
기본 키를 변형하는 나쁜 SQL문
현황 분석
튜닝 전 SQL
SELECT *
FROM 사원
WHERE SUBSTRING(사원번호, 1, 4) = 1100
AND LENGTH(사원번호)=5튜닝 전 수행 결과
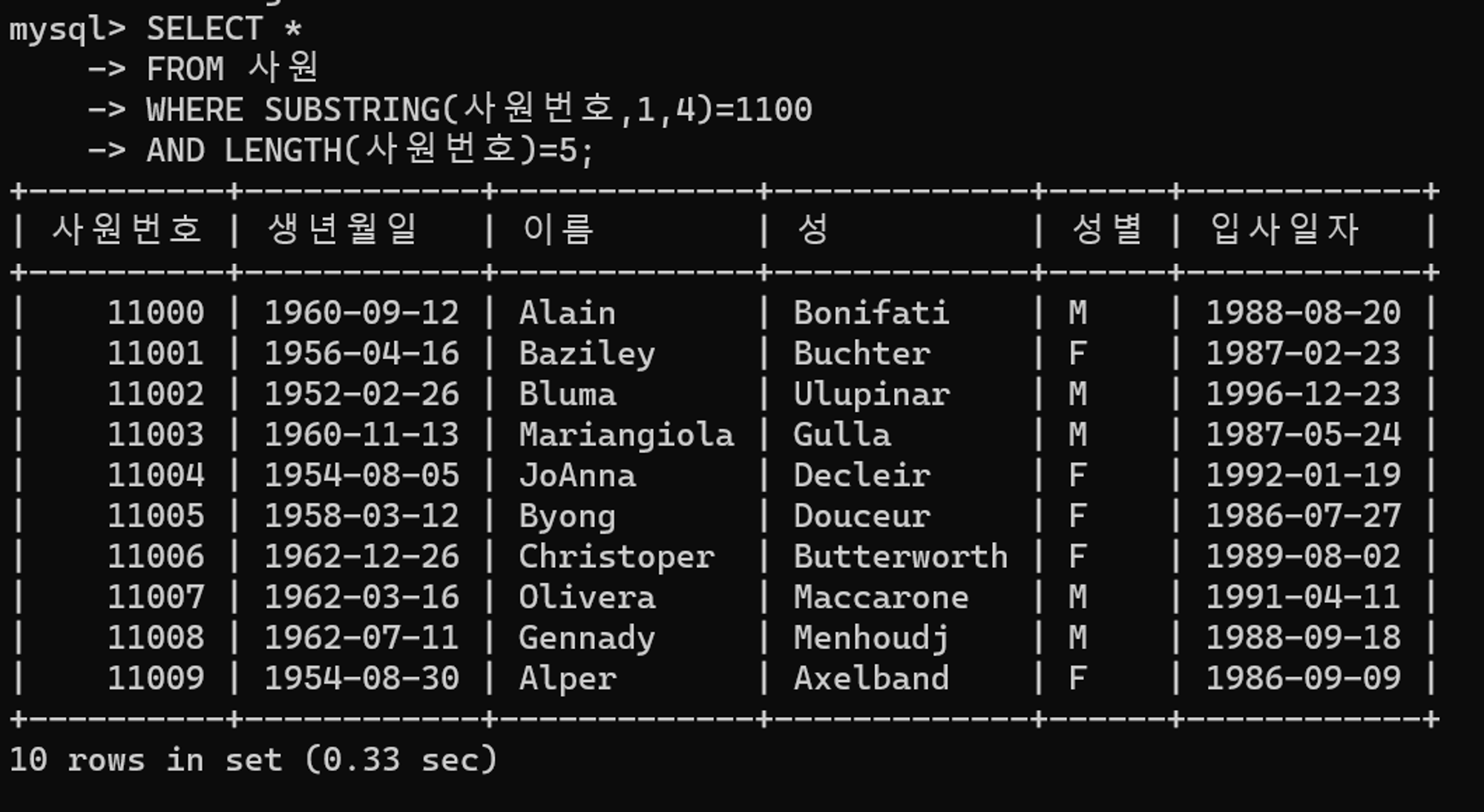
10건의 데이터가 조회되며, 0.33초가 소요되었다.
튜닝 전 실행계획
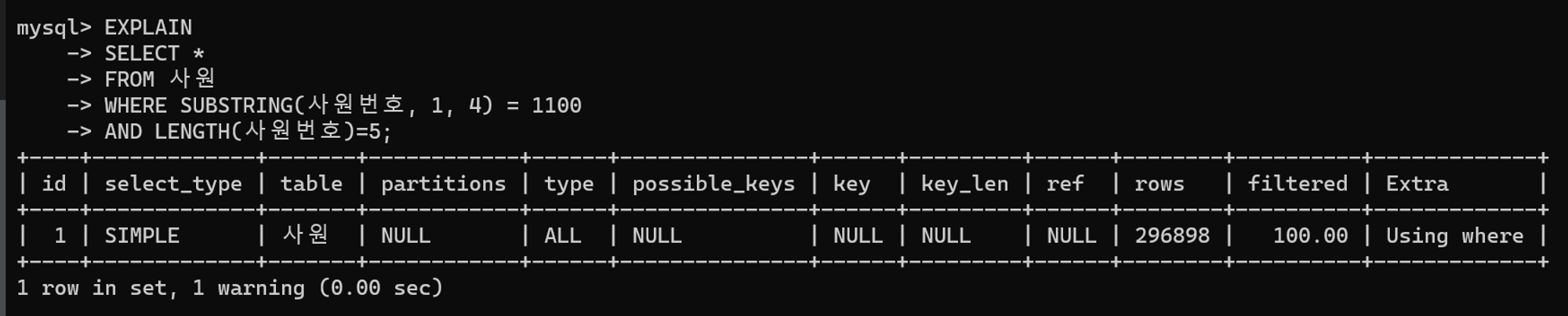
Type 항목이 ALL이므로 테이블 풀 스캔 방식이며, 인덱스를 사용하지 않는 형태로 비효율적인 것을 파악할 수 있다.
튜닝 수행
튜닝 전 SQL문에서는 사원번호를 SUBSTRING, LENGTH 를 이용하여 가공하여 사용하기 때문에, 기본 키를 사용하지 못하고 테이블 풀 스캔을 수행하게 된다. 따라서 가공된 사원번호 열을 변경하여 기본 키를 사용할 수 있게 조정하는 것이 좋다.
튜닝 결과
튜닝 후 SQL문
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 11000 AND 11009위와 같이 작성하면 사원번호를 변형하지 않아 기본키를 활용하게 된다. 아래와 같이 작성할 수도 있다.
SELECT *
FROM 사원
WHERE 사원번호 >= 11000 AND 사원번호 <= 11009튜닝 후 수행 결과
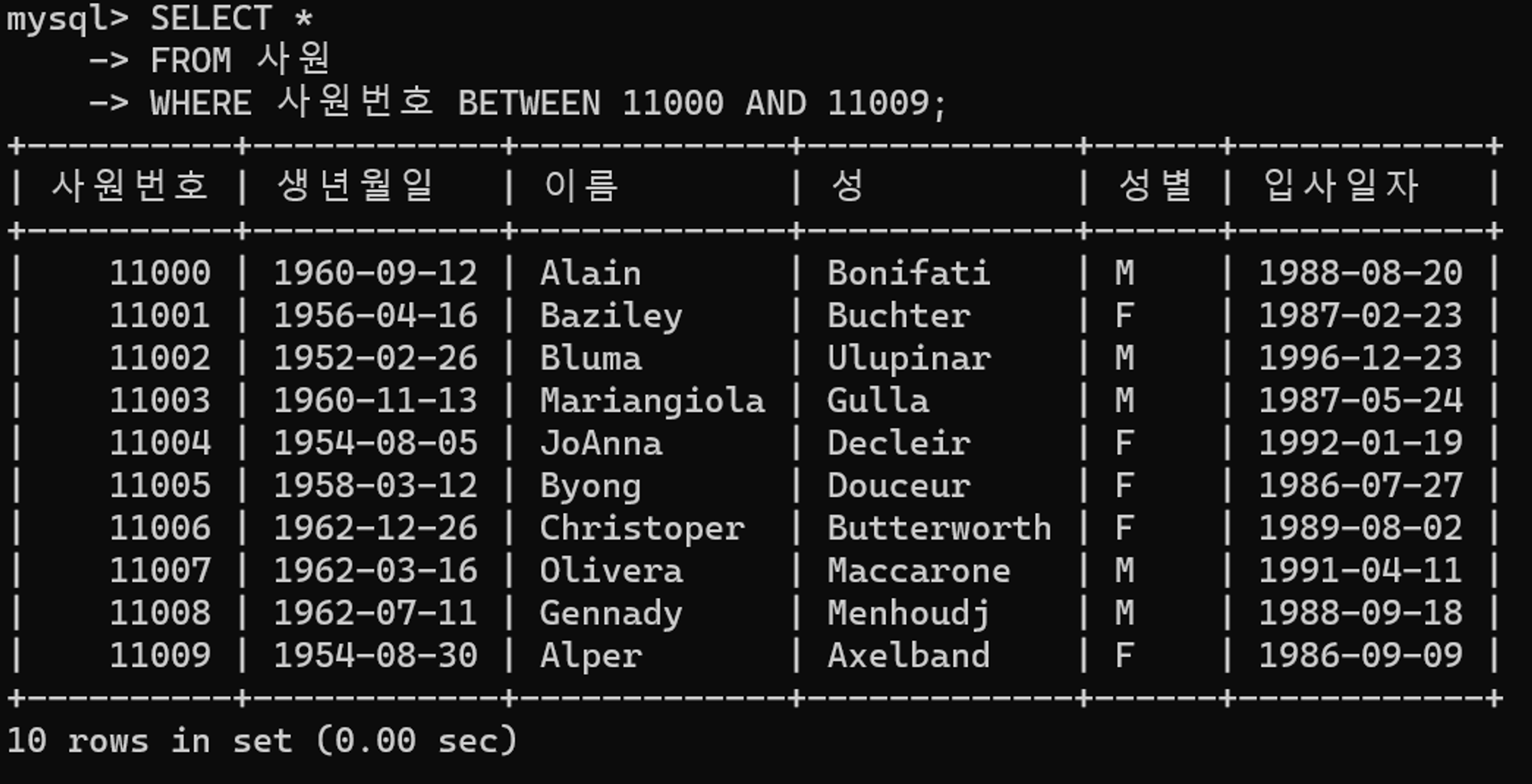
0.23에서 0.00으로 수행 시간이 향상되었다.
튜닝 후 실행 계획

