(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Recurrent Neural Network (RNN)
RNN Code - GitHub
- RNN의 issue : Gradient 소실문제 > LSTM
- RNN, LSTM, GRU > 어떤 모델을 썼느냐에 따른 차이
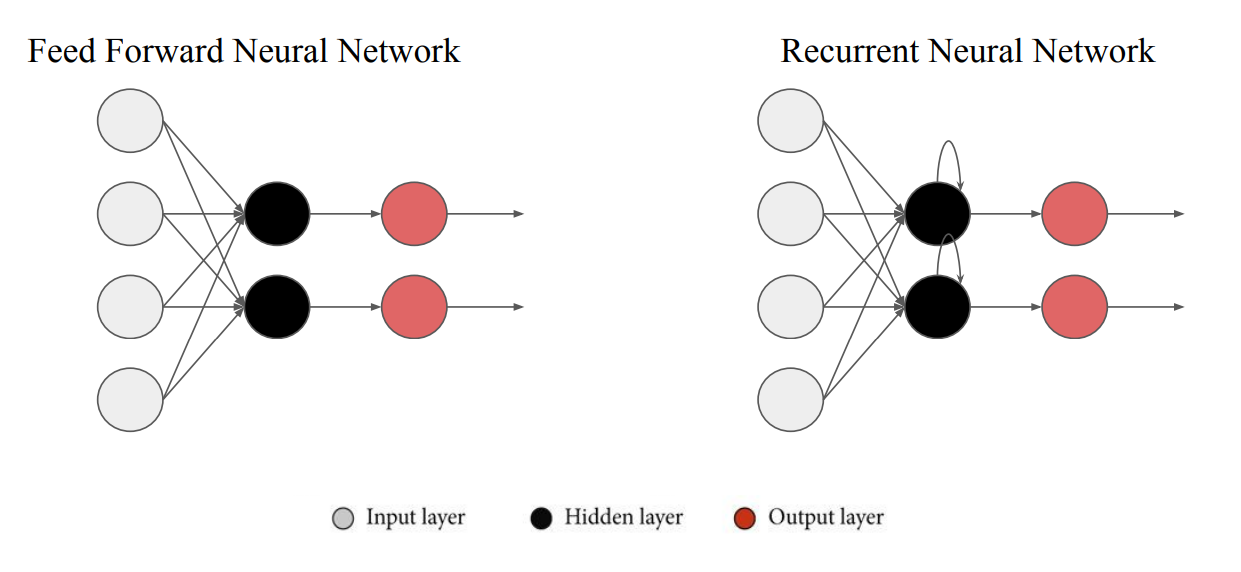
- FFNN : 일반적인 Deep Learning Model 구조
