
실행 계획이란 SQL문으로 요청한 데이터를 어떤 경로로 불어올 것인지에 대한 계획을 의미한다.
기본 실행 계획 수행
실행 계획을 확인하는 키워드로는 EXPLAIN , DESCRIBE , DESC 가 있다. 확인하고자 하는 쿼리 앞에 키워드를 작성하면 된다.
EXPLAIN
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 100001 AND 200000;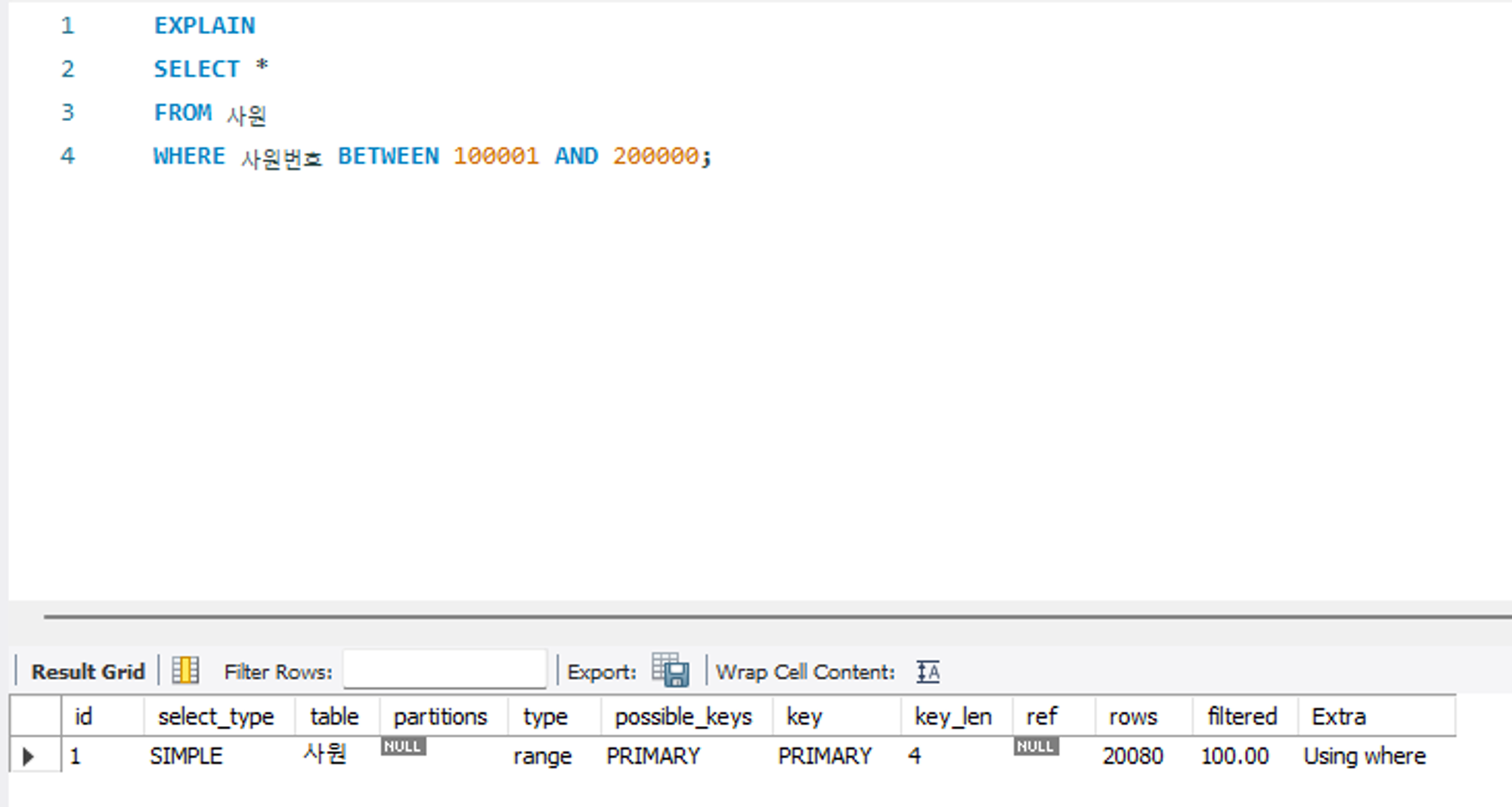
기본 실행 계획 항목 분석
실행 계획의 구성요소를 이해해보자.
id
실행 순서를 표시하는 숫자이다. SQL문이 수행되는 차례를 ID로 표기한 것으로, 조인 시 똑같은 ID가 표시된다.
select_type
SQL문을 구성하는 SELECT 문의 유형을 출력하는 항목이다. 해당 항목 정보를 알아보자.
SIMPLE
단순한 SELECT 구문만 작성된 경우를 가리킨다.
PRIMARY
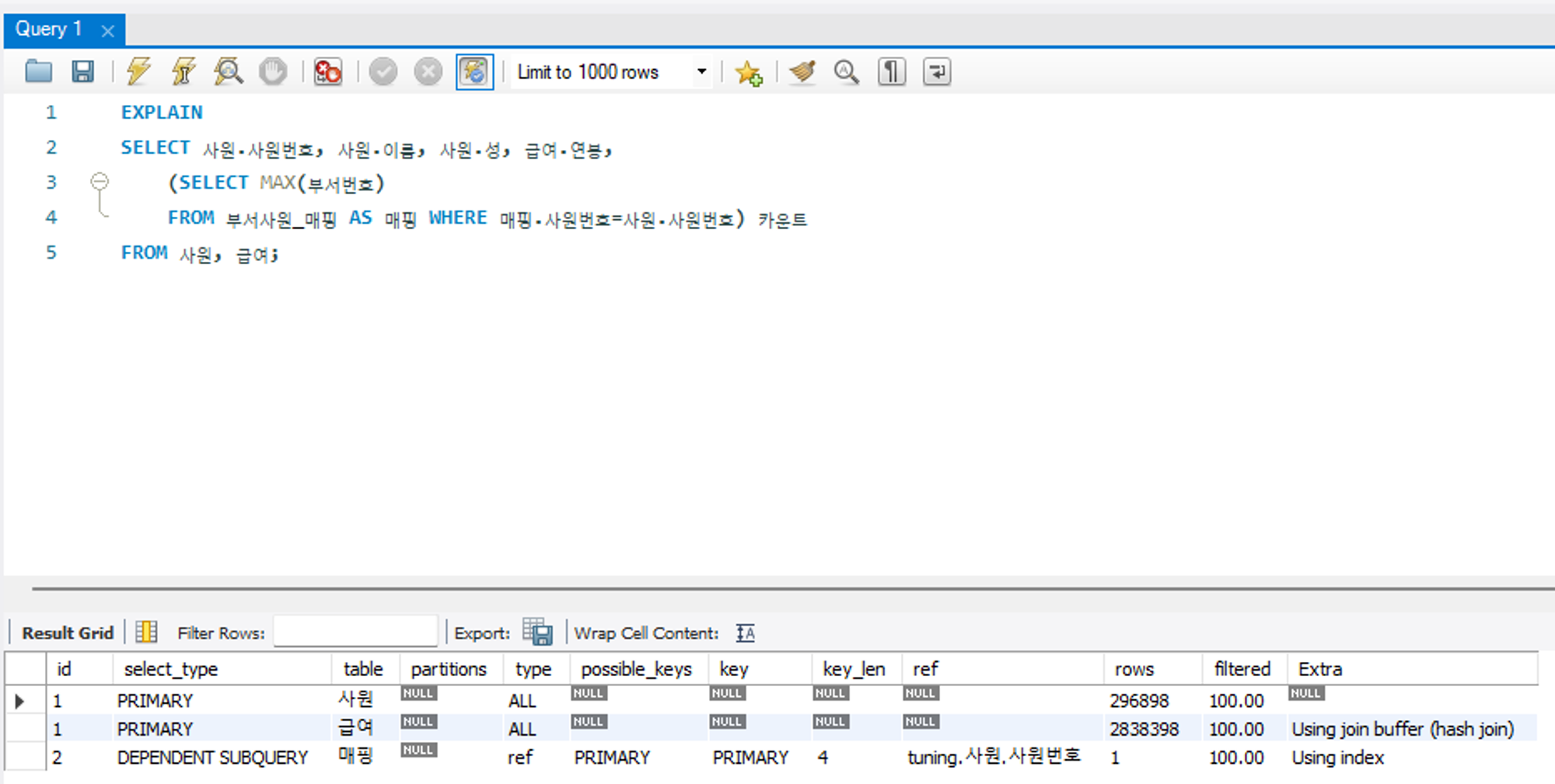
서브쿼리가 포함된 SQL문이 있을 때 첫 SELECT 문에 해당하는 구문에 표시되는 유형이다. 즉, 서브쿼리를 감싸는 외부 쿼리이거나, UNION 이 포함된 SQL문에서 첫 SELECT 키워드가 작성된 구문에 표시된다.
또는 UNION ALL 구문으로 통합된 쿼리에서 처음 SELECT 구문이 작성된 쿼리가 먼저 접근한다는 으미로 PRIMARY 가 출력된다.
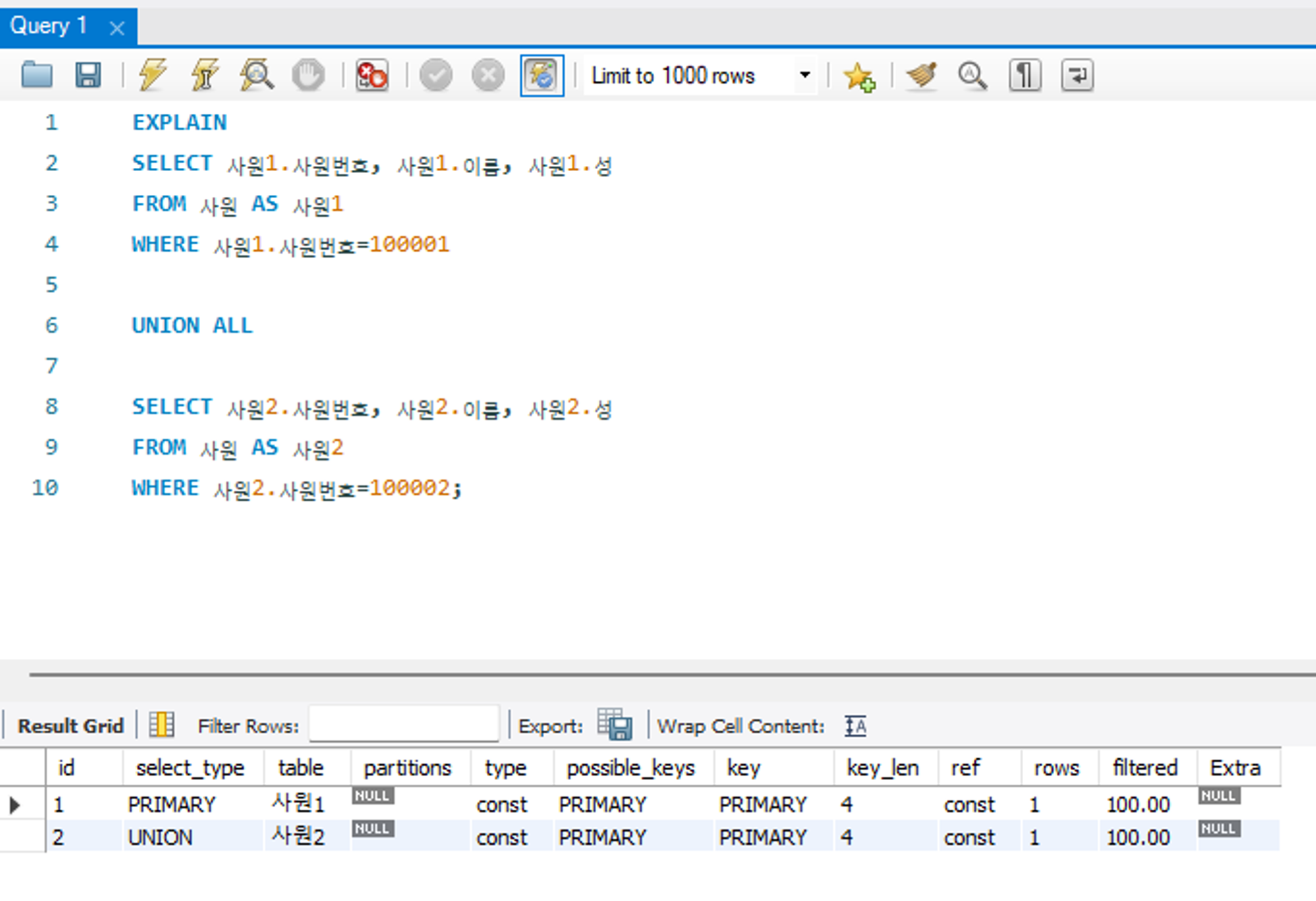
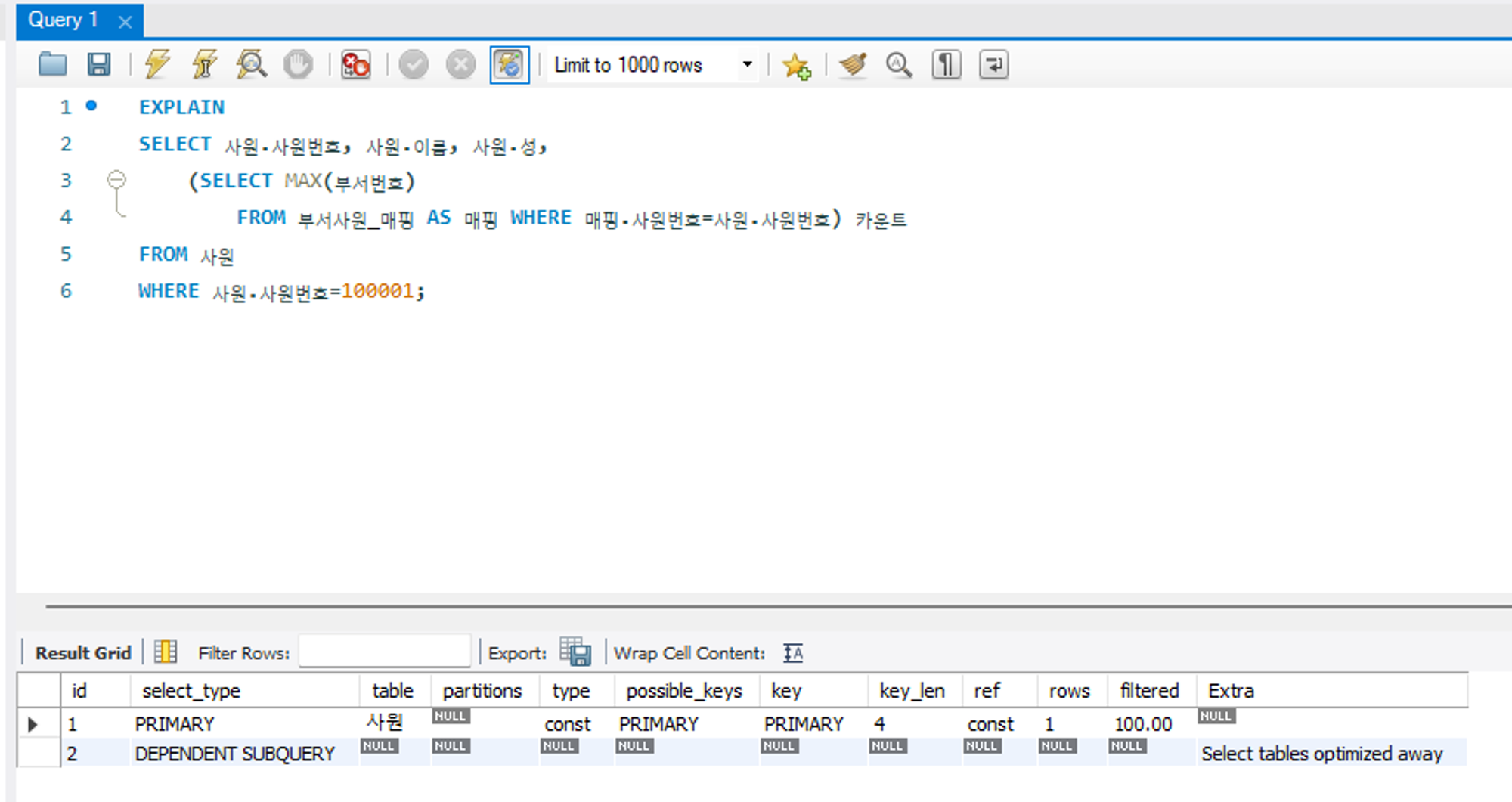
SUBQUERY
독립적으로 수행되는 서브쿼리를 의미한다.