key : PRIMARY , Type : range 항목을 통해 기본 키 범위 스캔을 수행하는 것을 확인할 수 있다.
사용하지 않는 함수를 포함하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT IFNULL(성별, 'NO DATA') AS 성별, COUNT(1) 건수
FROM 사원
GROUP BY IFNULL(성별, 'NO DATA')사원 테이블에서 성별을 기준으로 몇 명의 사원이 있는지 출력하는 쿼리이다.
튜닝 전 수행 결과
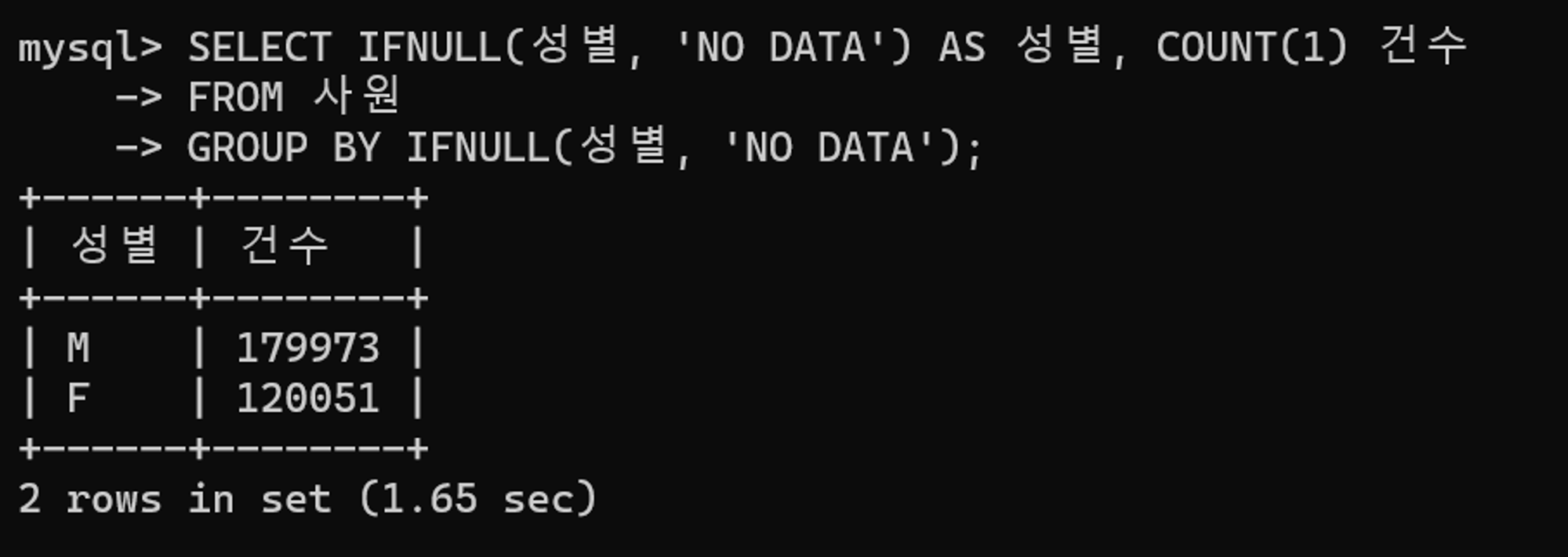
2개 행이 출력되며, 1.65초가 소요된다.
튜닝 전 실행 계획

I_성별_성 인덱스 풀 스캔 방식으로 수행되며, Extra : Using temporary 항목에서 임시 테이블을 생성하다는 것을 알 수 있다.
튜닝 수행
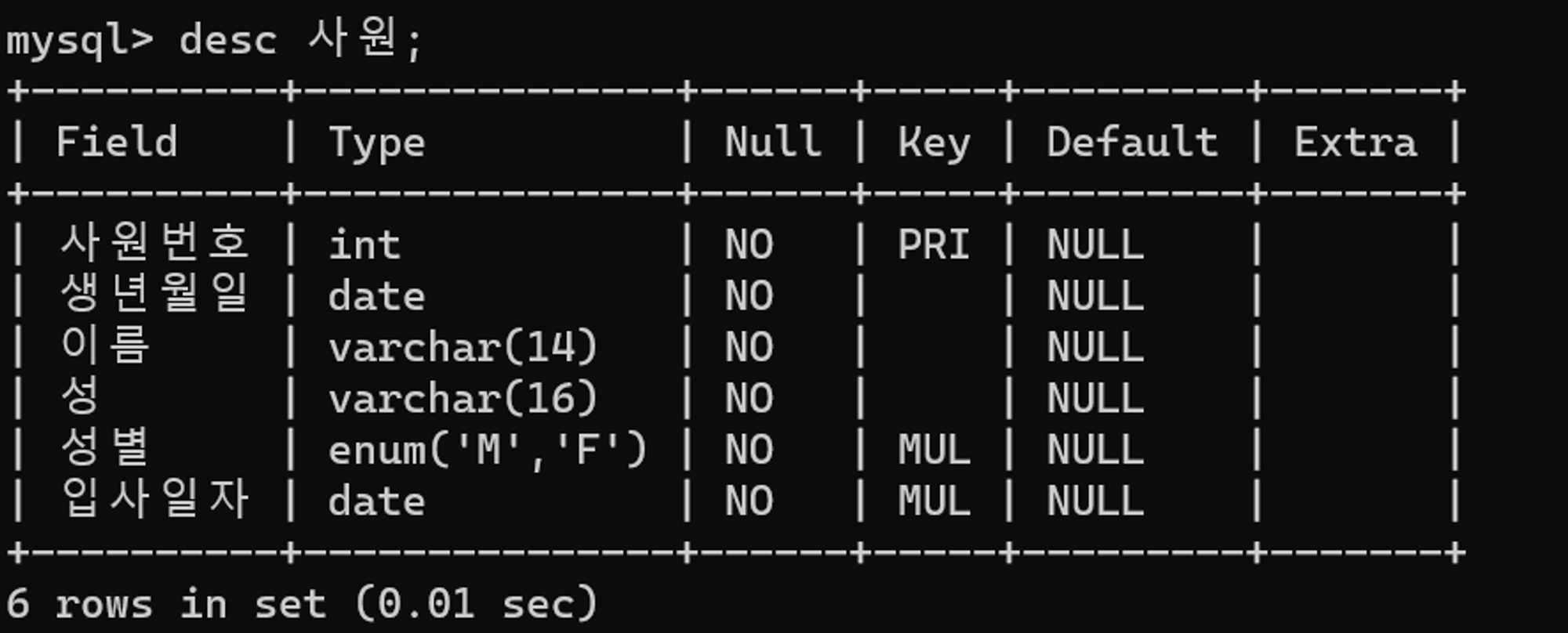
위 테이블 스키마와 SQL 실행 결과를 통해 NULL 데이터가 성별 칼럼에 존재할 수 없음을 알 수 있다. 따라서 ISNULL 을 굳이 사용하여 DB 내부적으로 별도의 임시 테이블을 만들게 할 필요가 없다.
튜닝 결과
튜닝 후 SQL문
SELECT 성별, COUNT(1) 건수
FROM 사원
GROUP BY 성별불필요한 IFNULL 을 제거한다.
튜닝 후 수행 결과
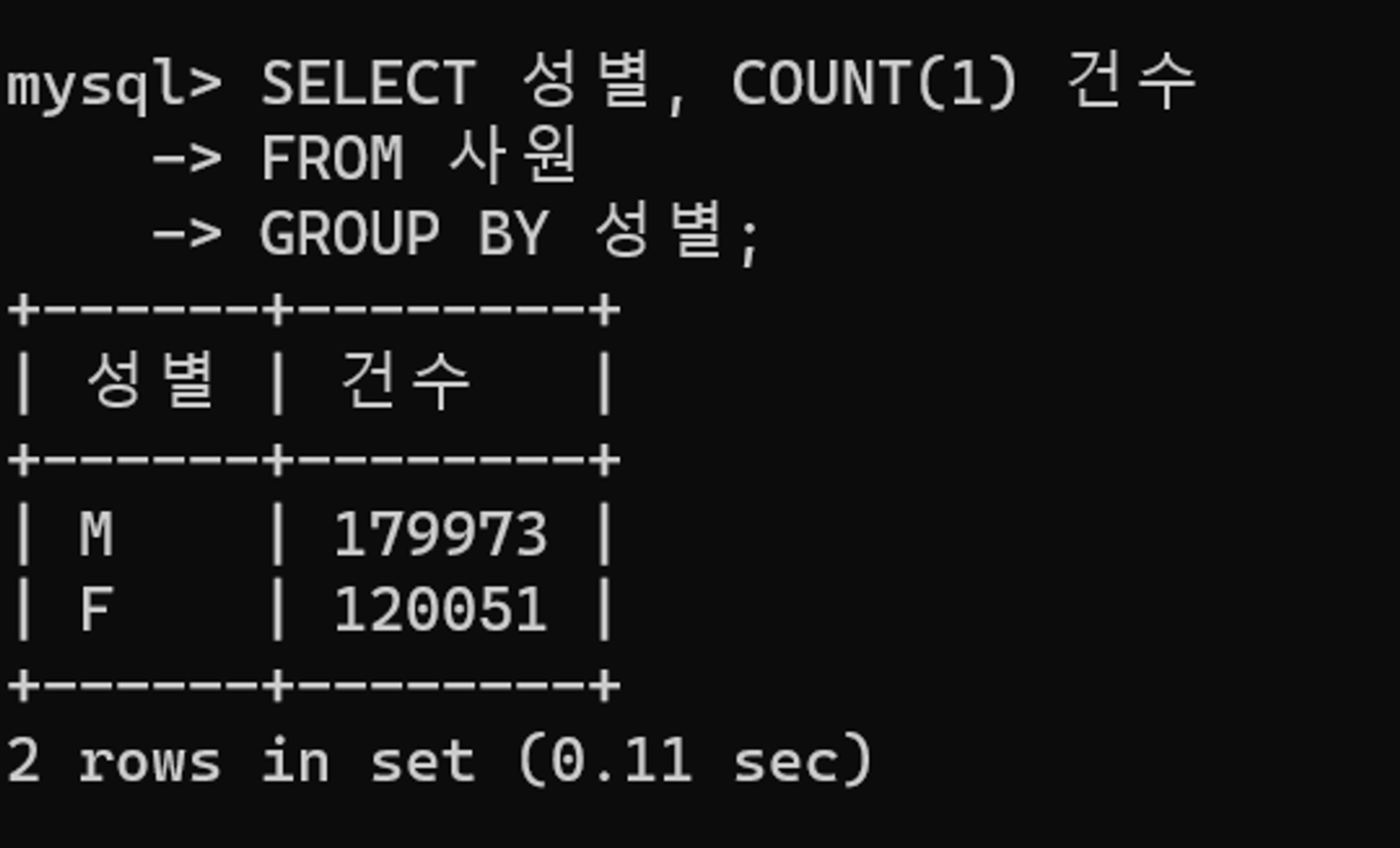
소요 시간이 0.11초로 향상되었다.
튜닝 후 실행 계획