- RNN : 입력이 한방향으로 흐르는것이 아닌 자기자신을 스스로 update하는 과정이 생김
- Time-series data 대한 Processing이 가능
- 이전에 가지고 있던 time step에 대한 상황을 update할 수 있음 → 순차적으로 들어오는 data에 대한 개념을 적용할 수 있게됨
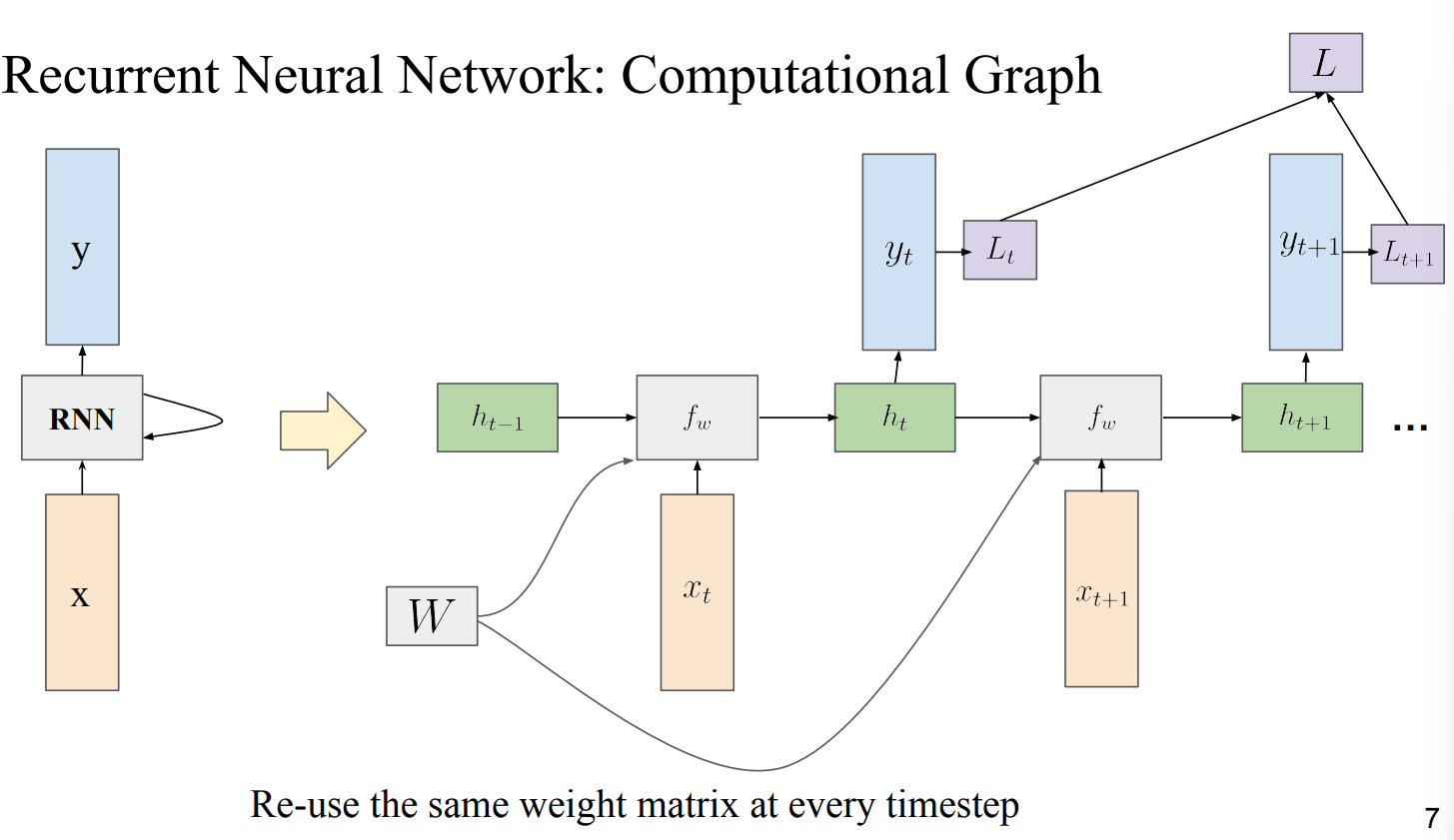