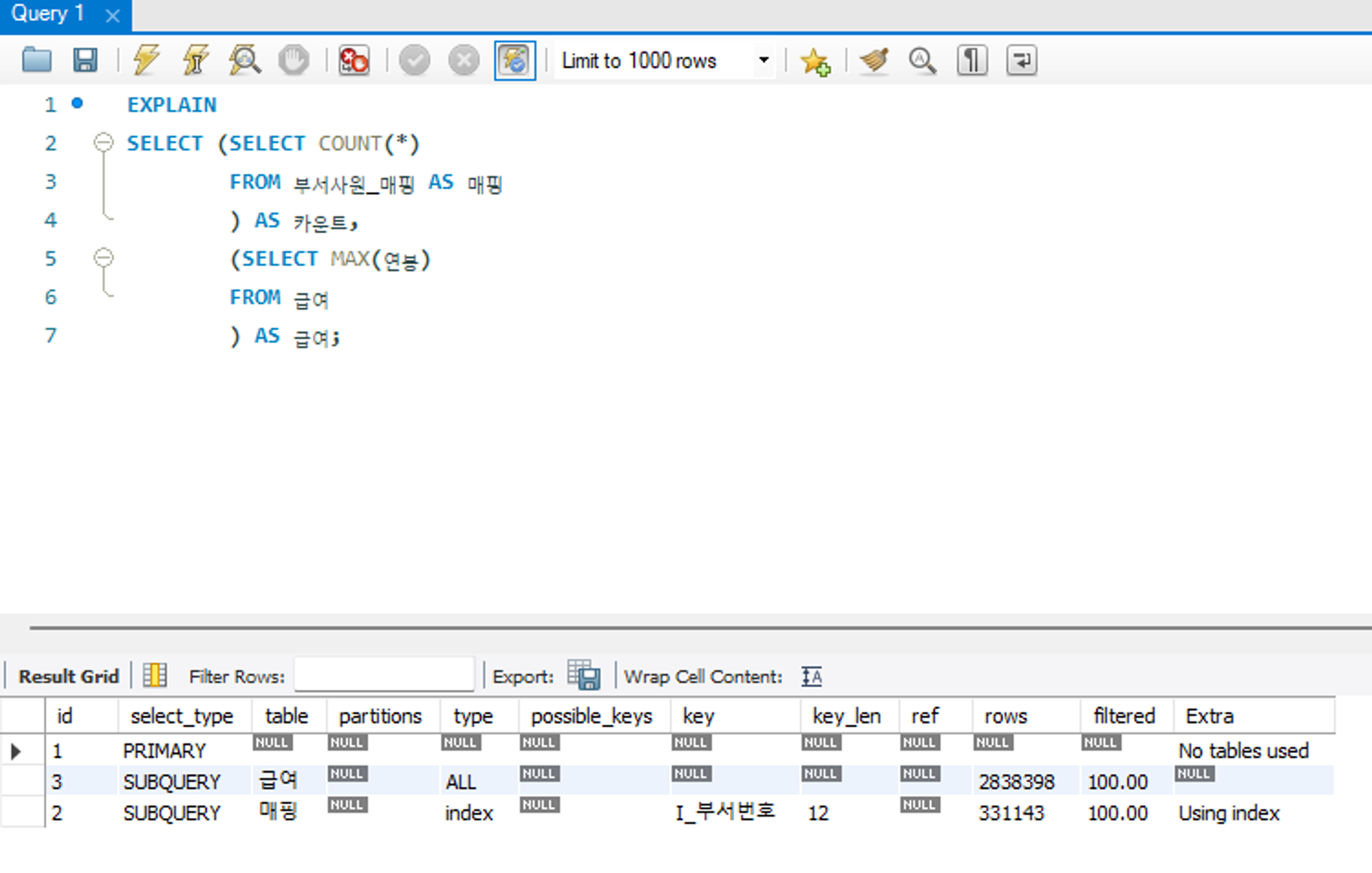
위 예제에서 부서사원_매핑, 급여 테이블에 대해 옵티마이저가 서브쿼리임을 인지하고 있음을 알 수 있다. SELECT 절의 스칼라 서브쿼리, WHERE 절의 중첩 서브 쿼리일 경우에 해당한다.
DERIVED
FROM 절에 작성된 서브쿼리라는 의미로, FROM 절의 별도 임시 테이블인 인라인 뷰를 말한다.
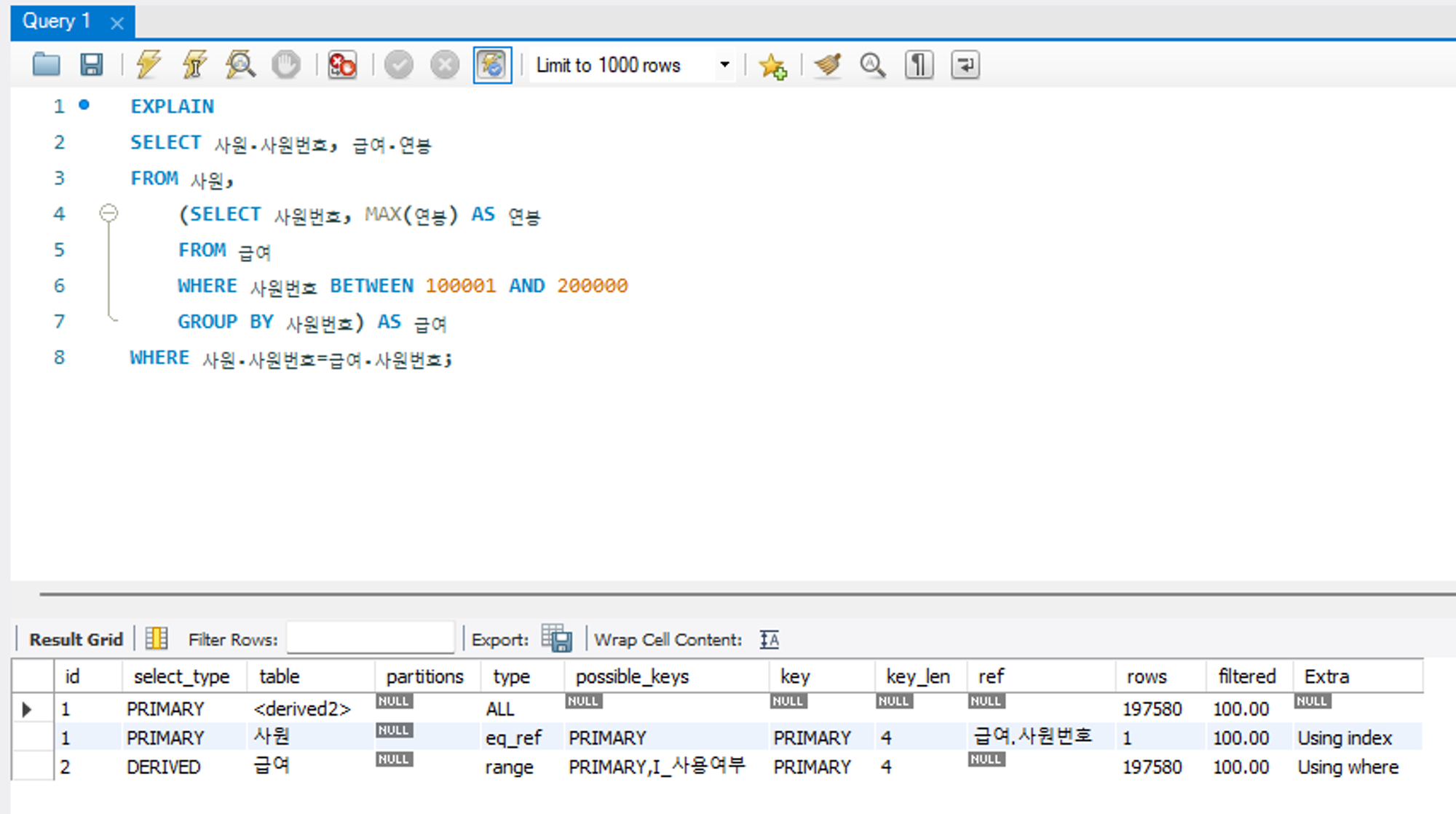
실행 계획에서 인라인 뷰가 두 번째(id 가 2인 행)로 수행되고 있다는 걸 알 수 있다.
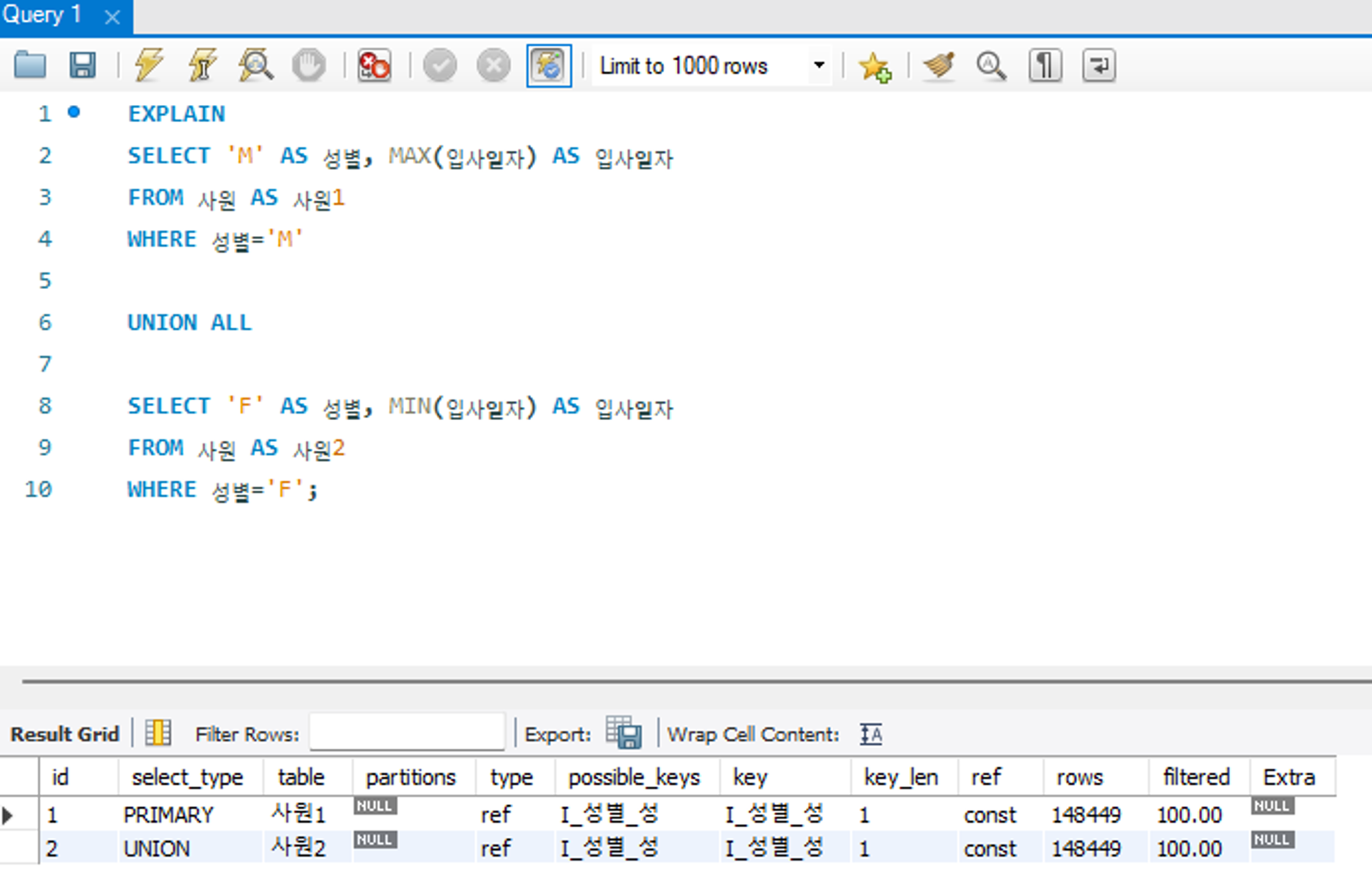
UNION
UNION , UNION ALL 구문으로 합쳐진 SELECT 문에서 첫 SELECT 구문을 제외한 이후의 SELECT 구문에 해당한다는 걸 나타낸다. 이때 UNION 구문의 첫 SELECT 절은 PRIMARY 로 출력된다.