key : I_성별_성 을 통해 인덱스 풀 스캔으로 수행되며, Extra : Using index 를 통해 임시 테이블 없이 인덱스만을 사용하는 것을 확인할 수 있다.
형변환으로 인덱스를 활용하지 못하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT COUNT(*)
FROM 급여
WHERE 사용여부=1유효한 급여 정보만을 조회하기 위한 쿼리이다.
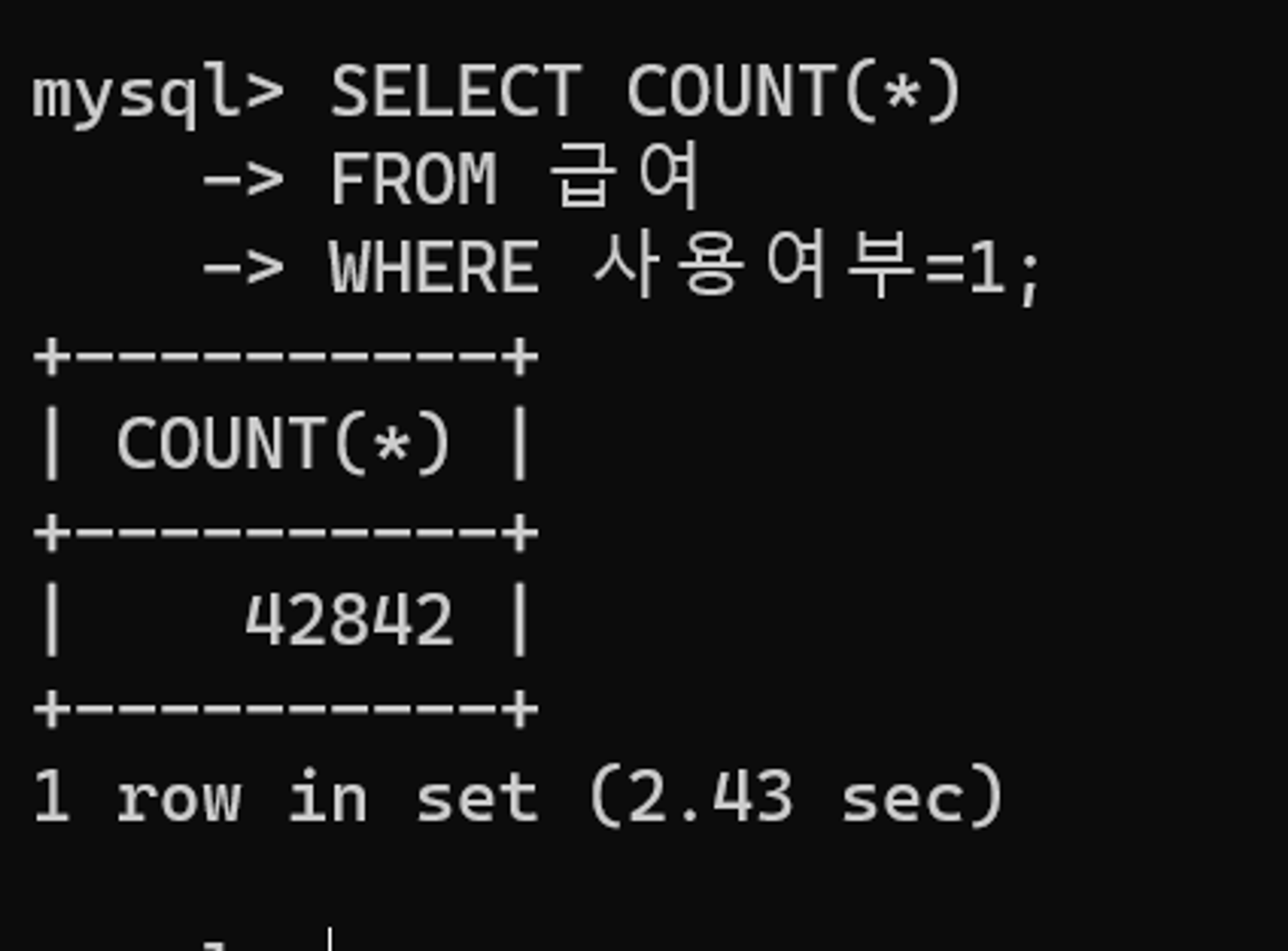
튜닝 전 수행 결과
튜닝 전 실행 계획

key : I_사용여부 , type : index 를 통해 인덱스 풀스캔이 수행된다고 해석할 수 있다. 또한 filtered 항목이 10.00이므로 MySQL 엔진으로 가져온 데이터중 10%를 추출한다고 파악할 수 있다. rows 항목에 표시되는 2,838,398건의 데이터를 MySQL 엔진으로 가져온 뒤 10%인 28만 건의 데이터만 솎아내는 것이다.
튜닝 수행
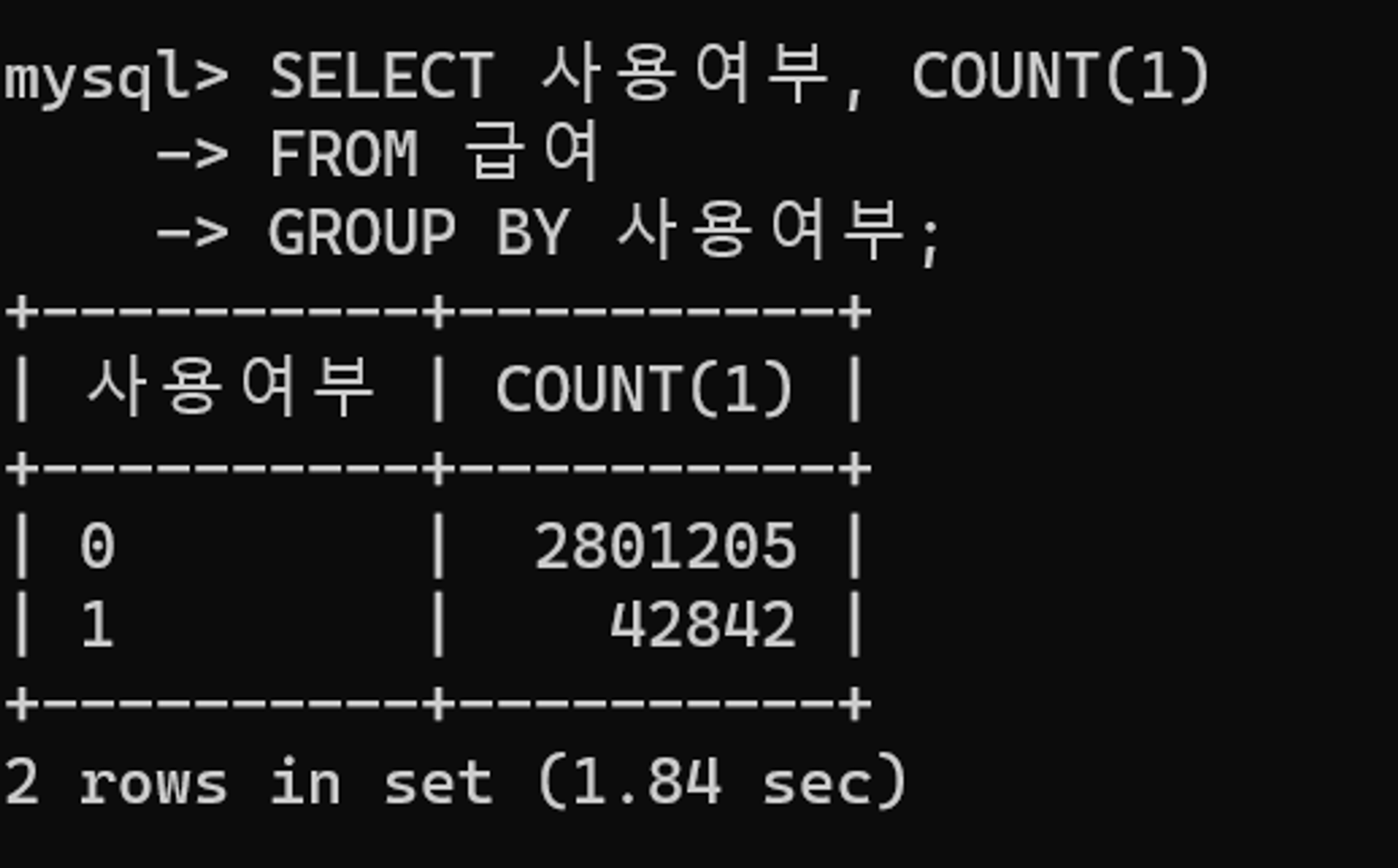
다음 쿼리를 통해 사용여부 열의 데이터 건수를 확인해보자. 사용여부 열이 1인 데이터 건수는 전체 대비 10% 이하임을 확인할 수 있다.
이어서 아래 쿼리를 통해 테이블 인덱스 현황을 살펴보면 Key_name 항목에 사원번호와 시작일자로 구성된 기본키와 I_사용여부가 표시됨을 알 수 있다.

