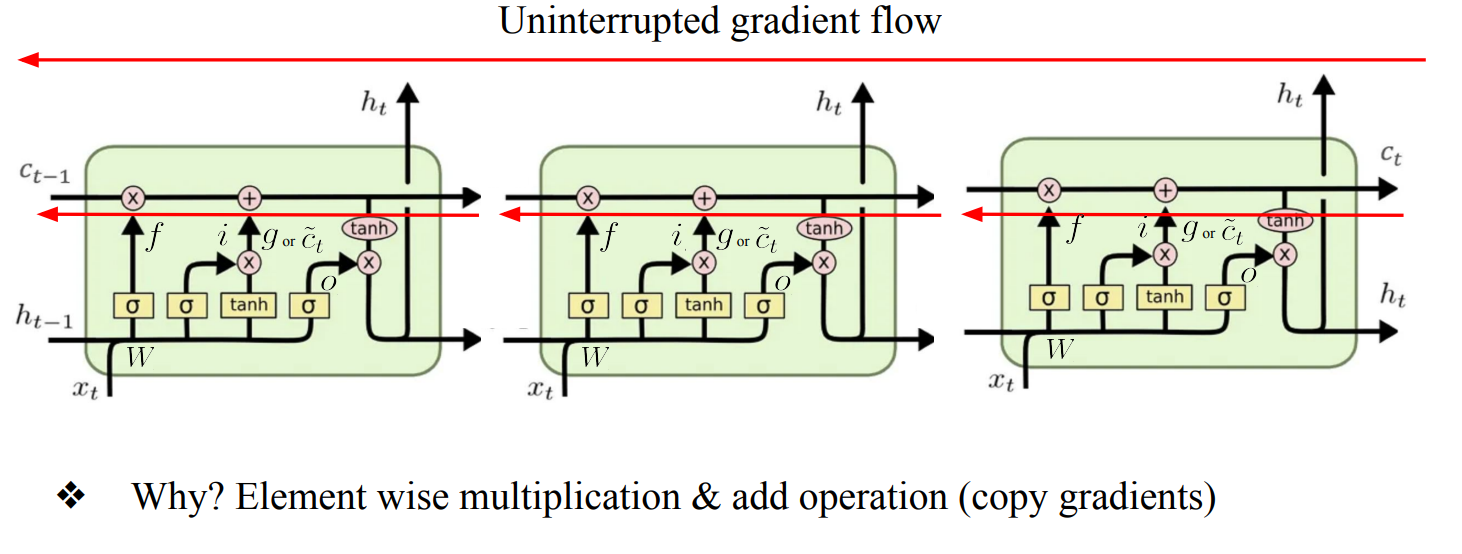
Long Short Term Memory (LSTM)
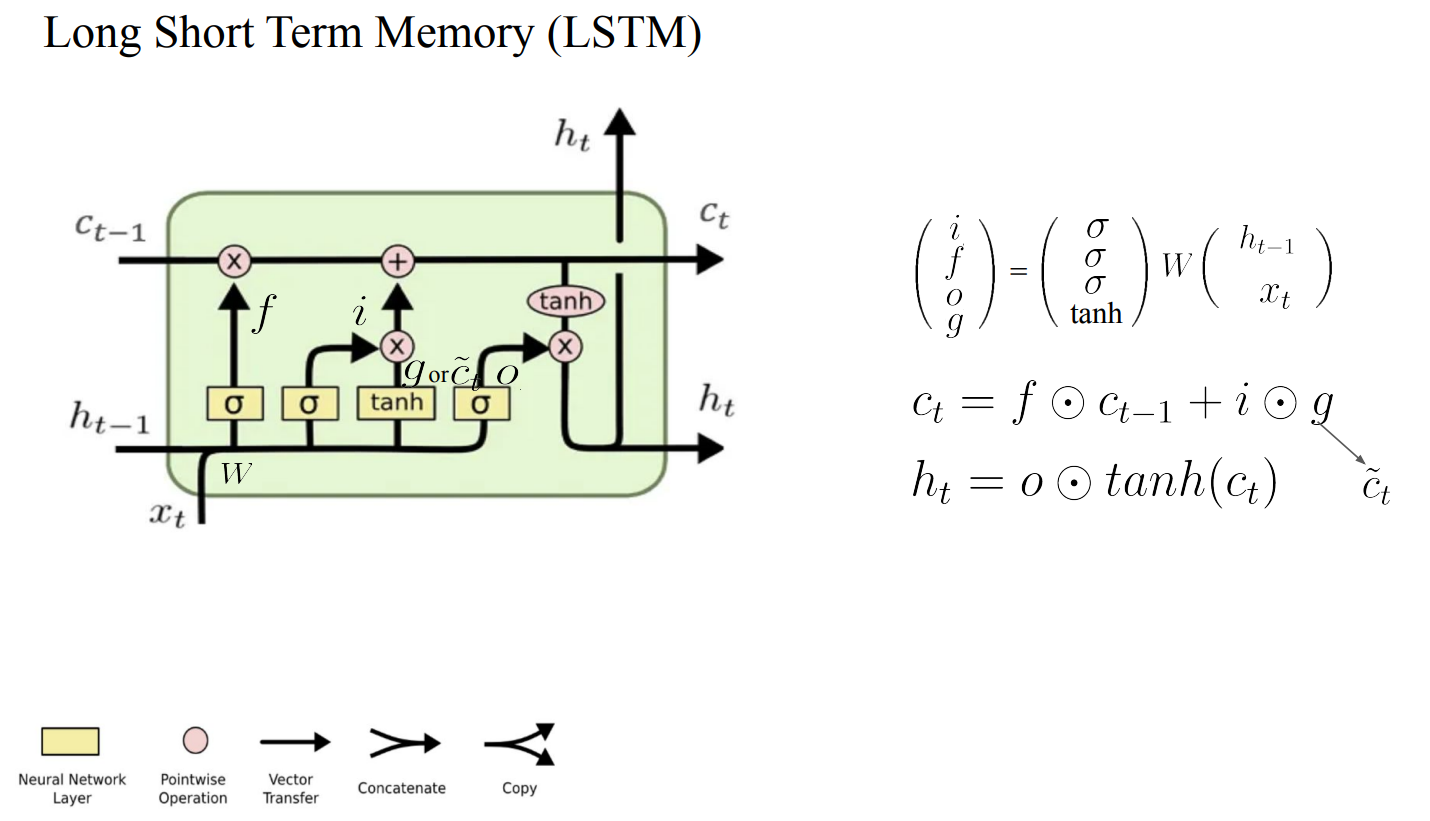
- 정보를 얼마나 저장할지 정해서 해결함
- 장기기억력이 좋다 : 필요한정보와 버릴정보를 적절히 조절함 → Cell

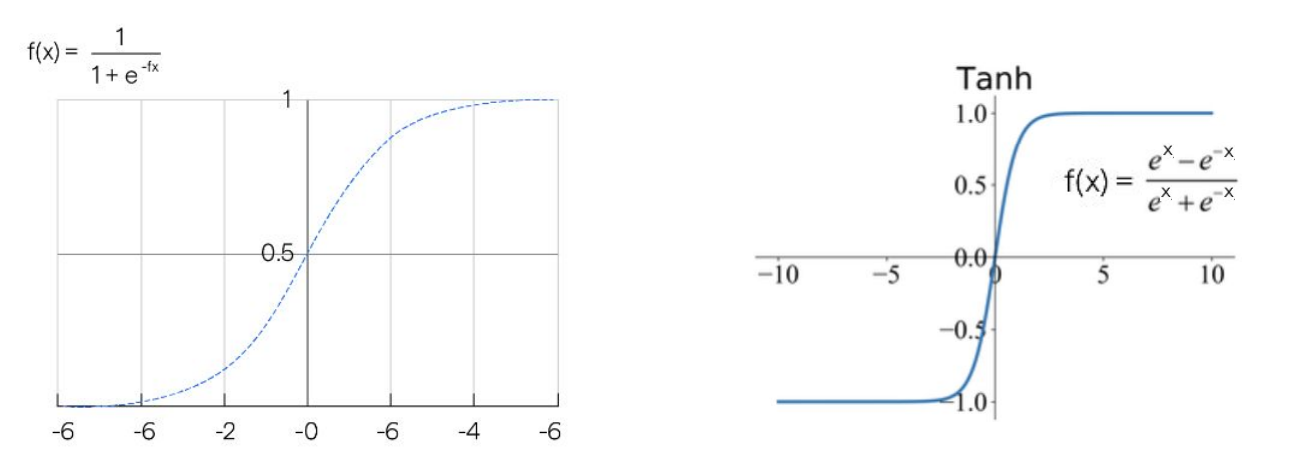