UNION RESULT
UNION 구문으로 SELECT 절을 결합했을 때 출력된다. UNION 은 데이터를 가져와 정렬하여 중복 체크하는 과정을 거친다. 따라서 UNION RESULT 는 별도의 메모리 또는 디스크에 임시 테이블을 만들어 중복을 제거하겠다는 의미를 가진다. 이미 각 SELECT 문이 중복되지 않는 결과가 보장될 시 UNION ALL 을 사용하는 식으로 튜닝을 수행할 수 있다.
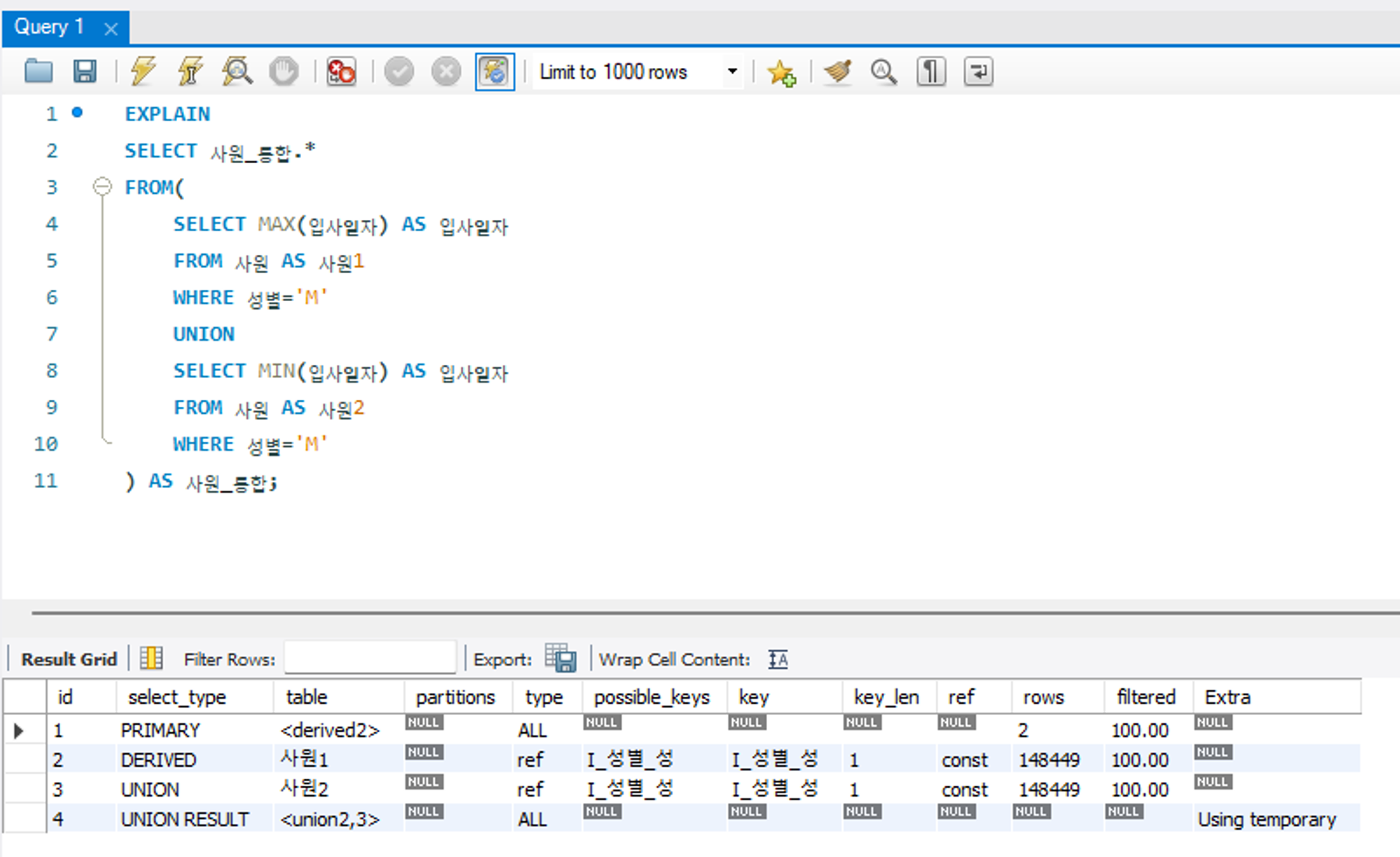
DEPENDENT SUBQUERY
UNION, UNION ALL 을 사용하는 서브쿼리가 메인 테이블의 영향을 받는 경우로, UNION 으로 연결된 단위 쿼리들 중에서 처음으로 작성한 단위 쿼리에 해당하는 경우다. 즉 첫 단위 쿼리가 독립적으로 수행되지 못하고 메인 테이블로부터 값을 하나씩 공급받는 구조이므로 성능적으로 불리하여 튜닝 대상이 된다.
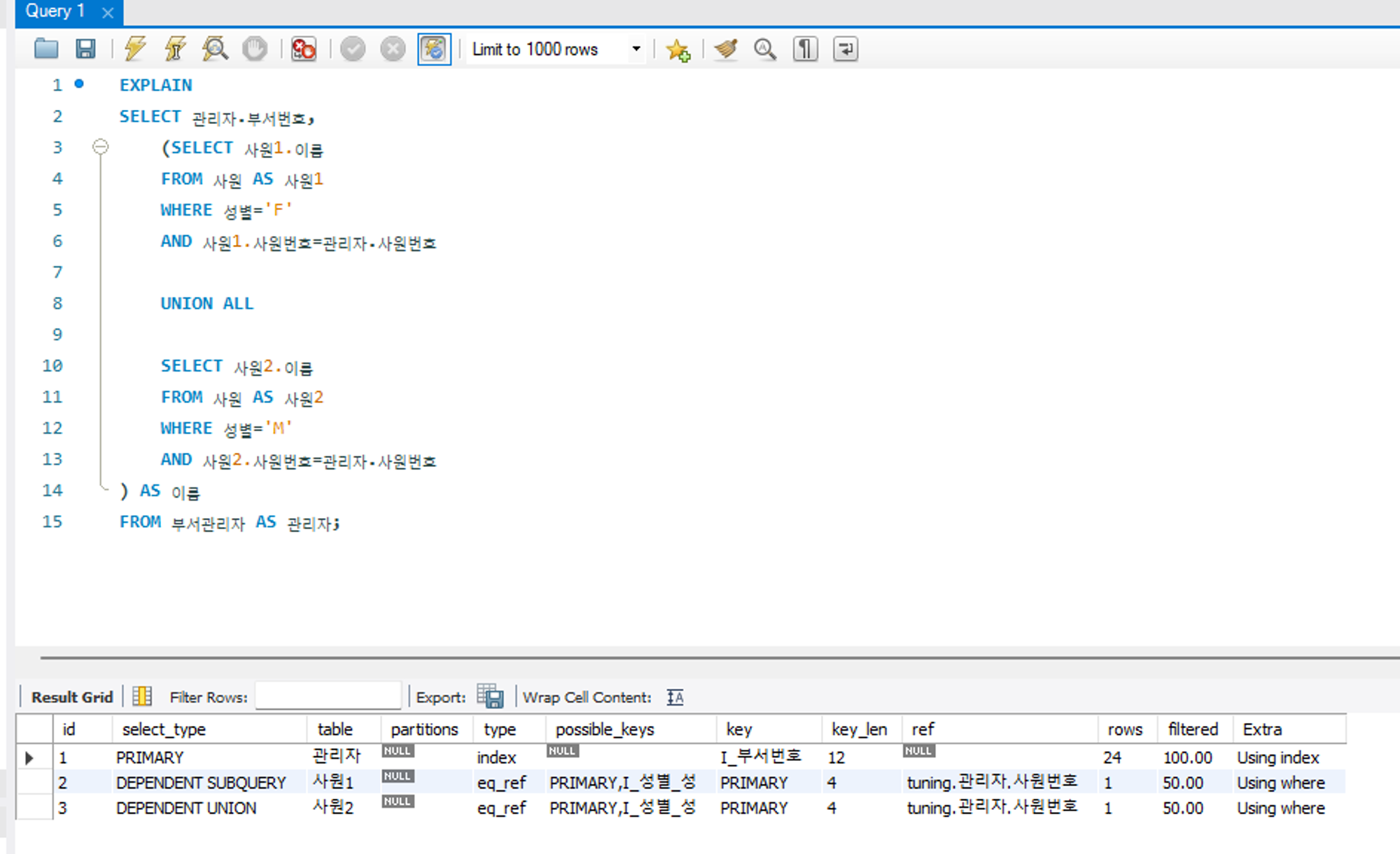
DEPENDENT UNION
UNION, UNION ALL 을 사용하는 서브쿼리가 메인 테이블의 영향을 받는 경우로, UNION 으로 연결된 단위 쿼리 중 첫 단위 쿼리를 제외한 두번째 단워 쿼리에 해당하는 경우이다. 이 역시 성능적으로 빌해 튜닝 대상이 된다. 앞선 경우와 동일한 예시이다.
UNCACHEABLE SUBQUERY
메모리에 상주하여 재활용되어야 할 서브쿼리가 재사용되지 못할 경우 출력되는 유형이다. 아래 경우가 해당된다.
- 해당 서브쿼리 내 사용자 정의 함수, 사용자 변수 포함
RAND(),UUID()함수 등을 사용하여 매번 조회 시 다른 결과 도출
자주 호출되는 쿼리라면 메모리에 서브쿼리 결과가 상주할 수 있게 변경하는 방향으로 튜닝을 검토해볼 수 있다.
MATERIALIZED
IN 절 구문에 연결된 서브쿼리가 임시 테이블을 생성한 뒤, 조인이나 가공 작업을 수행할 때 출력되는 유형이다. 즉, IN 절의 서브쿼리를 임시 테이블로 만들어서 조인 작업을 수행하는 것이다.
table
말 그대로 테이블명을 표시하는 항목이다. 실행 계획에서 테이블명, 별칭을 출력하며, 서브쿼리나 임시 테이블을 만들어서 별도의 작업을 수행할 때는 <subquery#> , <derived#> 라고 출력된다.
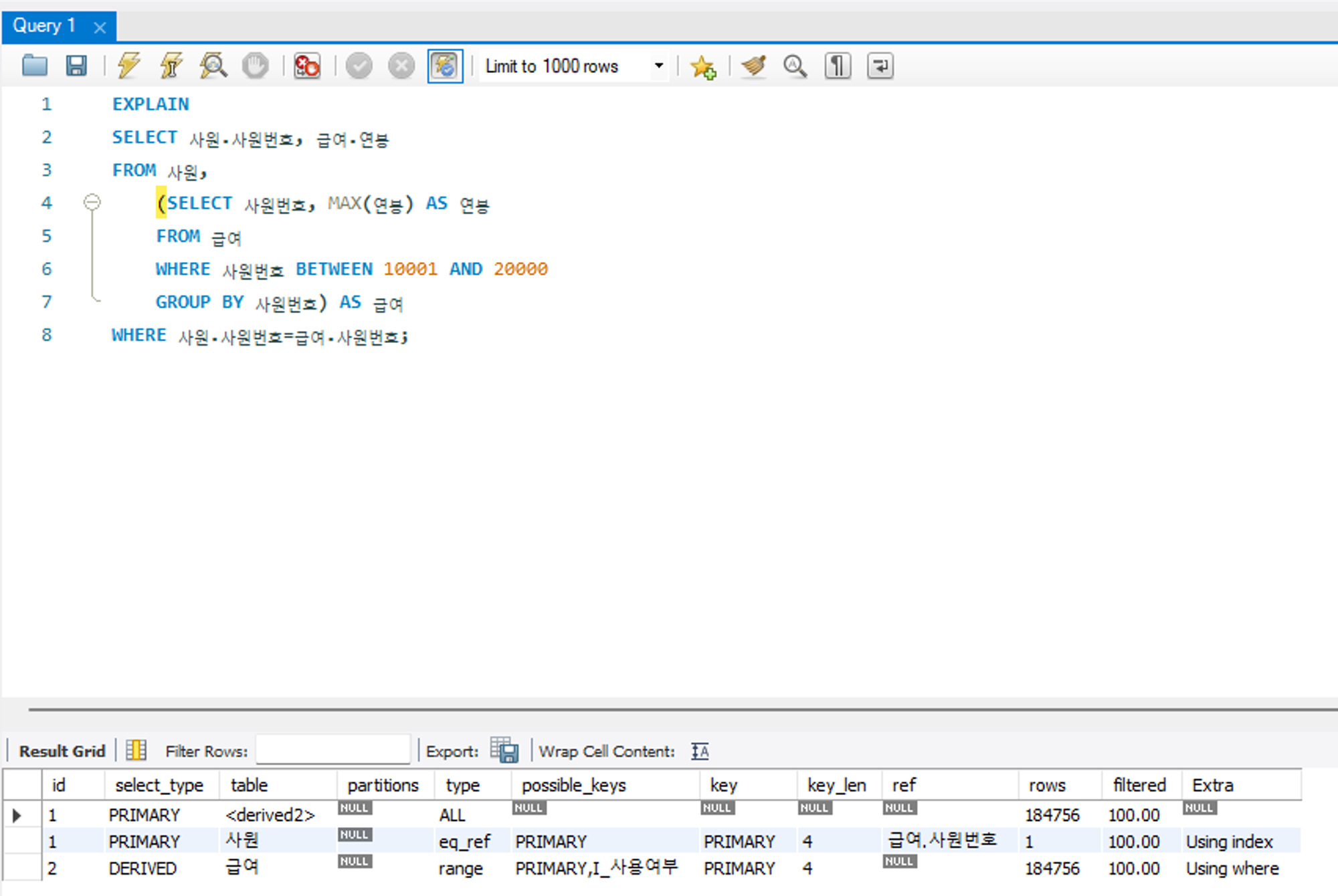
partitions
실행 게획 부가 정보로, 데이터가 저장된 논리적인 영역을 표시하는 항목이다. 사전에 정의된 전체 파티션 중 특정 파티션에 선택적으로 접근하는 것이 SQL 성능 측면에서 유리하다.
type
테이블의 데이터를 어떻게 찾을지에 관한 정보를 제공하는 항목이다.