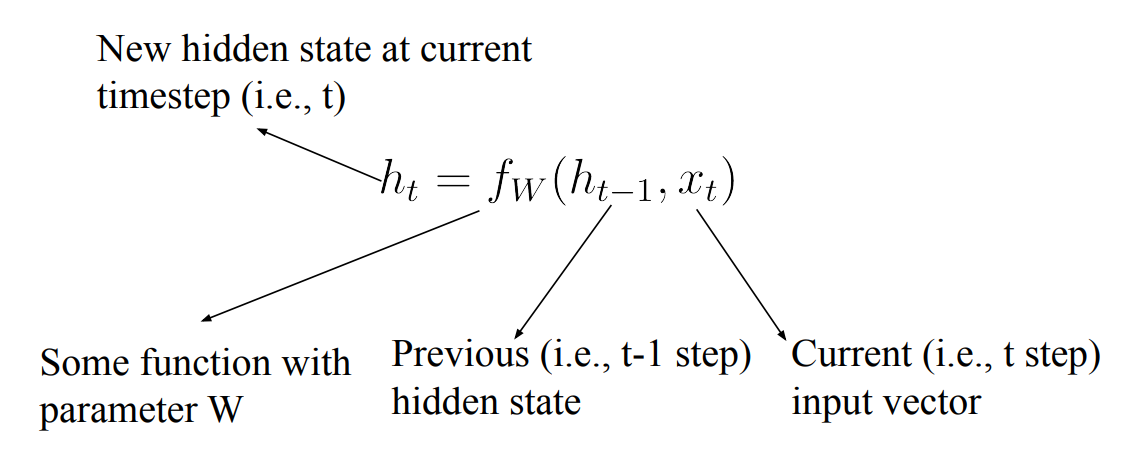
- 각 time step에 대해 Weight Matrix가 들어감
- 각 step에 대한 Gradient를 구하고 저장해 둠 → 다음 time step의 Weight Matrix를 계산할 때 사용함
- Many-to-Many : 각 time step별로 Loss를 구한 후 마지막에 Final Loss를 계산함
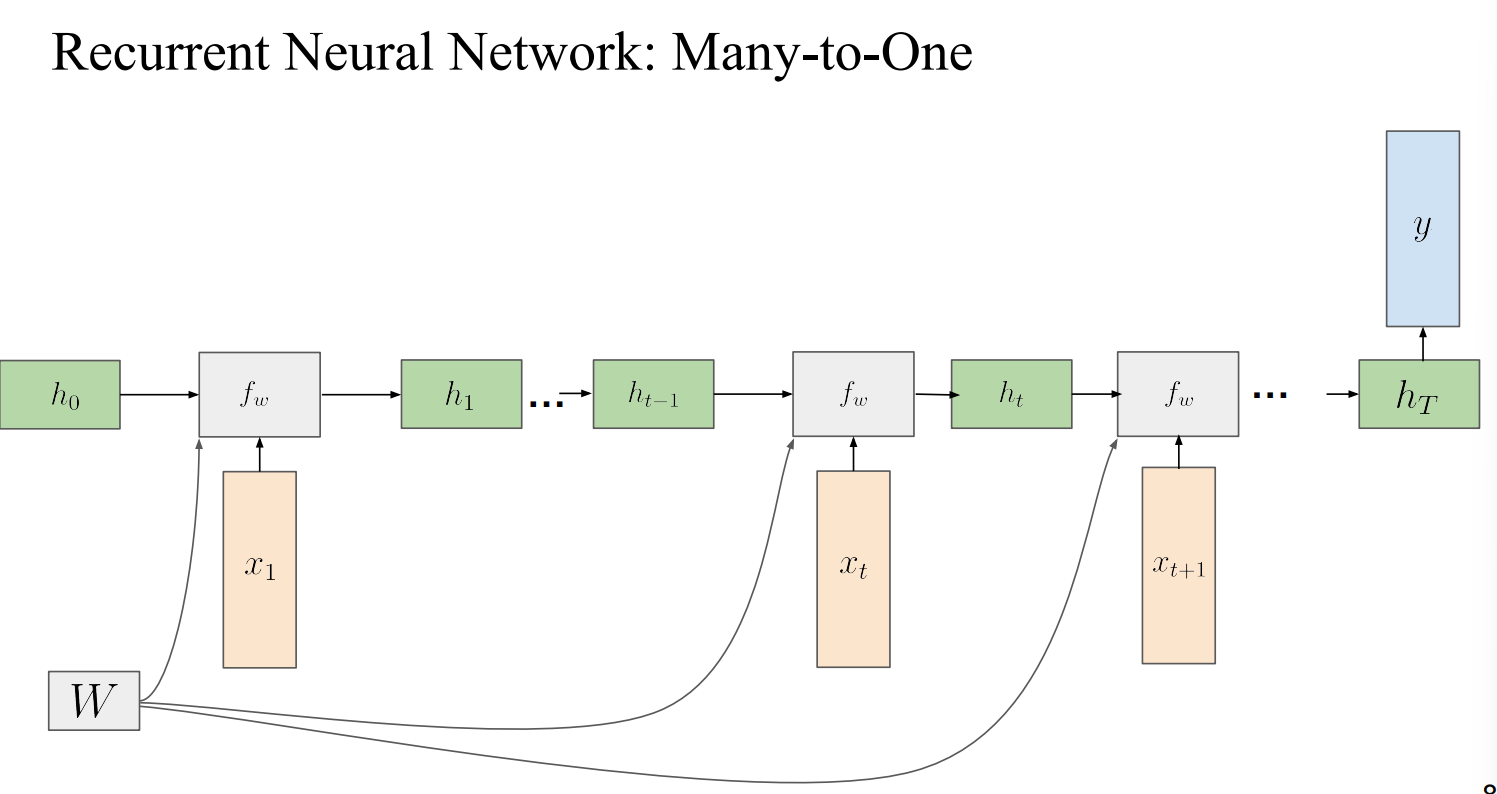