튜닝 대상 SQL문에서 사용여부 열이 인덱스로 구성되었고 WHERE 절의 조건문으로 작성되었음에도 실행 계획에서는 인덱스 풀 스캔이 수행되므로 테이블 구조를 살펴봐야 한다.
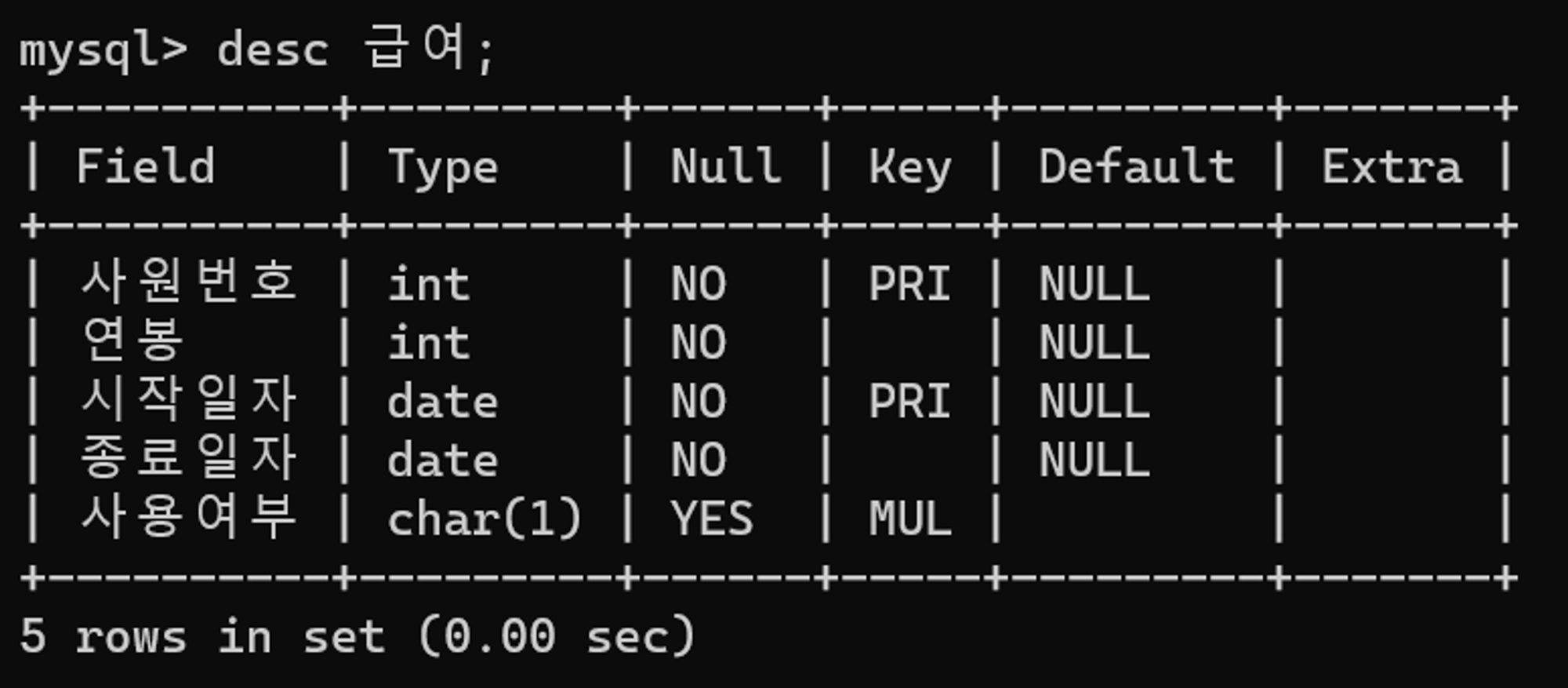
사용여부 열의 타입은 CHAR(1) 인데 WHERE 사원번호=1 과 같이 접근하여 DBMS 내부에서 묵시적 형변환이 발생하여 인덱스를 활용하지 못했던 이유였다.
튜닝 결과
튜닝 후 SQL문
SELECT COUNT(1)
FROM 급여
WHERE 사용여부='1'튜닝 후 수행 결과
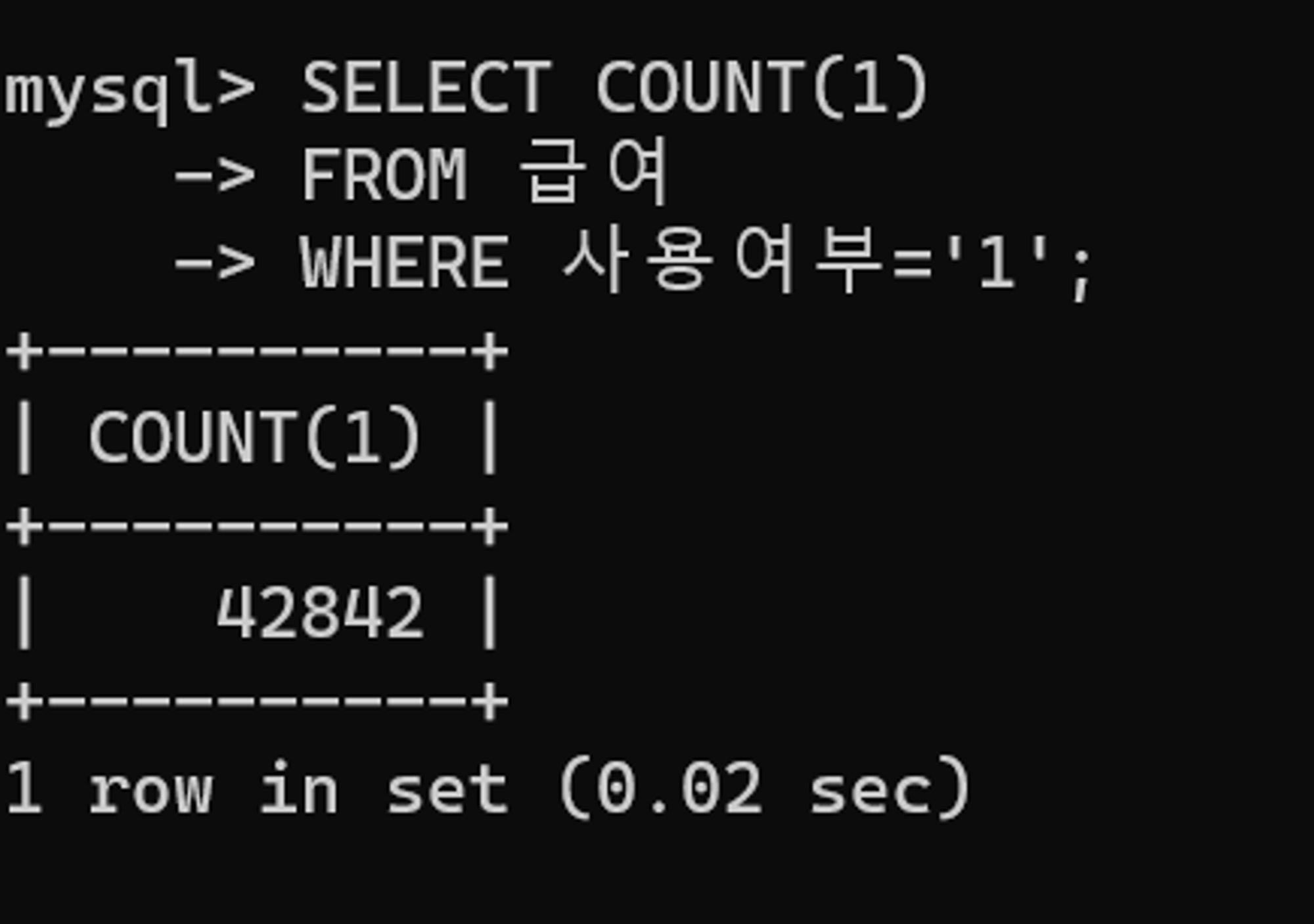
소요 시간이 0.02초로 개선되었다.
튜닝 후 실행 계획

key : I_사용여부 항목에서 인덱스를 활용하는 것을 알 수 있고, 튜닝 전과 달리 조건절을 통해 필요한 데이터만 MySQL 엔진으로 가져왔음을 확인할 수 있다. (filtered : 100 )
열을 결합하여 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
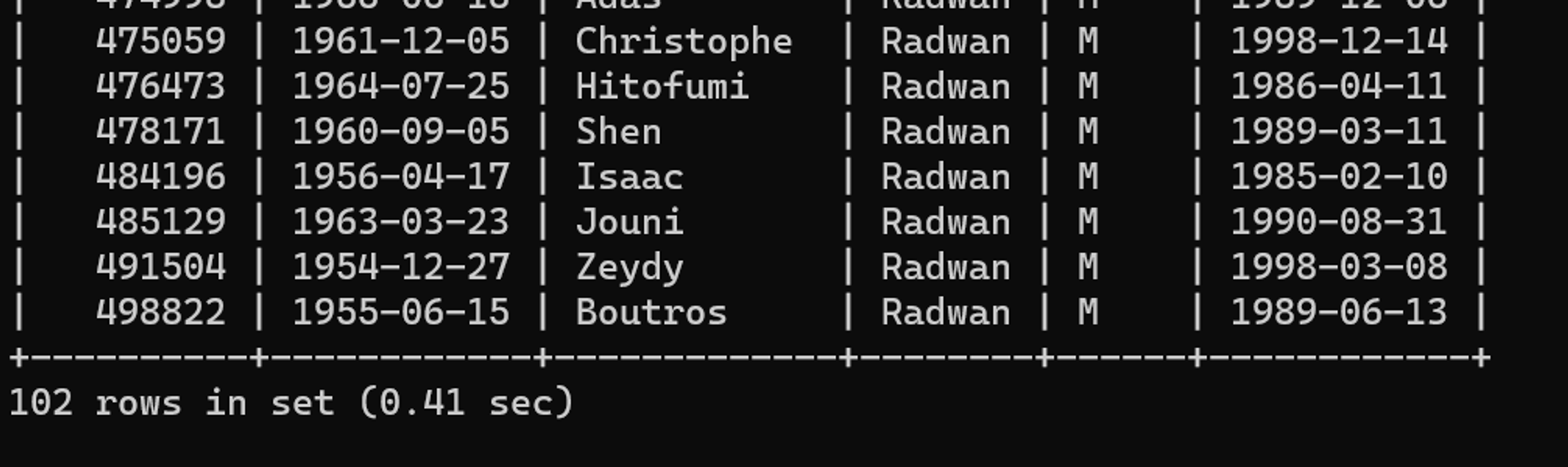
SELECT *
FROM 사원
WHERE CONCAT(성별, ' ', 성) = 'M Radwan'튜닝 전 수행 결과
튜닝 전 실행 계획