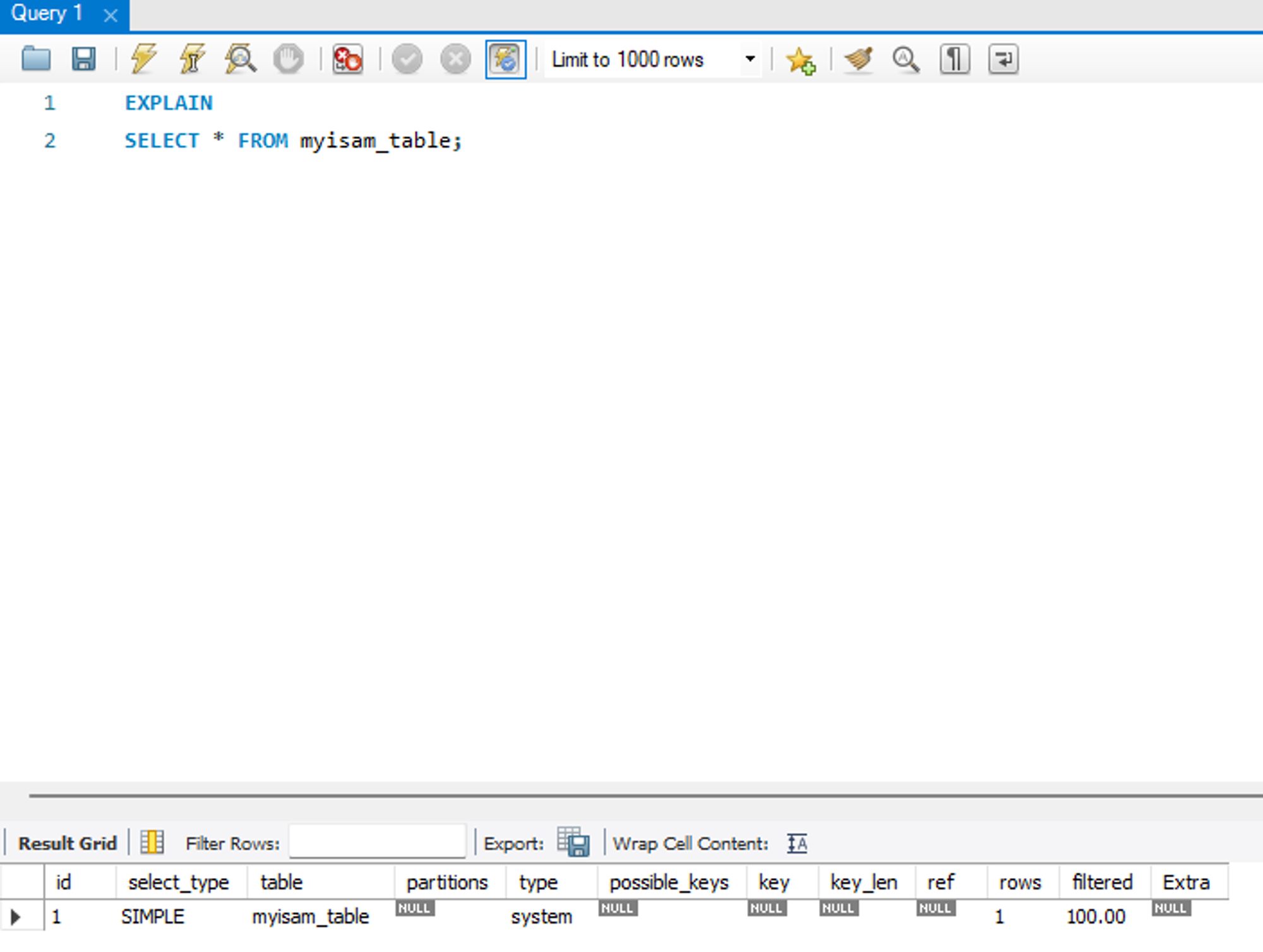
system
테이블에 데이터가 없거나 한 개만 있는 경우로, 성능상 최상의 type 이다.
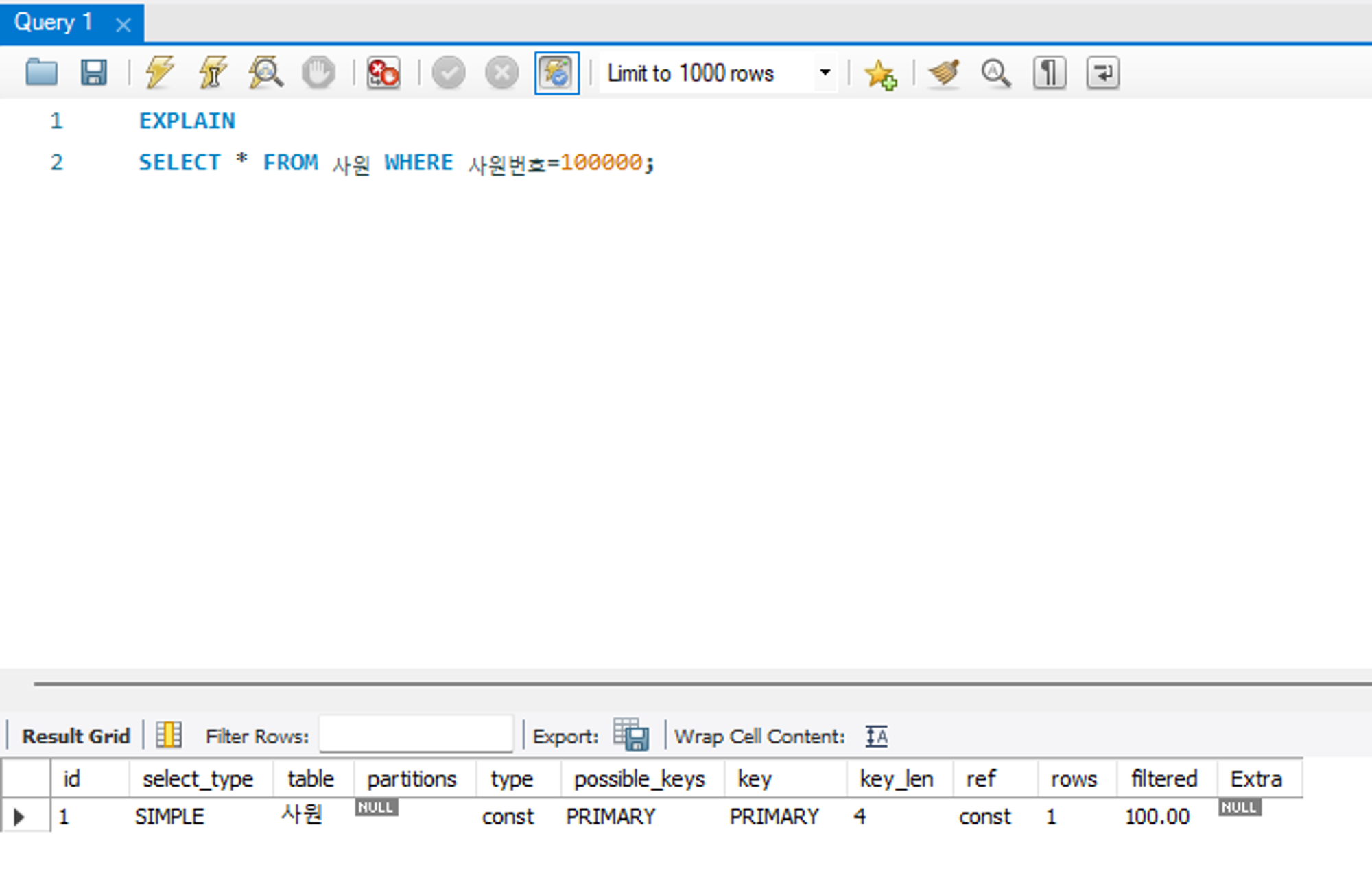
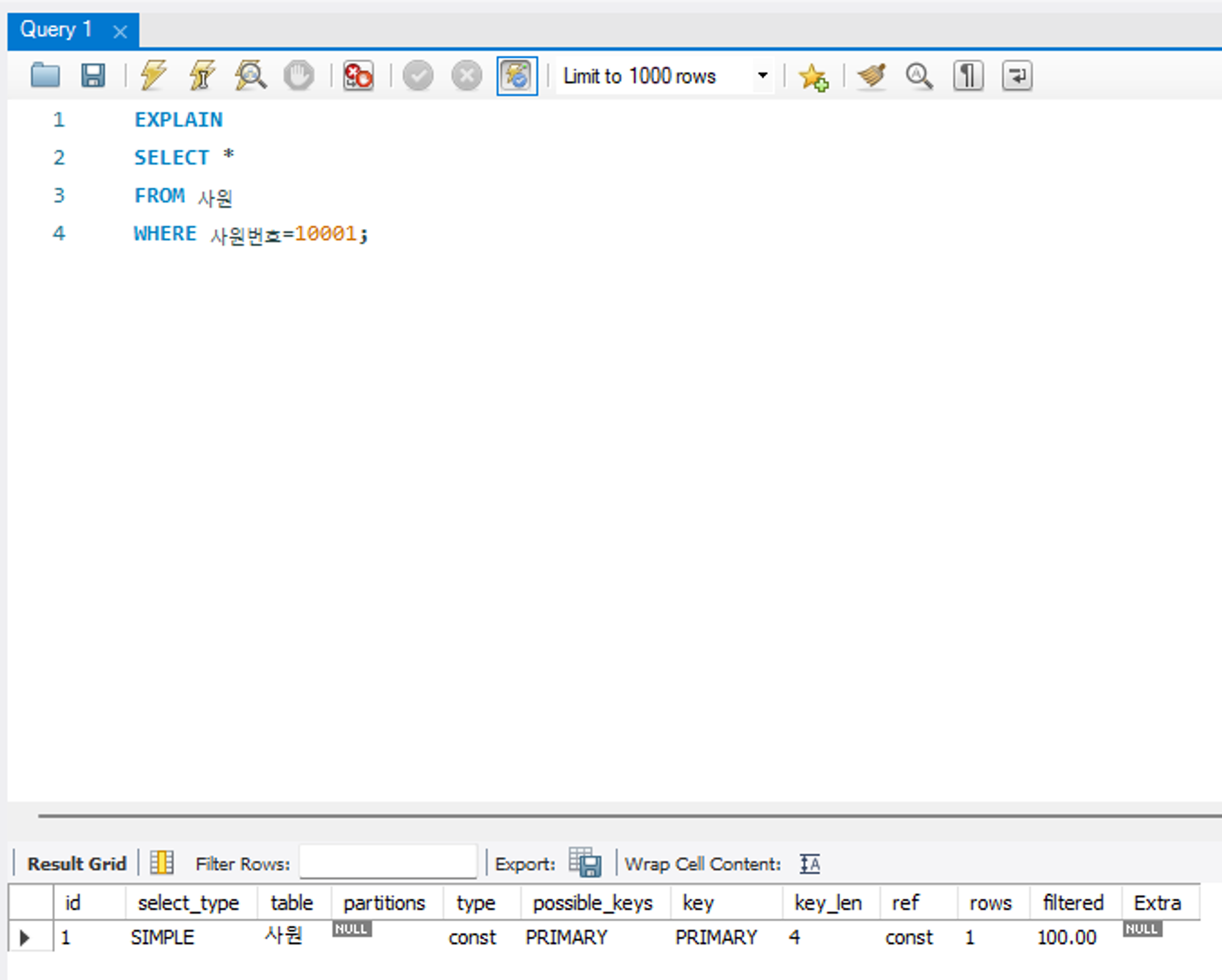
const
조회되는 데이터가 1건일 떄 출력되는 유형으로, 성능상 매우 유리한 방식이다. 성능 측면에서 지향해야 할 타입이다.