Many-to-One
- 각 state 별 output Prediction을 계산하는것이 아닌 끝까지 처리 후 마지막 time step에서만 Prediction을 진행함
One-to-Many :
- 하나의 input이 주어지고 각 time step별로 output이 나오게도 가능함
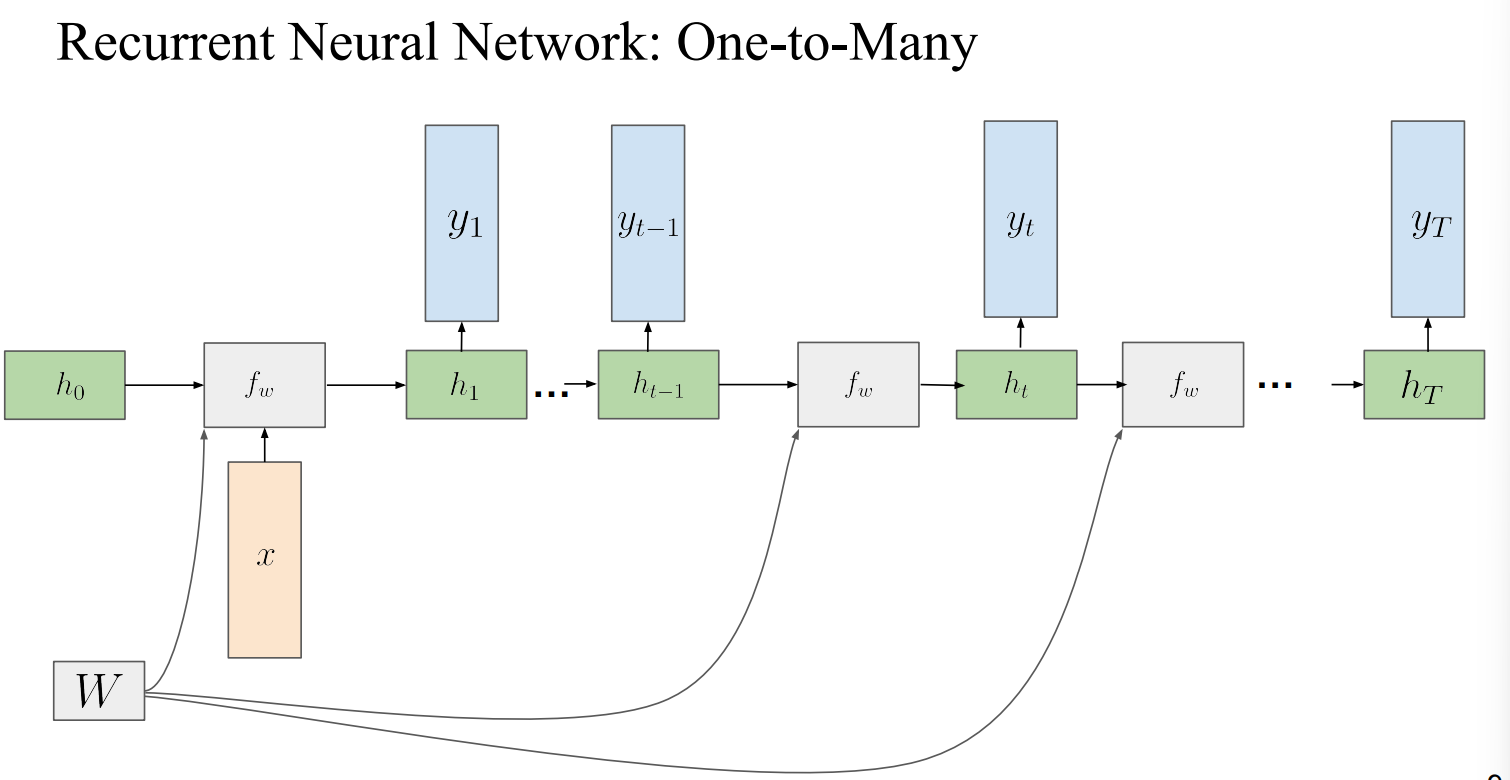
Many-to-Many