CONCAT(성별, ' ', 성)='M Radwan' 을 통해 사원 테이블에 접근하지만 type : ALL 을 통해 테입ㄹ 풀 스캔을 수행하므로 비효율적이다.
튜닝 수행
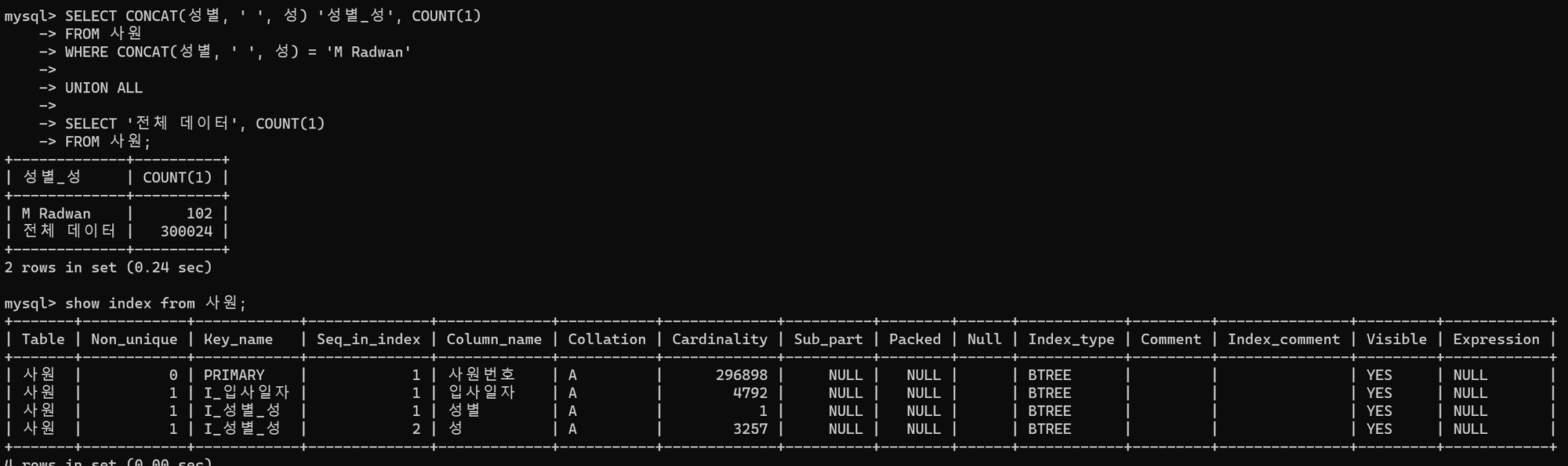
조회하려는 데이터는 102건이고 사원 테이블에 성별 + 성 칼럼으로 구성된 I_성별_성 인덱스가 존재하는 것을 확인할 수 있다. 조건문이 동등 조건이므로 인덱스를 활용하면 빠르게 데이터 조회가 가능하다.
튜닝 결과
튜닝 후 SQL문
SELECT *
FROM 사원
WHERE 성별 = 'M'
AND 성 = 'Radwan'튜닝 전의 CONCAT 을 통한 열의 변경을 제거하였다.
튜닝 후 수행 결과
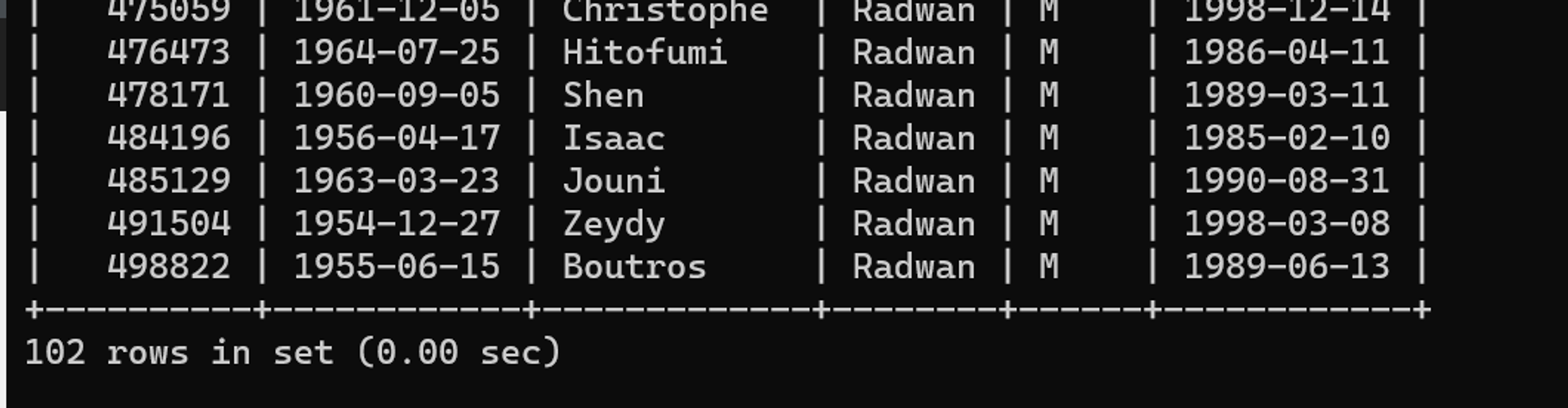
0.00초로 수행 시간이 개선되었다.
튜닝 후 실행 계획

인덱스 풀 스캔을 사용하여 튜닝 전에 비해 접근하는 데이터량이 102건으로 줄었음을 알 수 있다.
습관적으로 중복을 제거하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
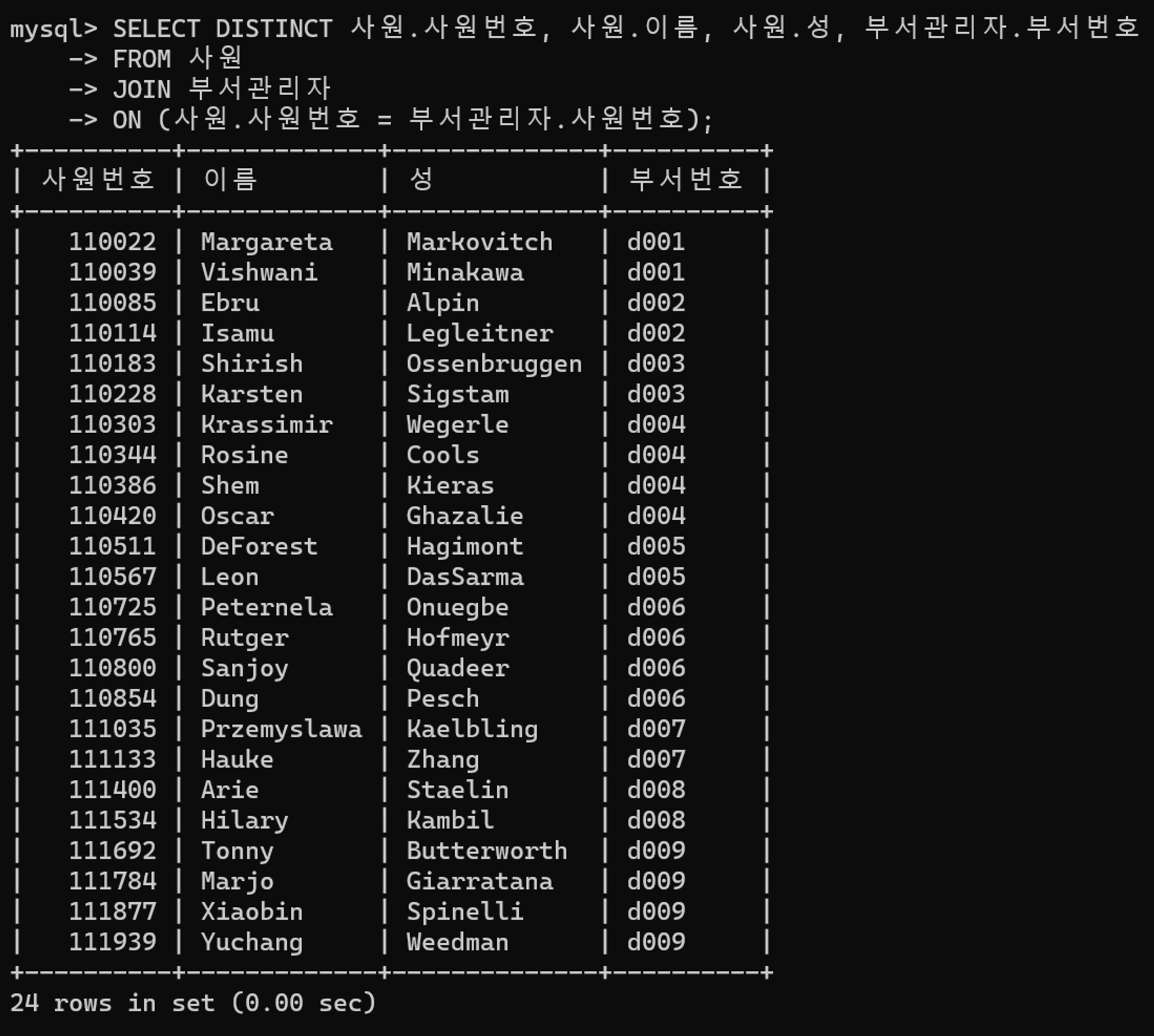
SELECT DISTINCT 사원.사원번호, 사원.이름, 사원.성, 부서관리자.부서번호
FROM 사원
JOIN 부서관리자
ON (사원.사원번호 = 부서관리자.사원번호)조회하는 열 조합에서 중복을 제거하는 쿼리이다.
튜닝 전 수행결과
튜닝 전 실행계획