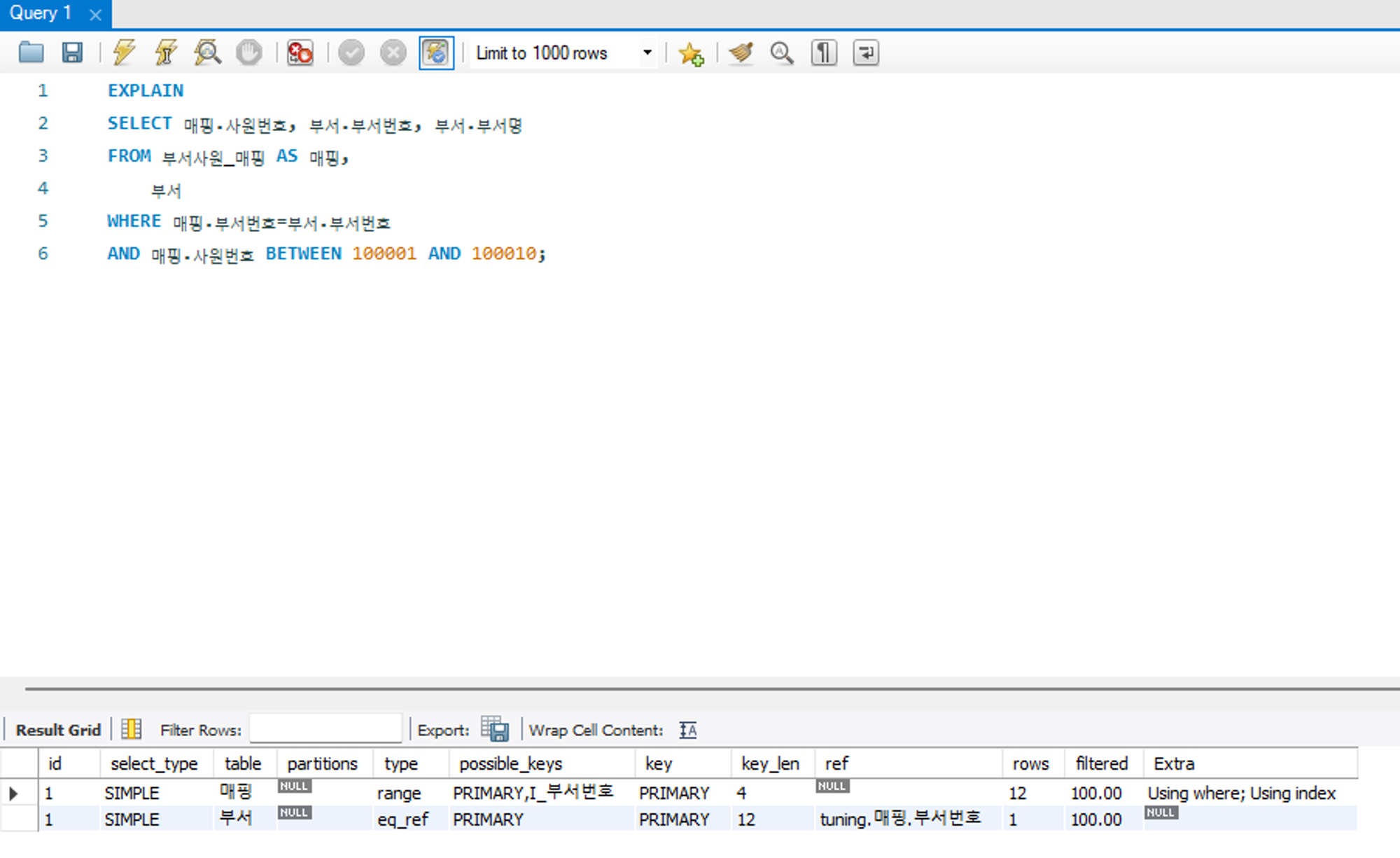
eq_ref
조인이 수행될 때 드리븐 테이블의 데이터에 접근하며 고유 인덱스 또는 기본 키로 단 1건의 데이터를 조회하는 방식이다. 드라이빙 테이블과의 조인 키가 드리븐 테이블에 유일하므로 조인이 수행될 때 가장 유리한 경우라고 할 수 있다.
ref
조인을 수행할 때 드리븐 테이블의 데이터 접근 범위가 2개 이상일 경우를 의미한다. 즉, 드라이빙 테이블과 드리븐 테이블의 조인이 일대다 관계로 수행되므로 성능 저하를 유발할 수 있다.
ref_or_null
ref 유형과 유사하지만 IS NULL 구문에 대해 인덱스를 활용하도록 최적화된 방식이다. MySQL은 NULL에 대해서도 인덱스를 활용하여 검색할 수 있으며, 이때 NULL 은 가장 앞쪽에 정렬된다. 테이블에 검색할 NULL 데이터량이 적다면 이 방식이 효율적이나, 그렇지 않다면 튜닝이 필요하다.
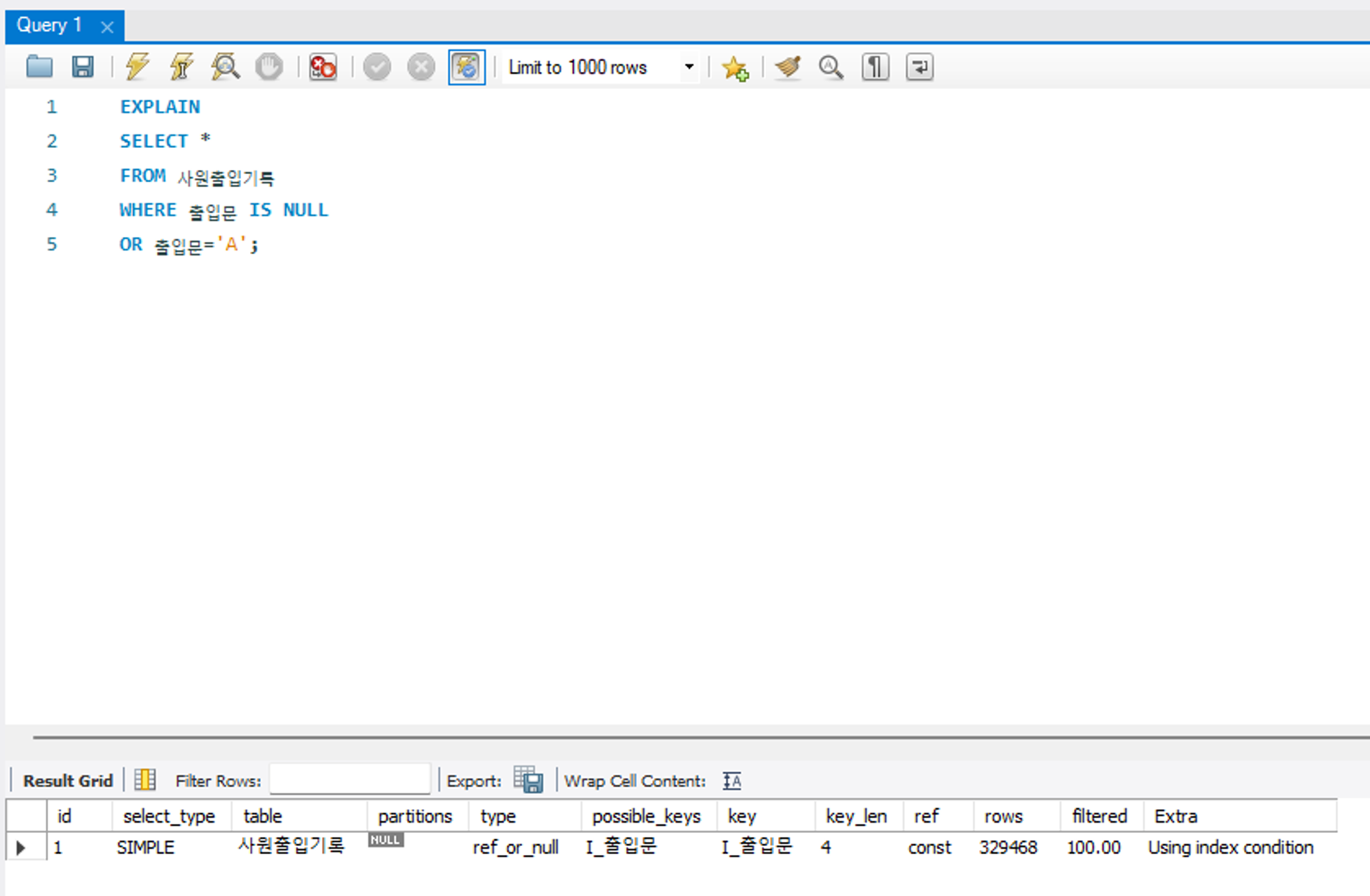
위 예제에서 I_출입문 이라는 인덱스가 존재하며, 출입문 IS NULL 조건문에 대해서도 인덱스를 활용해서 데이터를 검색하는 최적화된 방식이라고 해석할 수 있다.
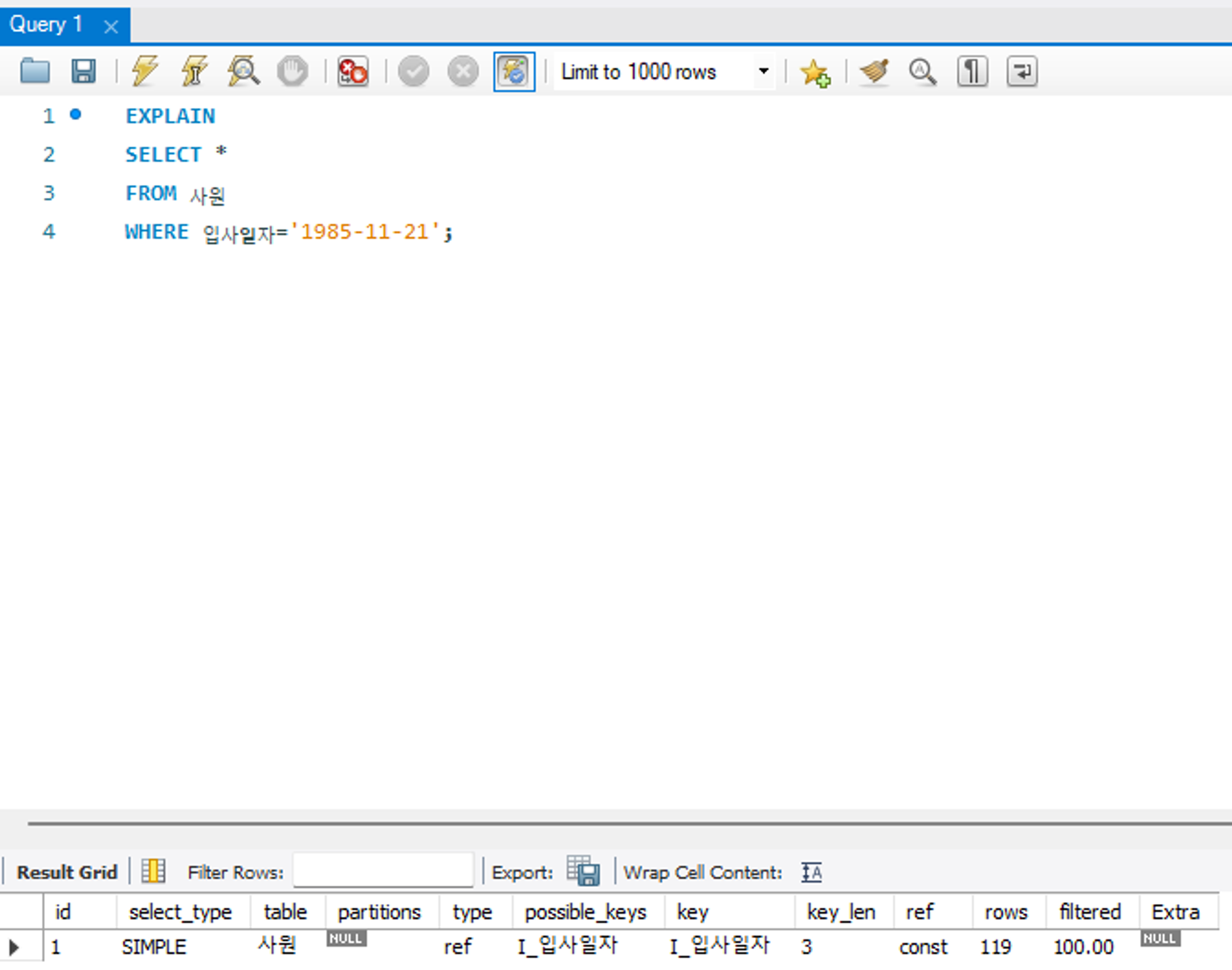
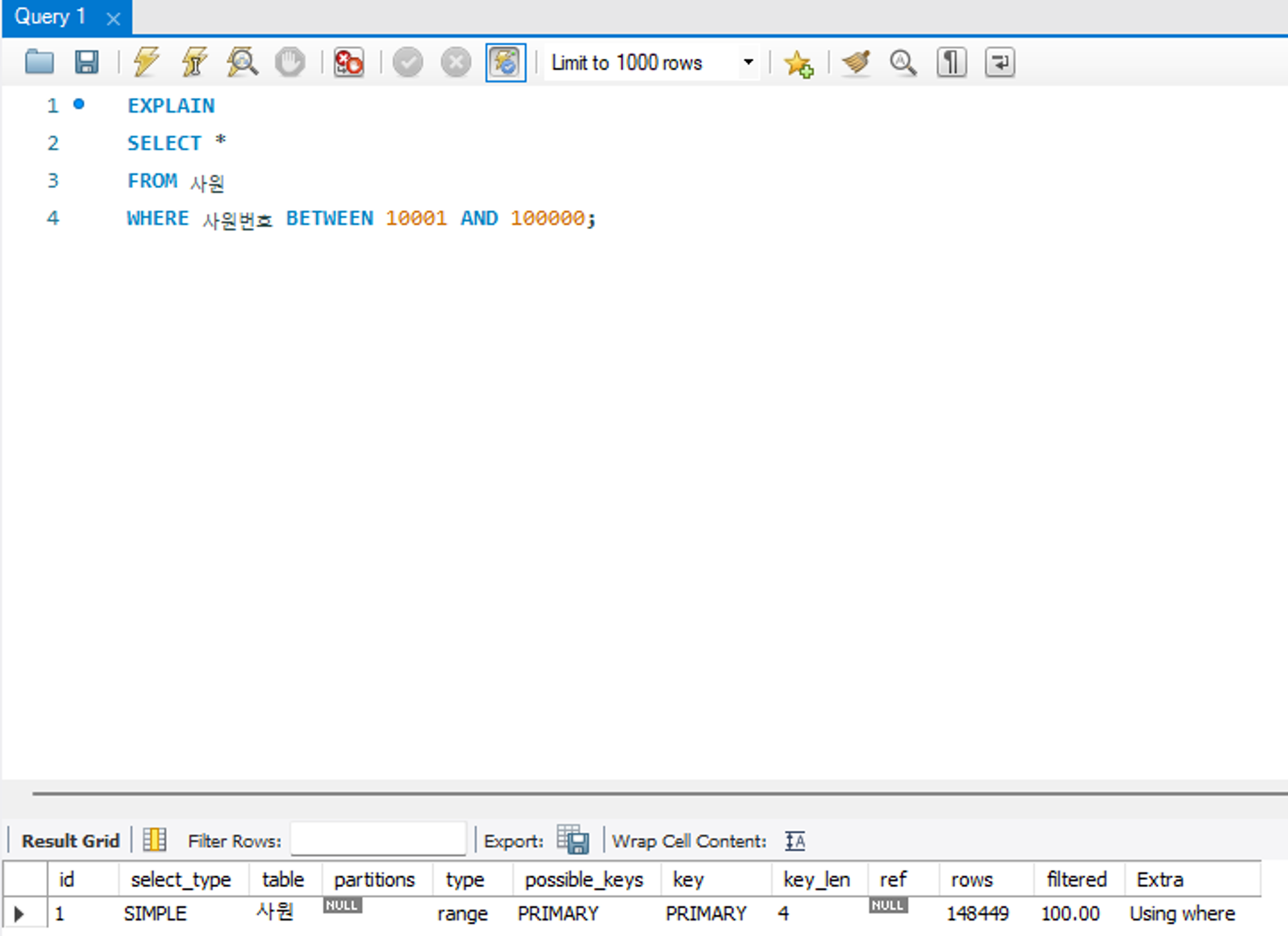
range
테이블 내의 연속된 데이터 범위를 조회하는 유형으로 비교 연산자, BETWEEN 등 연산을 통해 범위 스캔을 수행하는 방식이다. 스캔 범위가 넓으면 성능 저하의 요인이 될 수 있어 튜닝 대상이 될 수 있다.
fulltext
텍스트 검색을 빠르게 처리하기 위해 전문 인덱스를 사용하여 데이터에 접근하는 방식이다.