- Many-to-Many는 Many-to-One와 One-to-Many를 합쳐서 사용할 수 있음
- 이런 구조를 Sequence to Sequence라고함
- Many-to-One를 Encoder, One-to-Many를 Decoder로 부름
- transformer 이전 Text generation에서 가장 많이 쓰였던 구조
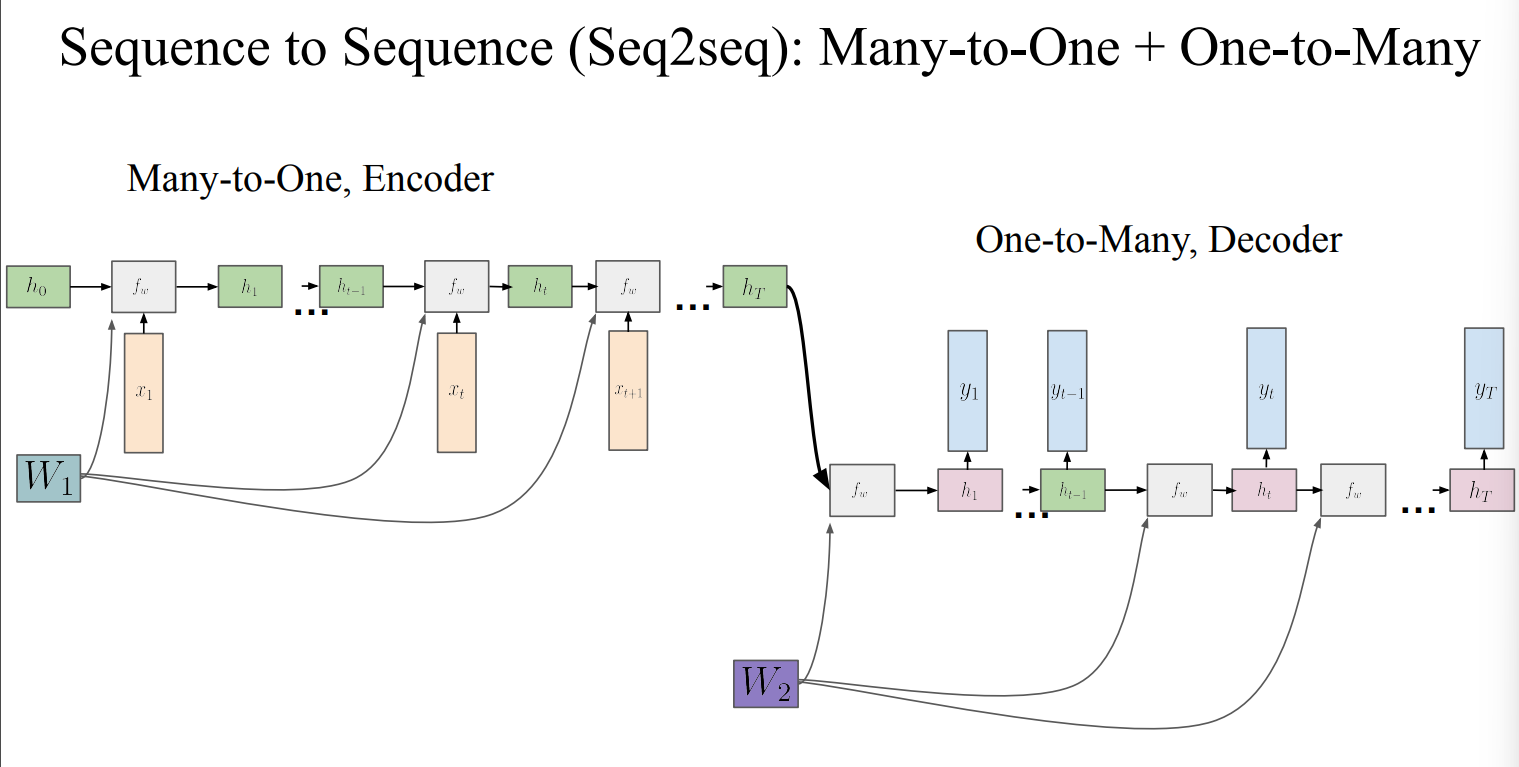
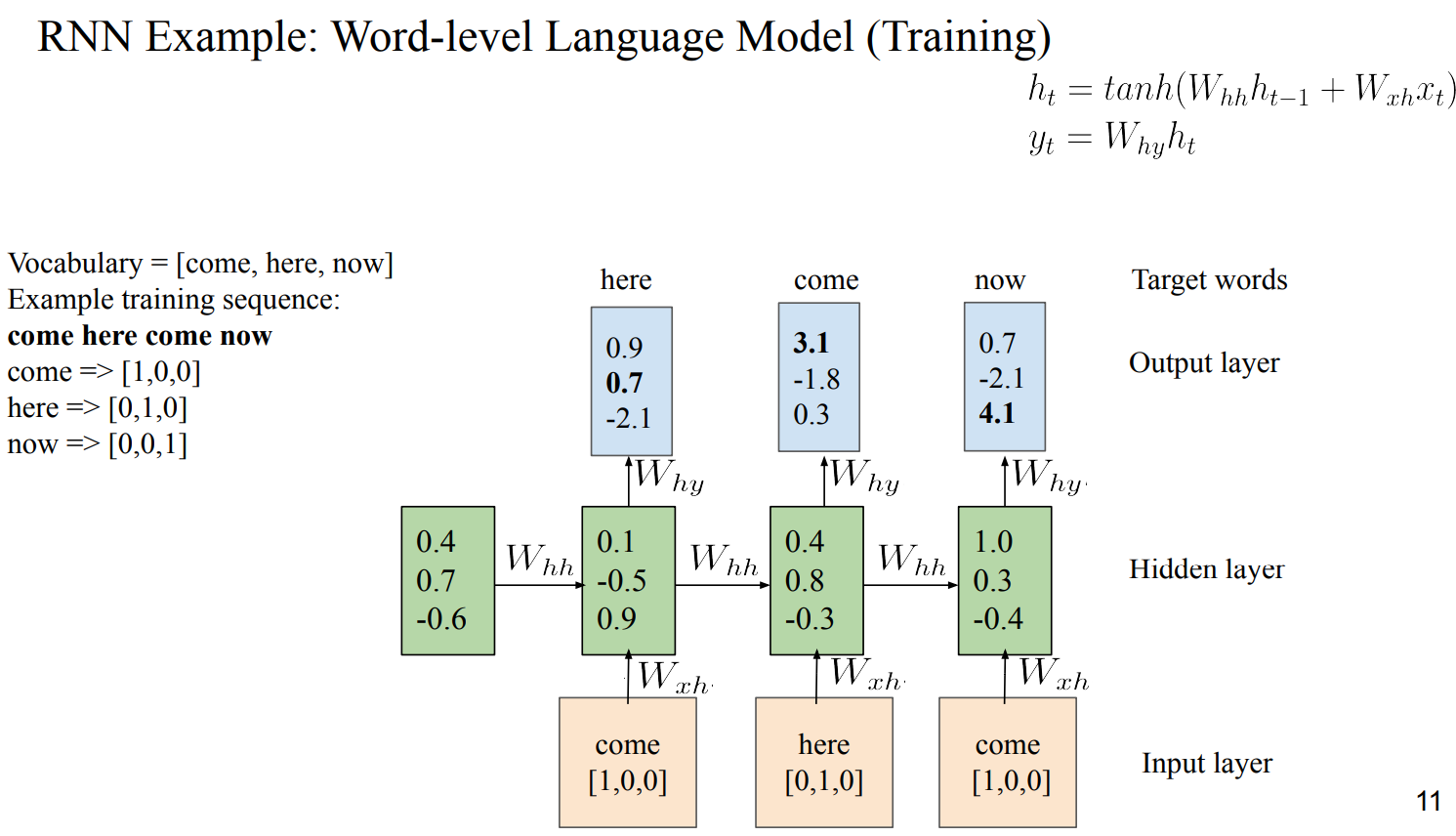