- 드라이빙 테이블은 부서관리자이고 드리븐 테이블은 사원이다.
id값이 둘 다 1이므로 서로 조인한다고 해석할 수 있다.- 부서관리자의
type : index이므로 인덱스 풀 스캔 방식으로 수행된다. - 사원 테이블의
type : eq_ref이므로 사원번호라는 기본키를 사용해 단 1건의 데이터를 조회하는 방식으로 볼 수 있다. Extra : Using temporary에서DINSTINCT를 수행하고자 별도의 임시 테이블을 생성함을 알 수 있다.
튜닝 수행
사원 테이블의 기본 키는 사원번호인데 굳이 DISTINCT 를 통해 정렬 후 중복 제거 작업을 해야하는 지 고민해볼 필요가 있다.
DINSTINCT 사용 시에는 정렬 작업이 항상 수반되므로 사용 시 주의하자
튜닝 결과
튜닝 후 SQL문
SELECT 사원.사원번호, 사원.이름, 사원.성, 부서관리자.부서번호
FROM 사원
JOIN 부서관리자
ON (사원.사원번호 = 부서관리자.사원번호)불필요한 DINSTINCT 를 제거하였다.
튜닝 후 수행결과
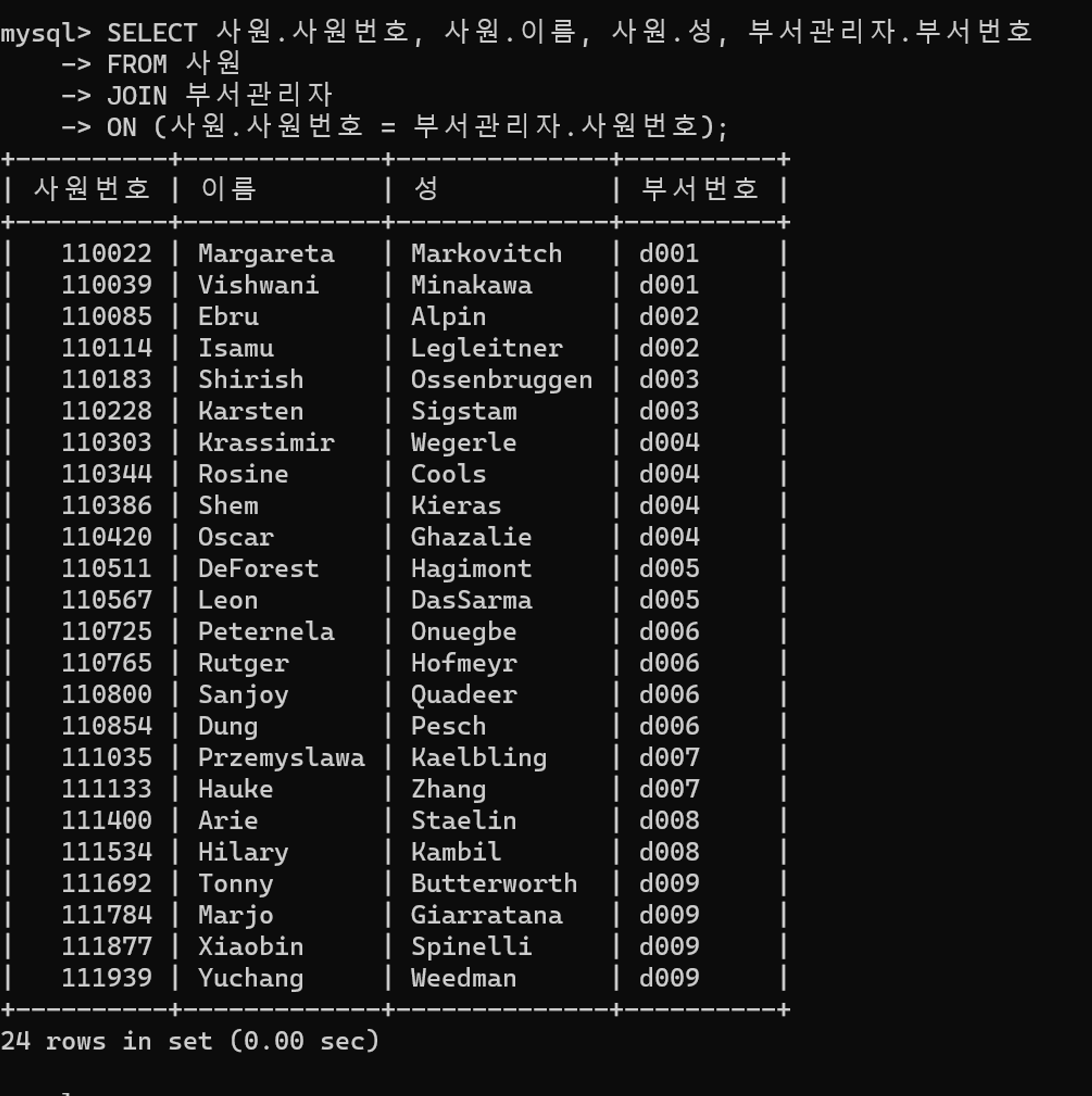
수행 시간이 동일하므로 결과를 통해서 튜닝 여부를 판단하기는 어렵다.
튜닝 후 실행계획

extra : Using temporary 항목이 DISTINCT 키워드 제거에 따라 정렬, 중복 제거를 수행하지 않아도 되므로 삭제되었다.
다수 쿼리를 UNION 연산자로만 합치는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT 'M' AS 성별, 사원번호
FROM 사원
WHERE 성별 = 'M'
AND 성 = 'Baba'
UNION
SELECT 'F', 사원번호
FROM 사원
WHERE 성별 = 'F'
AND 성 = 'Baba'다른 성별에서 성이 Baba 인 데이터를 UNION 을 통해 합쳐 조회하고 있다.
튜닝 전 수행 결과
작은 데이터를 조회하므로 소요 시간이 짧다. 하지만 실행 계획을 포함해 종합적으로 판단할 필요가 있다.
튜닝 전 실행 계획
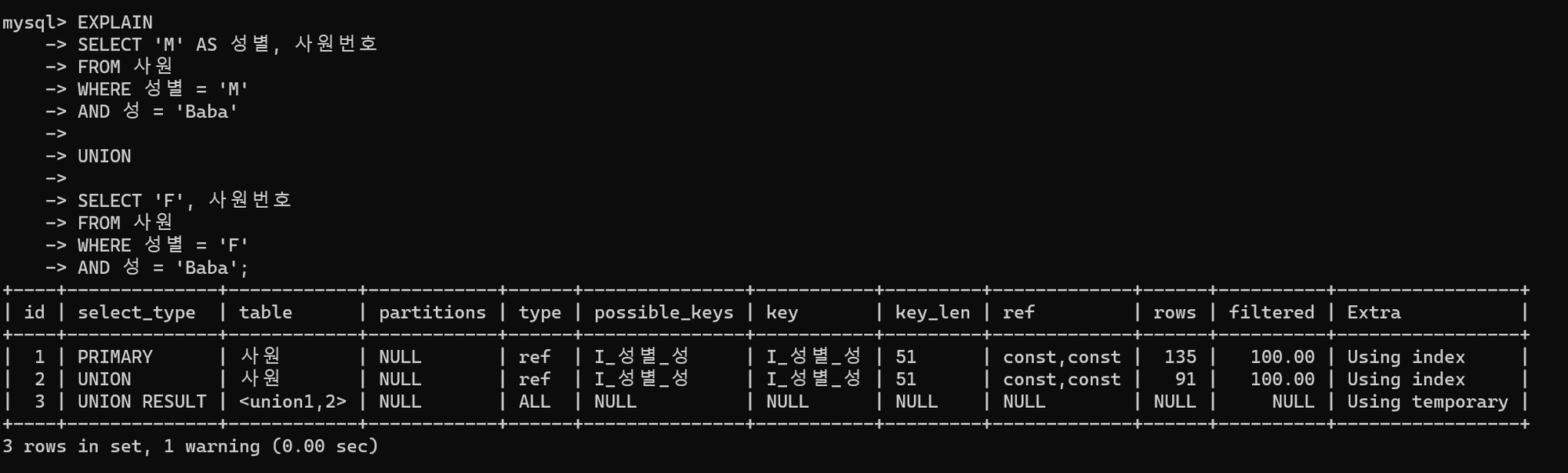
id=NULL 인 세번째 행에서 UNION 연산 작업을 위해 메모리에 임시 테이블(extra : Using temporary )을 생성하는 것을 알 수 있다. 하지만 만약 연산 대상 데이터량이 메모리에 상주하기 힘들 정도로 많다면 디스크에 임시 파일을 생성하여 작업을 수행하게 된다.
튜닝 수행
SQL문에서 WHERE 절에 성별, 성 칼럼이 동등 조건으로 작성되어 있다. 따라서 I_성별_성 인덱스를 활용하여 데이터를 빠르게 조회할 것이다. 이후 UNION 작업을 수행할텐데 이미 사원번호라는 기본키가 출력되는 SQL문에서 중복 제거 과정이 필요한지 고민해봐야 한다.
튜닝 결과
튜닝 후 SQL문
SELECT 'M' AS 성별, 사원번호
FROM 사원
WHERE 성별 = 'M'
AND 성 = 'Baba'
UNION ALL
SELECT 'F', 사원번호
FROM 사원
WHERE 성별 = 'F'
AND 성 = 'Baba'두 대상 테이블의 데이터가 중복되지 않으므로 중복 제거 작업이 필요치 않다. 따라서 결괏값을 단순히 합치는 UNION ALL 로 대체한다.
튜닝 후 수행 결과
결과를 가지고 튜닝 성공 여부를 판단하기 어렵다.
튜닝 후 실행 계획
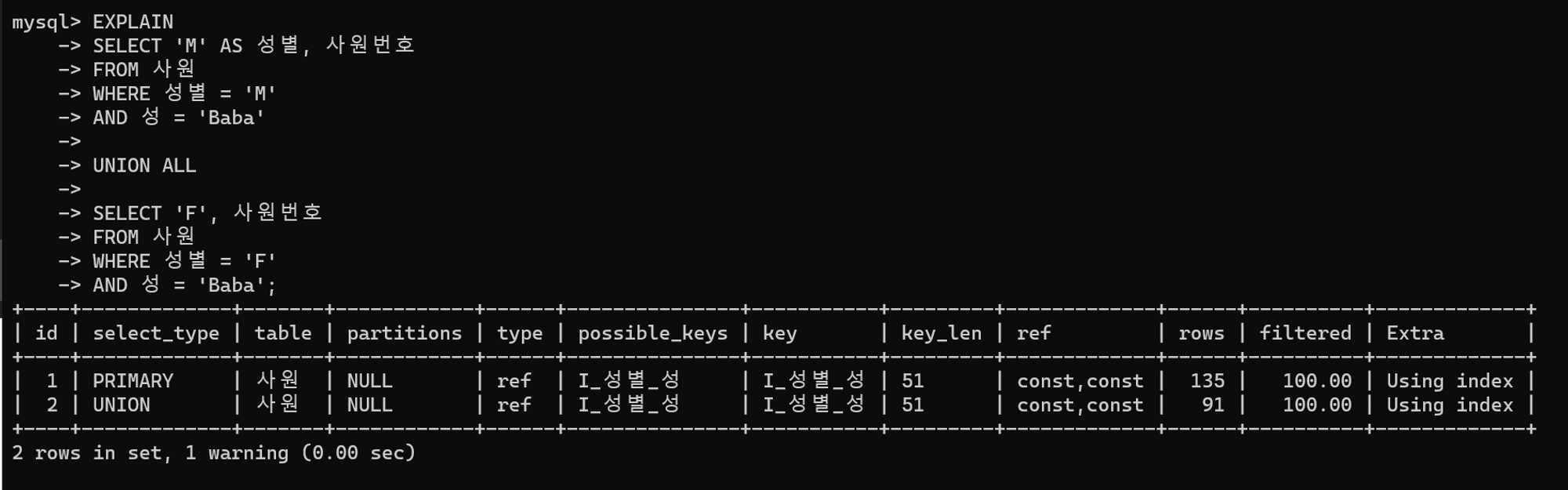
결과를 단순히 합치므로 불필요한 정렬, 중복 제거 작업이 제외되어 리소스 낭비를 방지하게 되었다.
인덱스 고려 없이 열을 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT 성, 성별, COUNT(1) as 카운트
FROM 사원
GROUP BY 성, 성별성,성별순으로 그루핑하여 데이터를 조회한다.
튜닝 전 수행 결과
튜닝 전 실행 계획