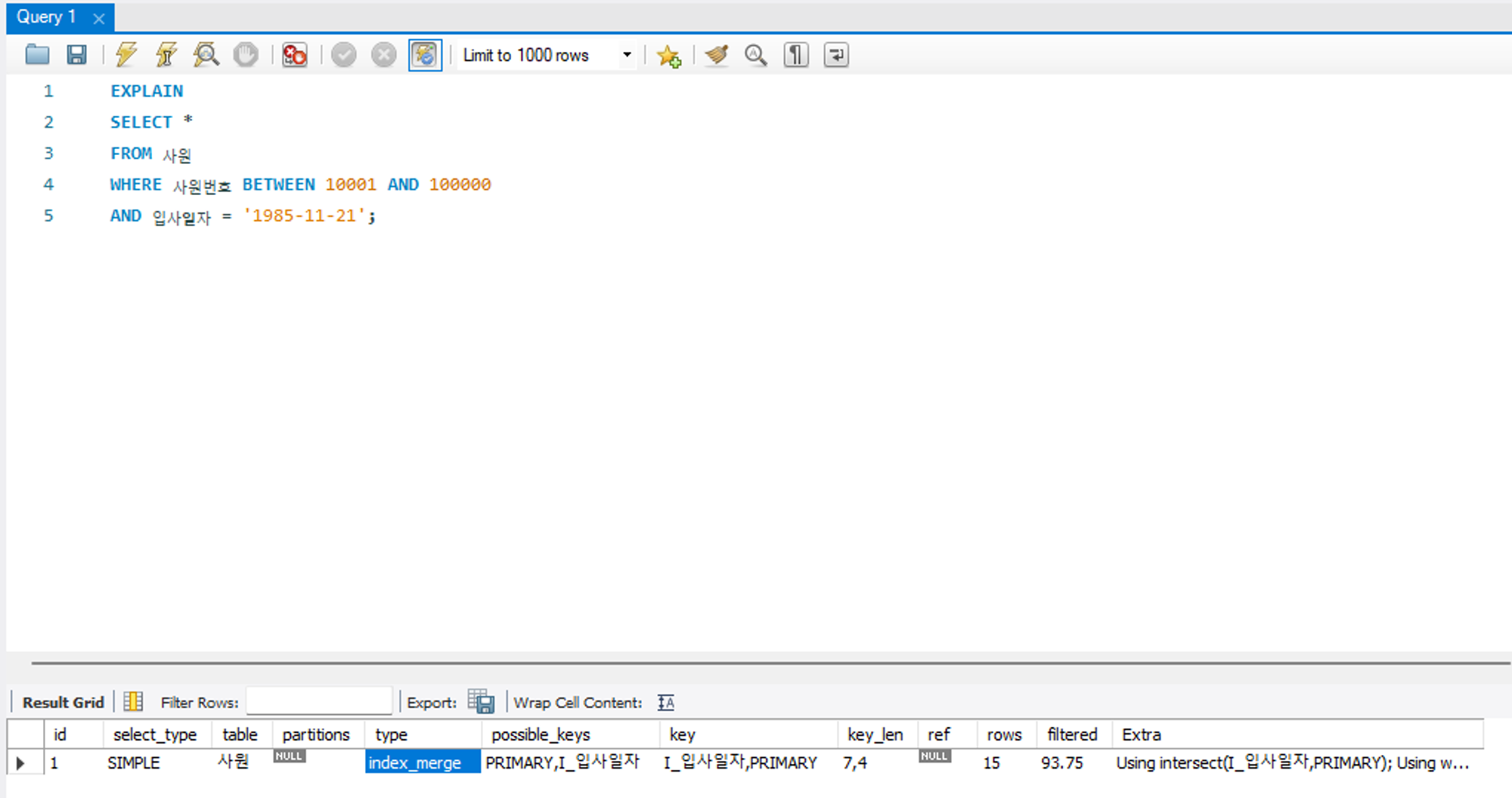
index_merge
결합된 인덱스들이 동시에 사용되는 유형이다. 즉, 특정 테이블에 생성된 두 개 이상의 인덱스가 병합되어 동시에 적용된다. 이때 전문 인덱스는 제외된다.
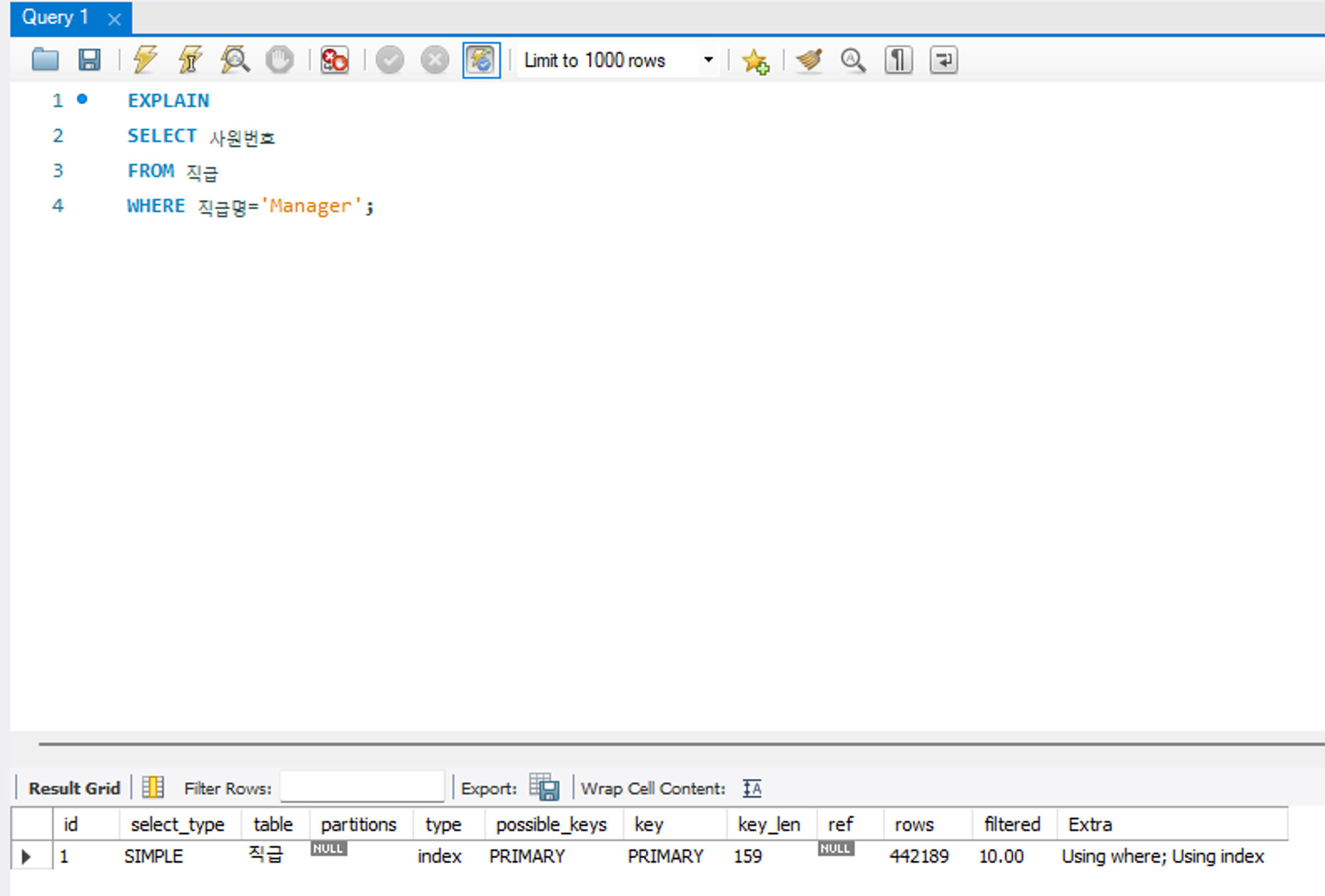
index
인덱스 풀 스캔을 의미한다. 즉, 물리적인 인덱스 블록을 처음부터 끝까지 훑는 방식을 말한다. 테이블 풀 스캔 방식보다 보통 빠르다.
all
테이블의 처음부터 끝까지 읽는 테이블 풀 스캔 방식에 해당되는 유형이다. 옵티마이저가 활용할 인덱스가 없거나, 인덱스를 활용하는 것이 비효율적이라고 판단할 때 선택된다.
인덱스 추가, 기존 인덱스 변경 등의 튜닝을 실행할 수 있으나, 전체 테이블의 10~20%이상 분량 데이터를 조회할 떄는 되려 성능상 all이 유리할 수 있다.
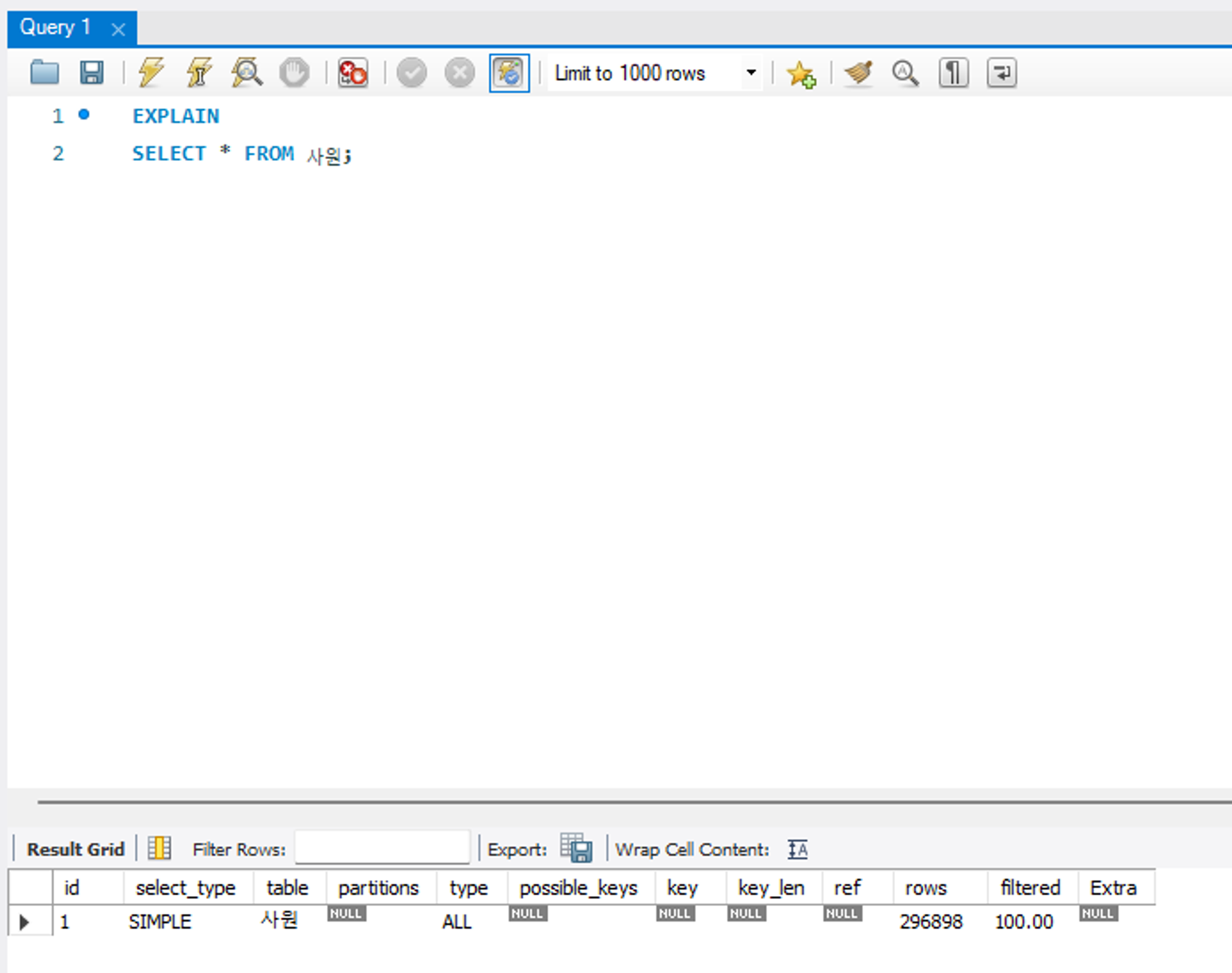
possible_keys
옵티마이저가 최적화에 사용할 수 있는 인덱스 목록을 출력한다. 실제 사용한 인덱스가 아닌 후보군 목록이다.
key
옵티마이저가 최적화를 위해 사용한 기본 키 또는 인덱스명을 의미한다. 비효율적인 인덱스를 사용했거나 인덱스 자체를 사용하지 않았다면 튜닝의 대상이 된다.