- Sigmoid를 사용하여 weighting 매커니즘을 구현
- Tanh는 Non-linearity를 표현하기 위한 activation function
- Input gate : 입력을 얼마나 받는지
- Forget gate : 이전 time step의 cell memory를 얼마나 잊는지
- Output gate : 현재 cell memory를 얼마나 출력하는지
- Cell state gate : 입력과 이전 은닉 상태를 얼마나 드러내는지
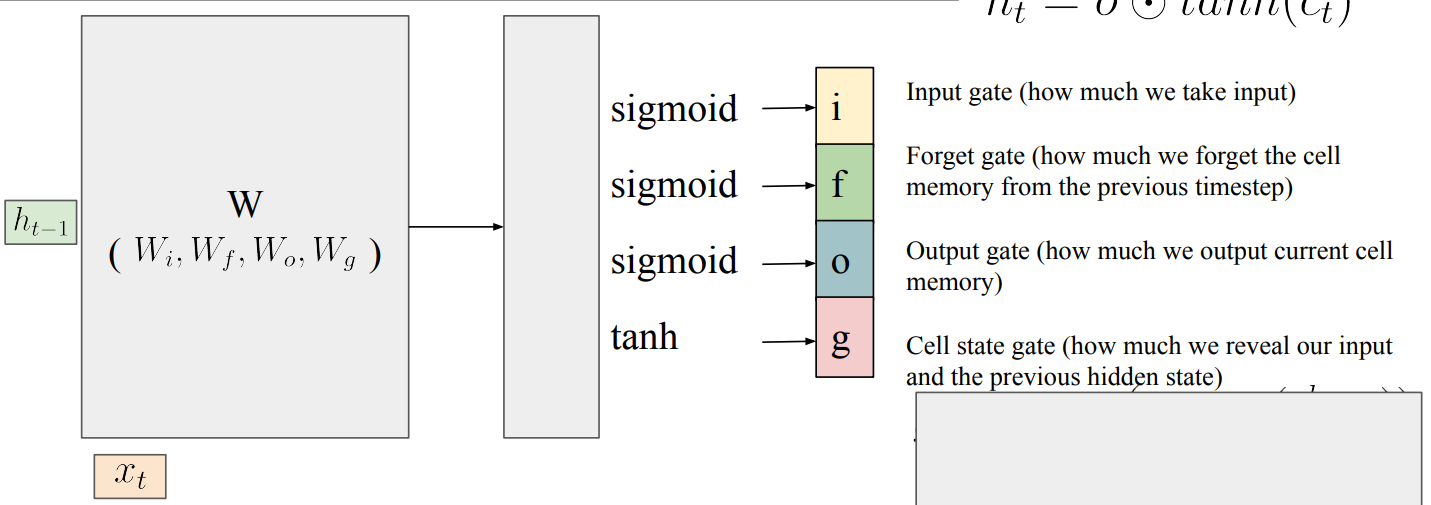
- Element wise multiplication이기 때문에 multiplication의 수가 매우 적어, Backpropagation이 굉장히 빠르고 계산이 안정적임