- output은 vocabulary size와 동일하게 Scoring해야함
- 각 W_hh, W_hy, W_xh는 동일함 → sharing됨
- Output Matrix에서 가장 큰 값(argmax)을 next word로 Prediction함
- 여기선 greedy하게 고르지만, 다양한 방법론이 존재
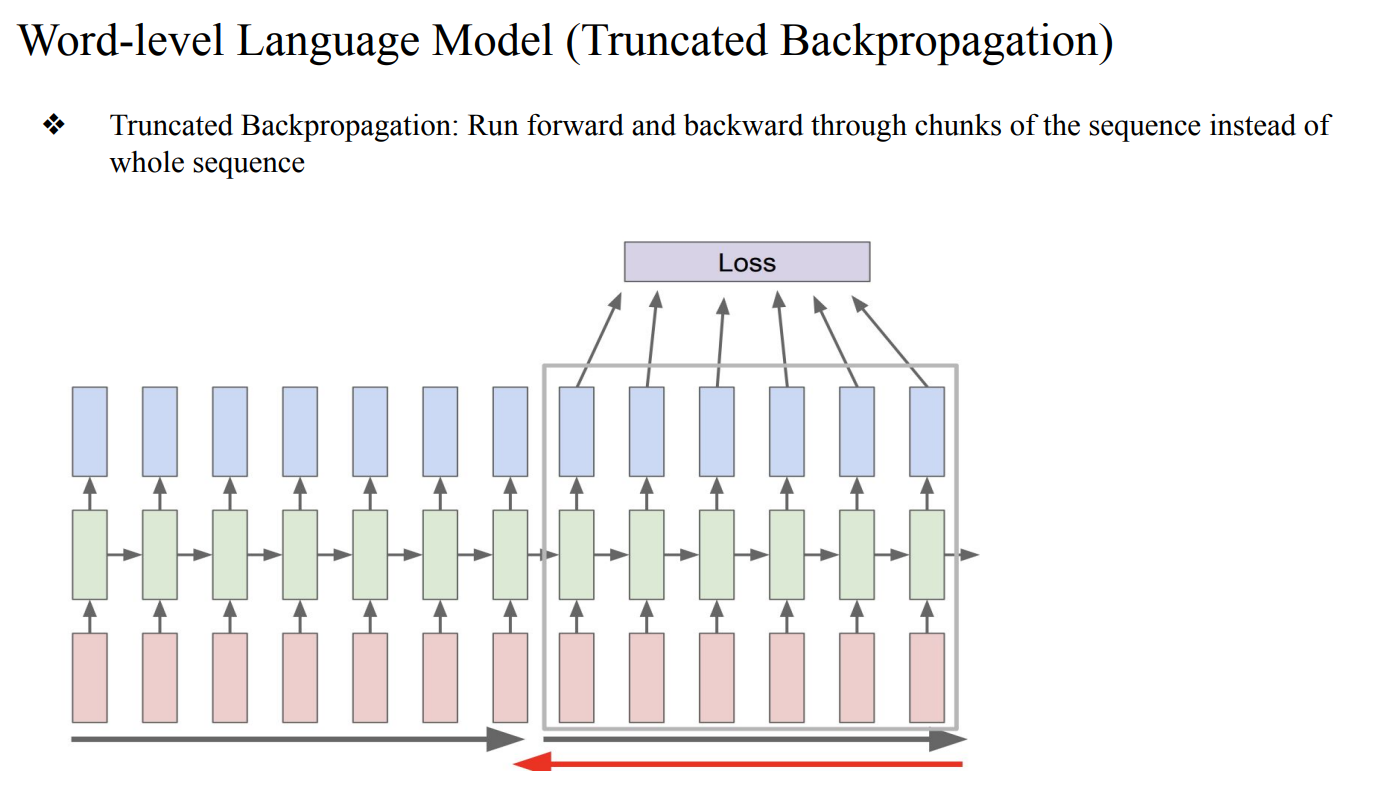
- 기존의 Backpropagation과정은 한 sample마다 진행함
- 전체 sequence를 전달하여 Loss를 계산한 후의 전체 sequence에 대한 Backpropagation를 진행하면 매우 느리고, 메모리를 많이 잡아먹게됨 → Truncated Backpropagation (즉, 잘라서 진행)
- 기존의 Backpropagation은 1번만 진행하지만, Truncated Backpropagation는 나눈 만큼 진행하게됨

AI & Robotics