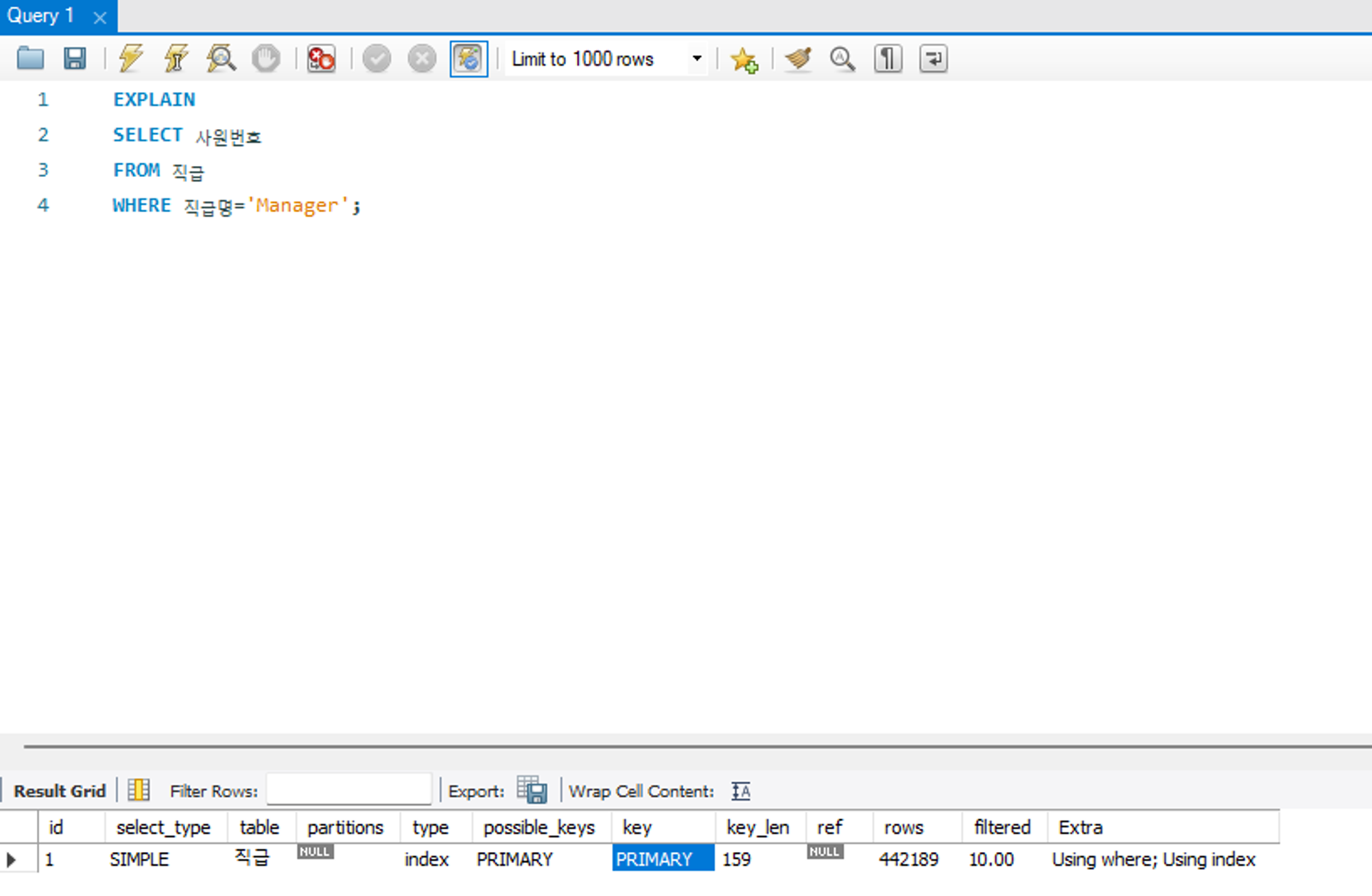
key_len
인덱스 사용시 전체 혹은 일부를 사용한다. 이 항목은 이렇게 사용한 인덱스의 바이트 수를 의미한다. UTF-8 캐릭터셋 기준 INT 는 단위당 4바이트, VARCHAR 는 단위당 3바이트임을 인지하자.
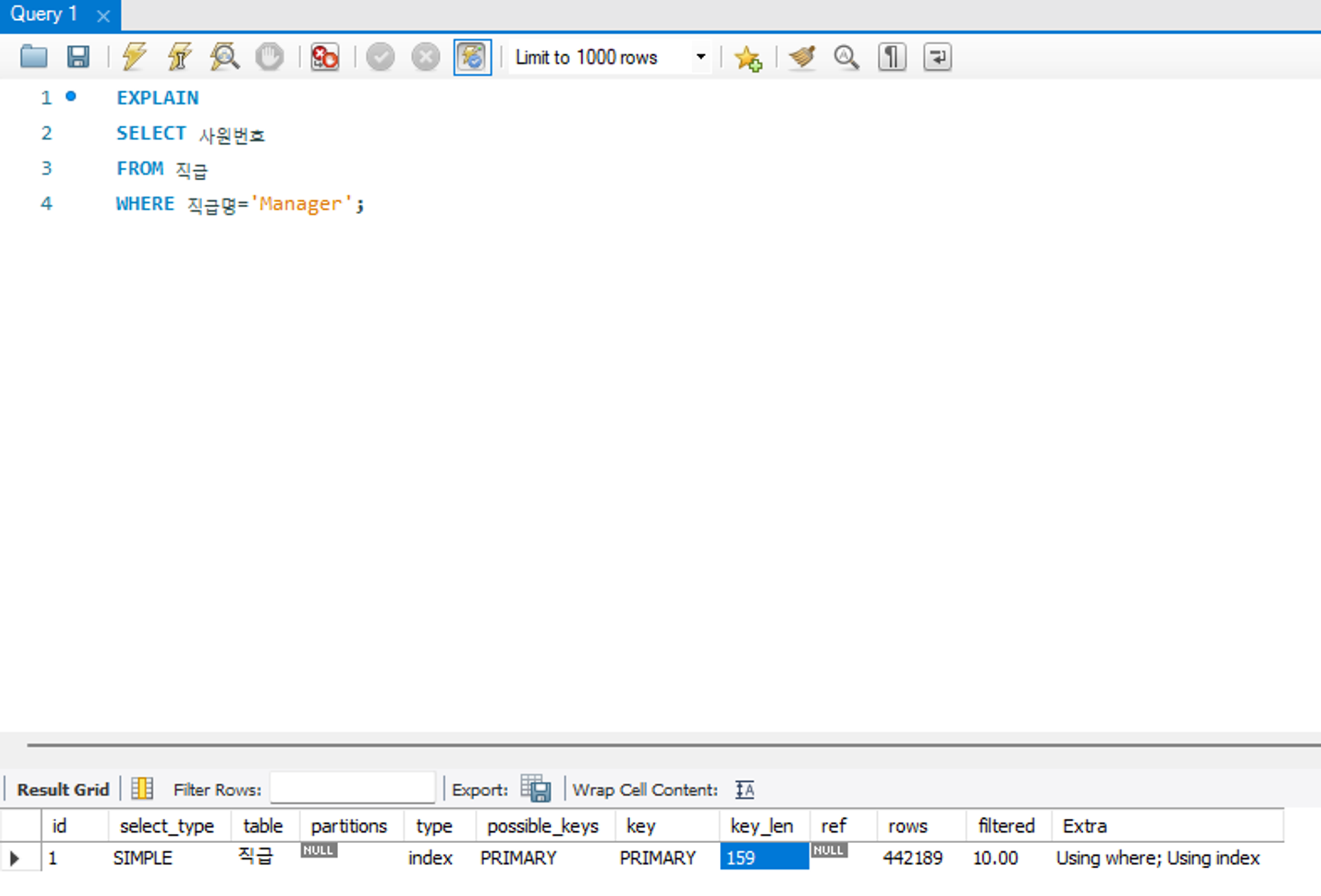
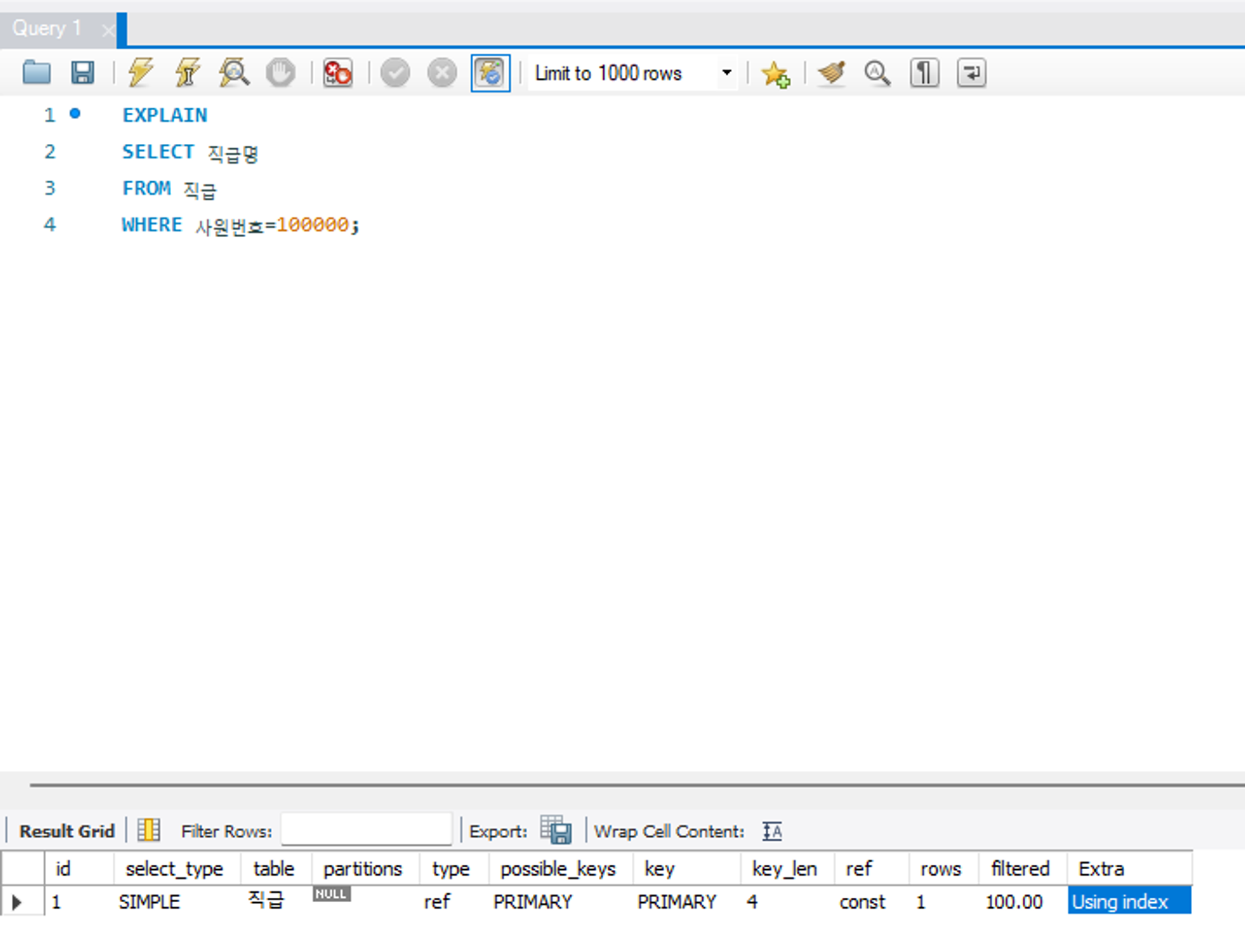
위 예시에서 사원번호+직급명+시작일자 로 구성된 PK는 사원번호가 INT 타입 4바이트, 직급명이 VARCHAR(50) 으로 에 해당한다. 즉, PK에서 사원번호+직급명 만 사용한 것을 알 수 있다.
ref
테이블 조인을 수행할 때 어떤 조건으로 해당 테이블에 액세스되었는지를 알려주는 정보이다.
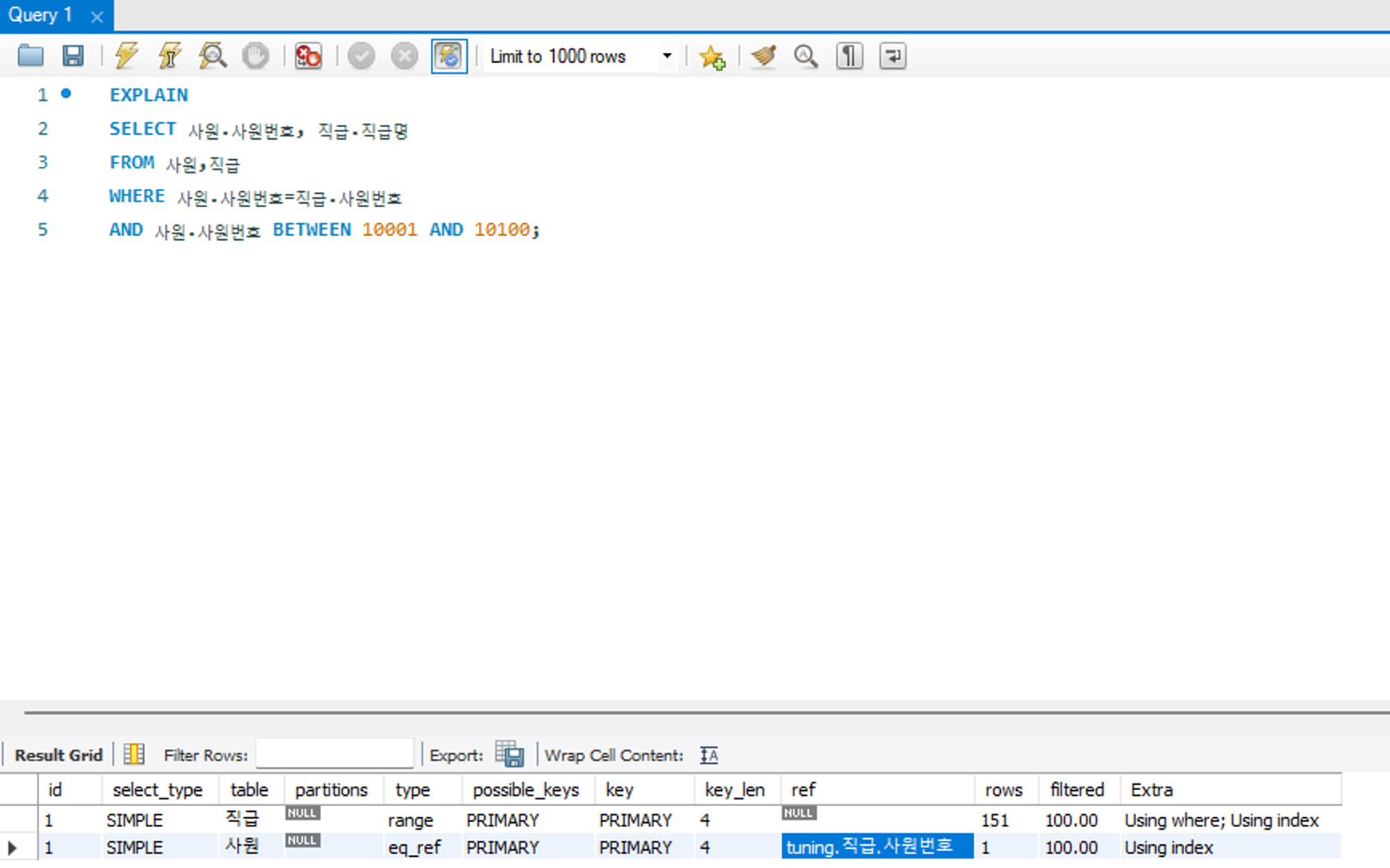
예시에서 드리븐 테이블인 직급 테이블의 데이터에 접근하면 사원번호로 데이터를 검색한다는 것을 알 수 있다.
rows
쿼리를 수행하고자 접근하는 데이터의 모든 행 수를 나타내는 예측 항목이다. 디스크에서 데이터 파일을 읽고 메모리에서 처리해야 할 행 수를 에상하는 값이고, 수시로 변동되는 통계정보를 참고하므로 정확하지 않다. 최종 결과 건수와 이 항목이 차이가 많이 날 때 불필요하게 MySQL 엔진까지 데이터를 많이 가져왔다는 의미이므로 튜닝이 필요할 수 있다.
filtered
DB 엔진으로 가져온 데이터 대상으로 필터 조건에 따라 어느 정도의 비율로 데이터를 제거했는지를 의미하는 항목이다. 단위는 %이다.