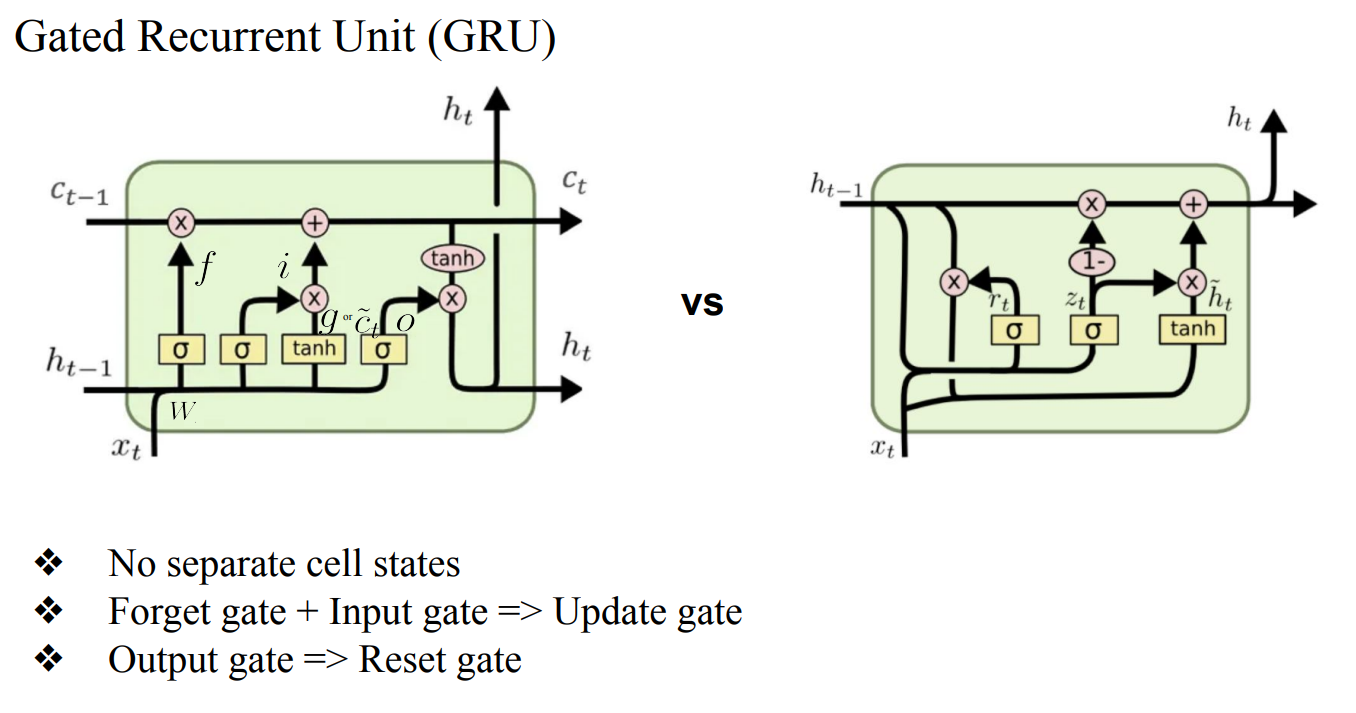
GRU
- LSTM을 gate가 너무 많아 복잡함 → 이를 단순화 한게 GRU
- hidden state 자체의 얼마만큼의 Information flowrk 있어야하는지 관리함
- GRU flow에 대한 수식정리
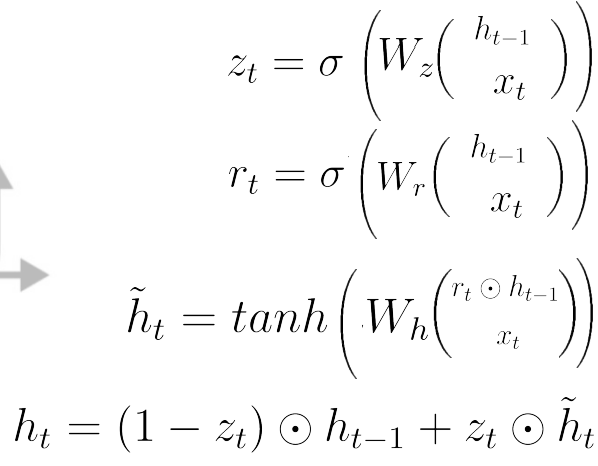

AI & Robotics