I_성별_성 인덱스를 활용하고, 임시 테이블을 생성해 성, 성별을 그루핑하여 카운팅 연산을 수행한다. 인덱스의 구성이 GROUP BY 절에 포함되므로 테이블 접근 없이 인덱스만 사용하는 커버링 인덱스(extra : Using index)로 수행된다.
튜닝 수행
인덱스를 활용하는 데도 임시 테이블을 꼭 생성해야할지 고민해봐야 한다. I_성별_성 인덱스는 성별, 성 순으로 생성된 오브젝트인데 이 순서를 활용할 수 없을까?
튜닝 결과
튜닝 후 SQL문
이미 존재하는 인덱스를 최대한 활용하려면 인덱스 순서대로 그루핑하면 된다. 그러면 별도의 임시 테이블을 생성하지 않고 연산 수행이 가능하다.
SELECT 성, 성별, COUNT(1) as 카운트
FROM 사원
GROUP BY 성별, 성튜닝 후 수행 결과
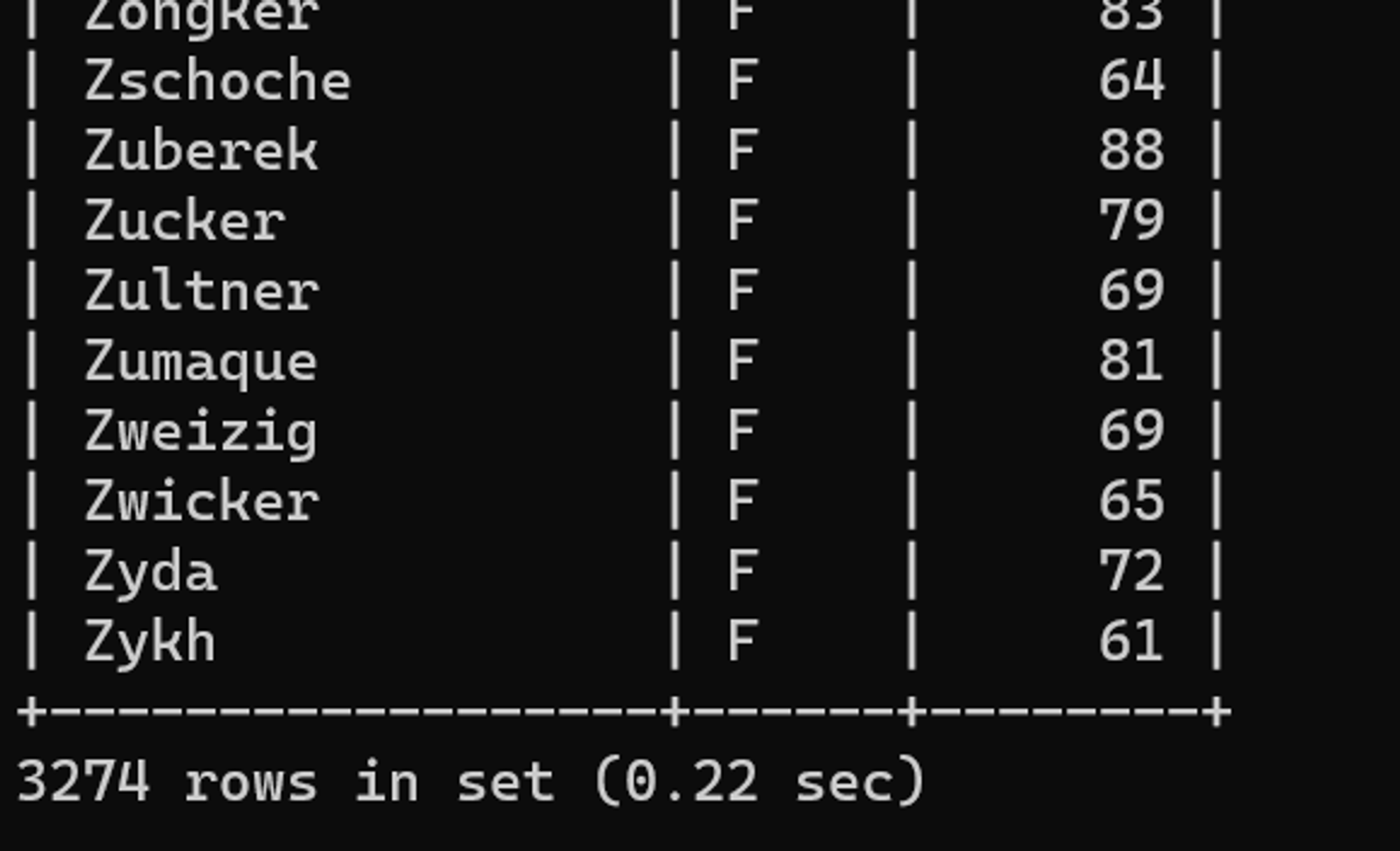
소요시간 0.22초로 개선되었다.
튜닝 후 실행 계획

extra 항목에서 Using temporary 가 사라졌다. 즉, 임시 테이블을 사용하지 않고 작업을 수행한다.
엉뚱한 인덱스를 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT 사원번호
FROM 사원
WHERE 입사일자 LIKE '1989%'
AND 사원번호 > 100000입사일자가 1989년이면서 사원번호가 100,000번을 넘어가는 사원번호 정보를 조회한다.
튜닝 전 수행 결과
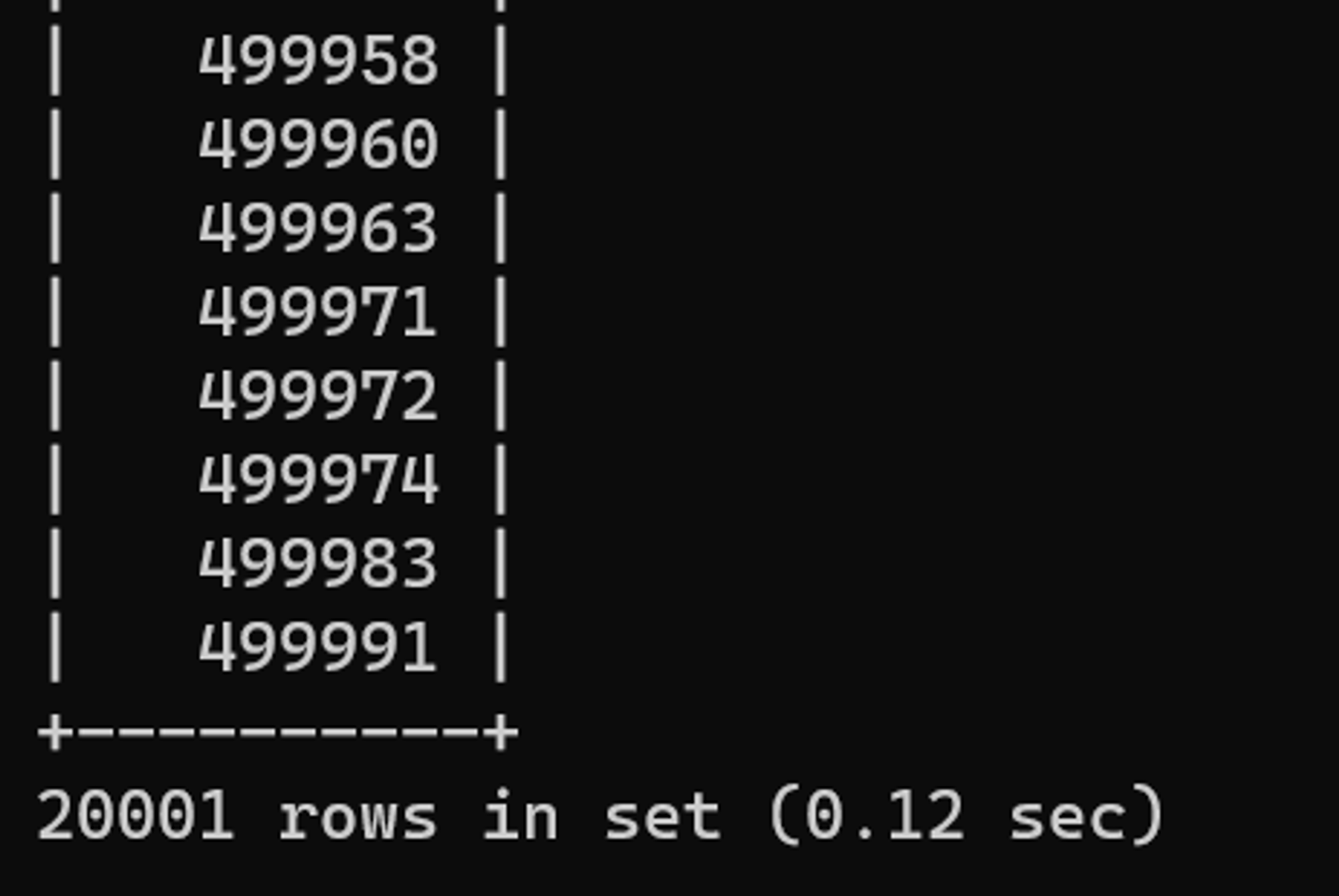
튜닝 전 실행 계획

사원 테이블의 기본 키로 범위 스캔을 수행함을 알 수 있다. 스토리지 엔진에서 기본키를 구성하는 사원번호를 조건으로 데이터를 가져온 뒤, MySQL 엔진에서 남은 필터 조건으로 추출하여 filtered 항목에 11.11% 라는 예측값을 출력한다.
튜닝 수행
굳이 사원번호가 100,000번을 초고하는 데이터가 전체 데이터 건수 대비 약 70%나 차지하는데, 스토리지 엔진에서 데이터를 기본키로 접근하는 것이 효율적인지 고민해봐야 한다.
한편, 입사일자가 1989년인 데이터가 전체의 약 10%이므로, 입사일자 열을 액세스 조건으로 활용하는 것도 검토해볼 수 있다. I_입사일자인덱스 를 강제로 타도록 USE INDEX 힌트를 설정한 뒤 실행 계획을 출력해보자.