SELECT ... WHERE 사원번호 BETWEEN 1 AND 10위 쿼리에서 100건의 데이터를 DB 엔진으로 가져왔다면 조건에 따라 10건이 필터링되므로 filtered 에는 10이 출력될 것이다.
extra
쿼리를 어떻게 수행할 것인지에 관한 추가 정보를 보여주는 항목이다. ; 으로 구분하여 여러 정보를 나열할 수 있으며 관련한 모든 정보가 나타나는 것이 아니기 때문에 참고만 하는 것이 좋다.
Dinstinct
중복이 제거되어 유일한 값을 찾을 때 출력되는 정보이다. DINSTINCT , UNION 사용시 출력된다.
Using where
WHERE 절의 필터 조건을 사용해 DB 엔진으로 가져온 데이터를 추출할 것이란 의미를 가진다.
Using temporary
데이터의 중간 결과를 저장하고자 임시 테이블을 생성하겠다는 의미이다. 정렬, 중복 제거 작업 등을 수행한다. 성능 저하의 원인이 될 수 있기에 이 항목이 출력되면 튜닝의 대상이 될 수 있다.
Using index
인덱스만을 읽어서 쿼리의 요청사항을 처리할 수 있는 경우를 의미한다. 커버링 인덱스 방식이라고 부르며, 인덱스로 구성된 열만 쿼리에서 사용할 경우 이 방식을 활용한다. 적은 양의 데이터에 접근할 때 성능적으로 효율적이다.
Using filesort
정렬이 필요한 데이터를 메모리에 올리고 정렬을 수행한다는 의미이다. 인덱스를 사용하지 못할 때 발생할 수 있으며, 추가적인 정렬 작업이기에 쿼리 튜닝의 대상이 된다.
Using join buffer
조인 수행을 위해 중간 결과를 저장하는 조인 버퍼를 사용한다는 의미이다. 드라이빙 테이블의 결과를 조인 버퍼에 담고, 드리븐 테이블과 비교하는 과정을 수행한다.
Using union / Using intersect / Using sort_union
인덱스가 병합되어 실행되는 쿼리의 extra 항목에는 어떻게 병합했는지에 관한 상세 정보가 출력된다.
Using union:OR구문으로 작성되었을 시Using intersect:AND구문으로 작성된 경우Using sort_union:WHERE절의OR이 동등조건이 아닐 경우
Using index condition
필터 조건을 스토리지 엔진으로 전달하여 필터링 작업에 대한 MySQL 엔진의 부하를 줄이는 방식이다. 스토리지 엔진의 결과를 MySQL 엔진으로 전송하는 양을 줄여 성능 효율을 높일 수 있는 방식이다.
Using index for group-by
옵티마이저는 GROUP BY, DINSTINCT 구문이 포함될 때는 인덱스로 정렬 작업을 수행하여 최적화한다. 인덱스 루스 스캔 발생시 출력되는 정보이다.
Not exists
하나의 일치되는 행을 찾으면 추가로 행을 더 검색하지 않아도 될 때 출력되는 유형이다. 외부 조인에서 테이블에 존재하지 않는 데이터를 명시적으로 검색할 때 발생한다.
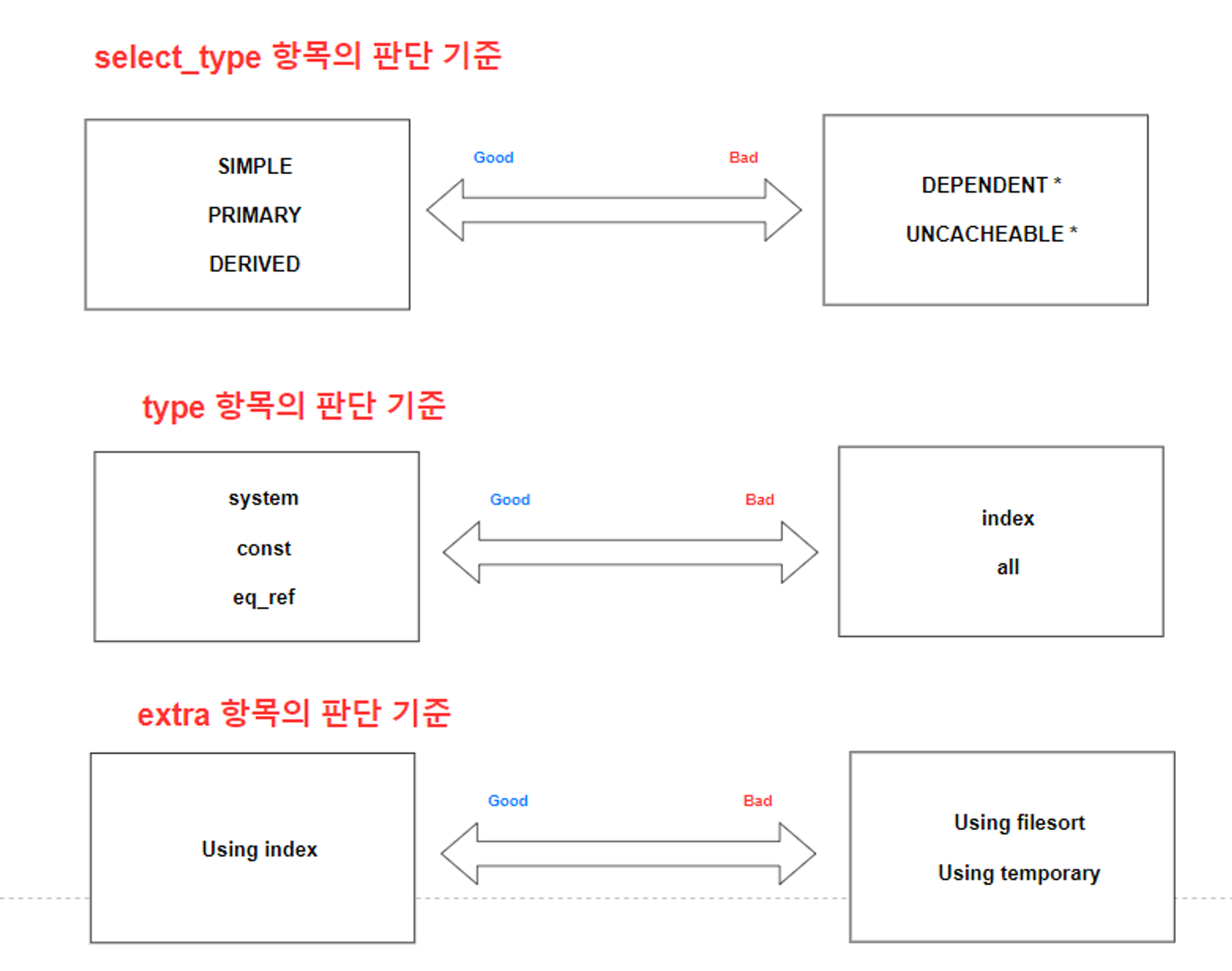
좋고 나쁨을 판단하는 기준
튜닝을 검토할 때 다음 기준을 참고할 수 있다.
확장된 실행 계획 수행
추가 정보를 확인하고자 한다면 DB에서 각각 지원하는 키워드를 입력할 수 있다.
MySQL의 확장된 실행 계획 수행
EXPLAIN FORMAT = TRADITIONAL
기본 포맷이다.
EXPLAIN FORMAT = TRADITIONAL
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 100001 AND 200000;EXPLAIN FORMAT = TREE
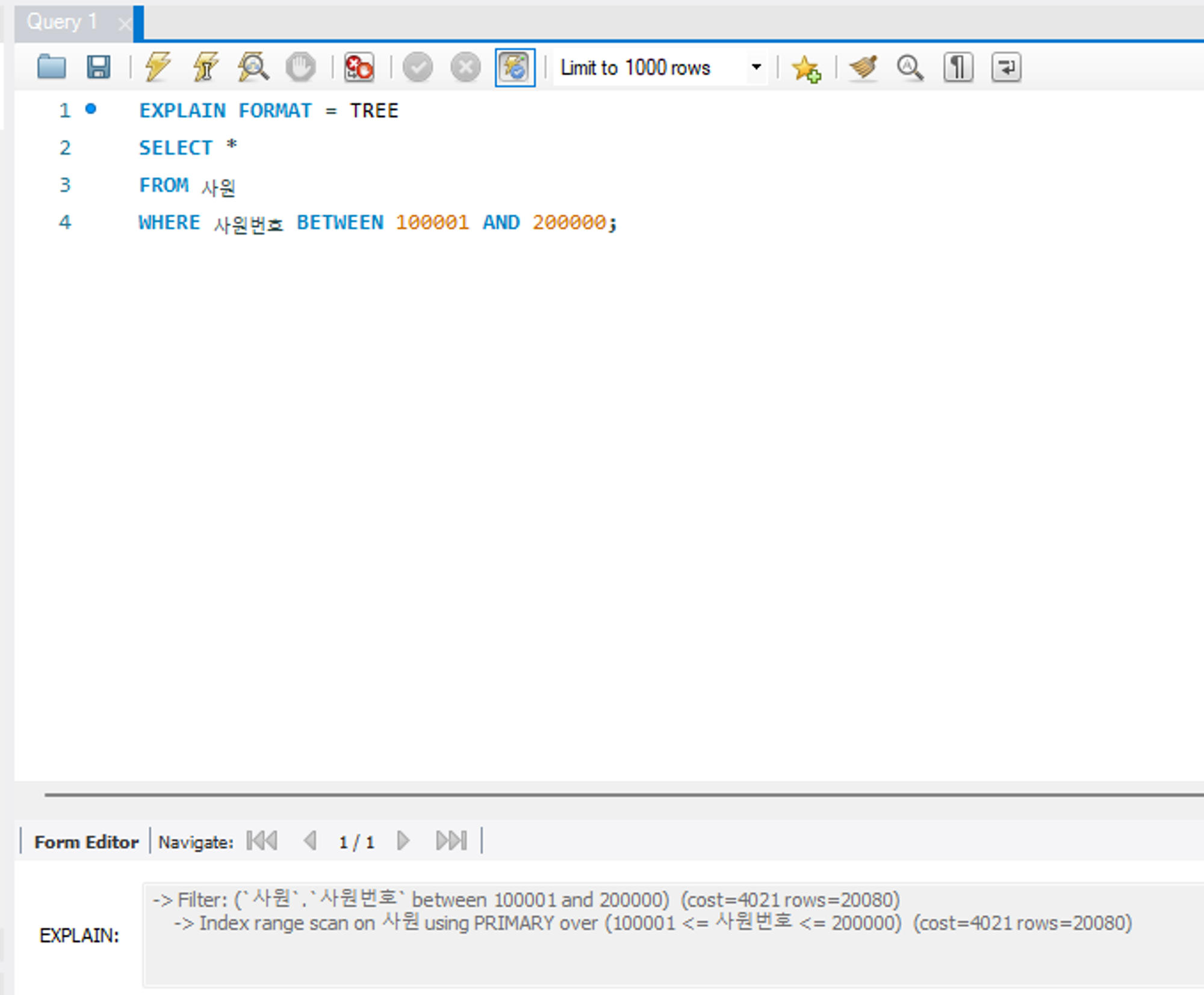
트리 형태로 추가된 실행 계획 항목을 확인할 수 있다.
EXPLAIN FORMAT=JSON
EXPLAIN FORMAT = JSON
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 100001 AND 200000;JSON 형태로 항목을 확인할 수 있다.
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "4021.24"
},
"table": {
"table_name": "사원",
"access_type": "range",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"사원번호"
],
"key_length": "4",
"rows_examined_per_scan": 20080,
"rows_produced_per_join": 20080,
"filtered": "100.00",
"cost_info": {
"read_cost": "2013.24",
"eval_cost": "2008.00",
"prefix_cost": "4021.24",
"data_read_per_join": "1M"
},
"used_columns": [
"사원번호",
"생년월일",
"이름",
"성",
"성별",
"입사일자"
],
"attached_condition": "(`tuning`.`사원`.`사원번호` between 100001 and 200000)"
}
}
} EXPLAIN ANALYZE
앞선 출력된 실행 계획은 예측된 실행 계획에 관한 정보이다. 실제 측정한 실행 계획을 출력하고 싶다면 ANALYZE 키워드를 사용한다. 예측 실행 계획, 실측 실행 계획을 모두 출력하려면 EXPLAIN ANALYZE 키워드를 활용한다.