I_입사일자 인덱스로 테이블을 스캔하지만, 인덱스 루스 스캔(extra : Using index for skip scan )방식에 의해 인덱스 스킵 오버헤드가 발생할 수 있다. 실행 결과를 확인해보자.
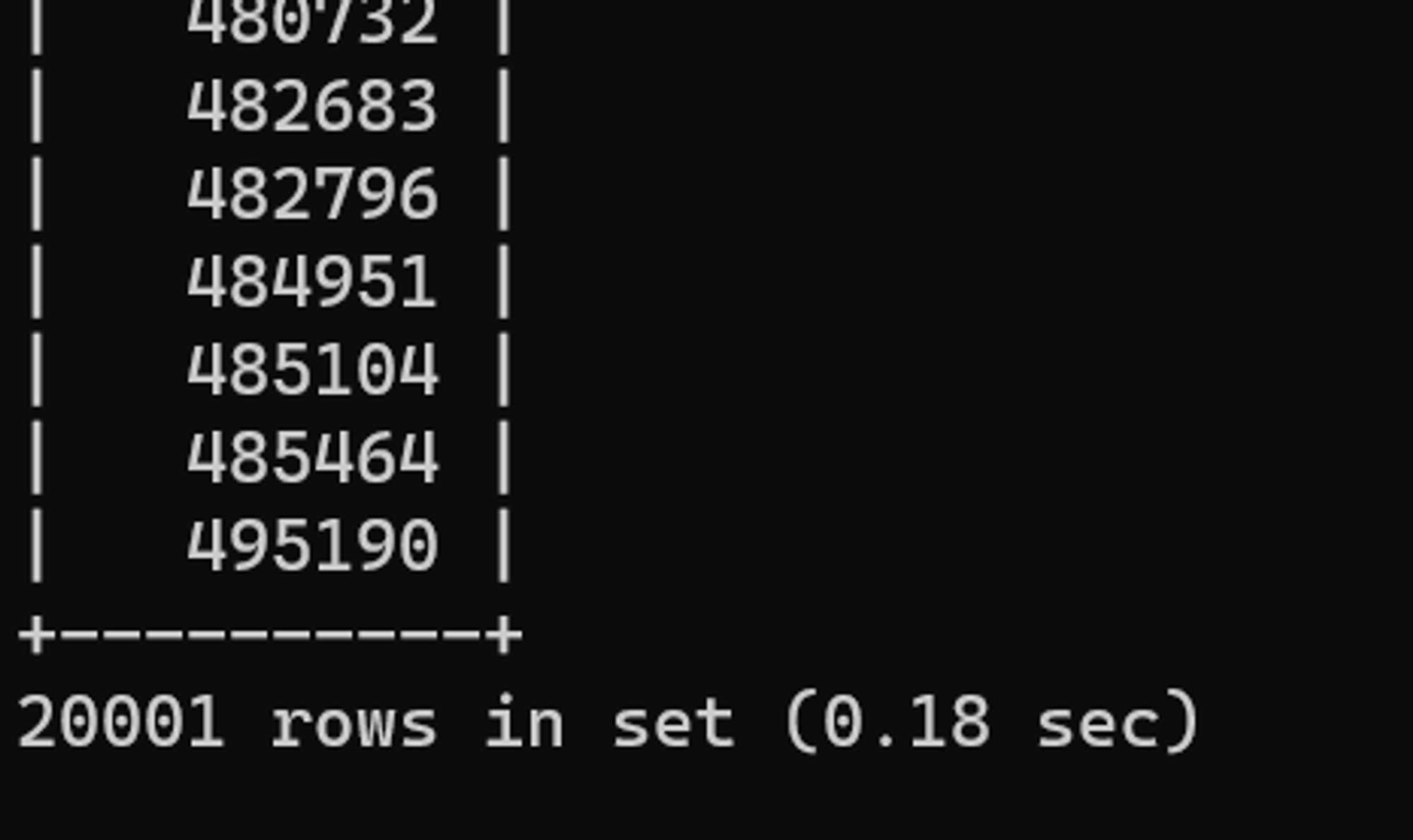
딱히 수행시간이 향상되지 않았다. 입사일자 열의 데이터 유형이 date 타입인데 LIKE 를 활용하는 것이 최선일까?
튜닝 결과
튜닝 후 SQL문
SELECT 사원번호
FROM 사원
WHERE 입사일자 >= '1989-01-01' AND 입사일자 < '1990-01-01'
AND 사원번호 > 100000비교 연산자를 사용토록 조건절을 변경하였다. 이와 같이 구성하면 인덱스를 사용해 데이터 접근 범위를 줄일 수 있다.
튜닝 후 수행 결과
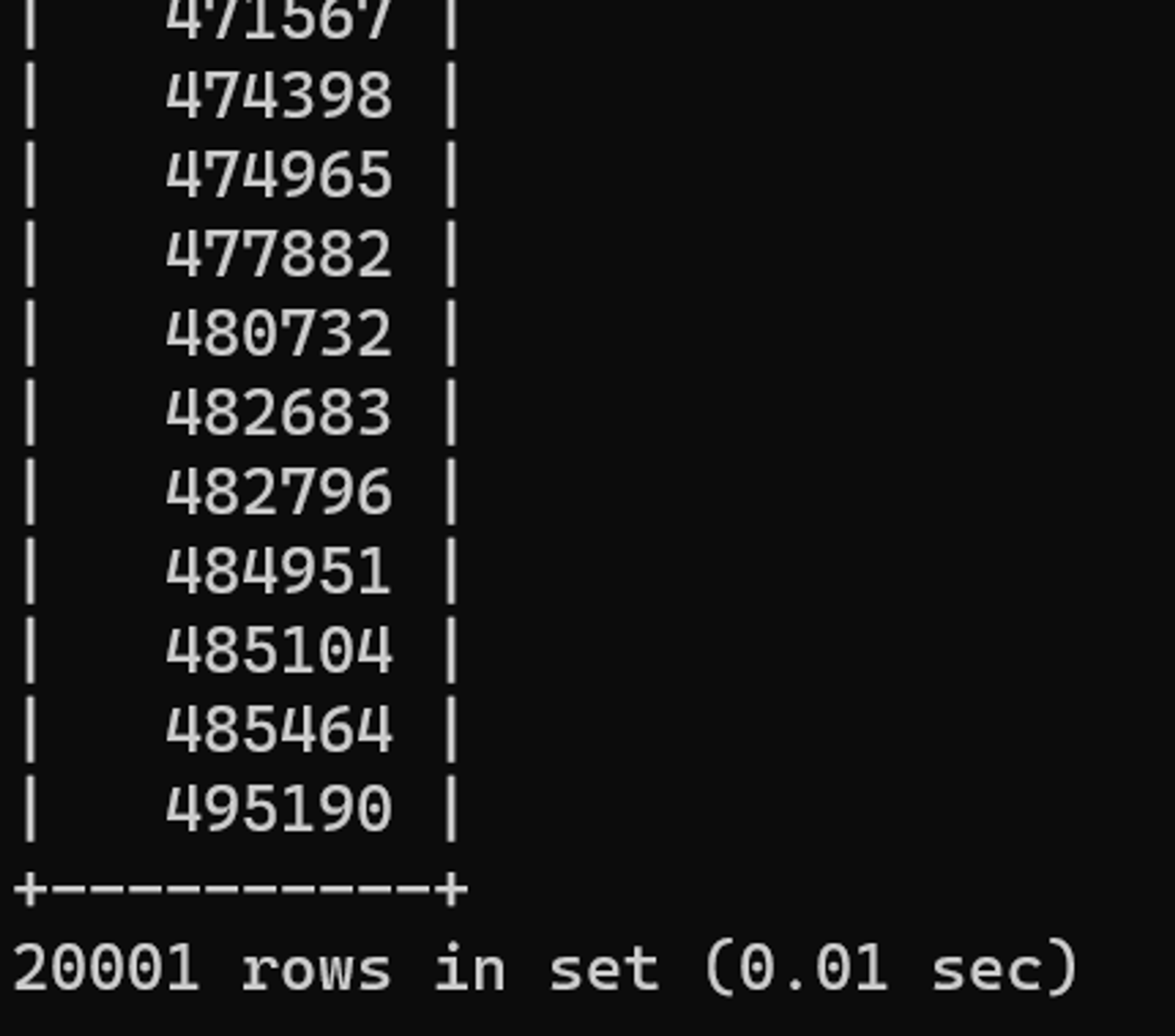
0.01초로 수행시간이 향상되었다.
튜닝 후 실행 계획

I_입사일자 인덱스를 활용하여 범위 스캔을 수행한다. 그리고 테이블에 접근하지 않고 인덱스만을 통해 최종 결과를 도출한다. 이를 커버링 인덱스 스캔(extra : Using index )라고 부른다.
동등 조건으로 인덱스를 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT *
FROM 사원출입기록
WHERE 출입문 = 'B'튜닝 전 수행 결과
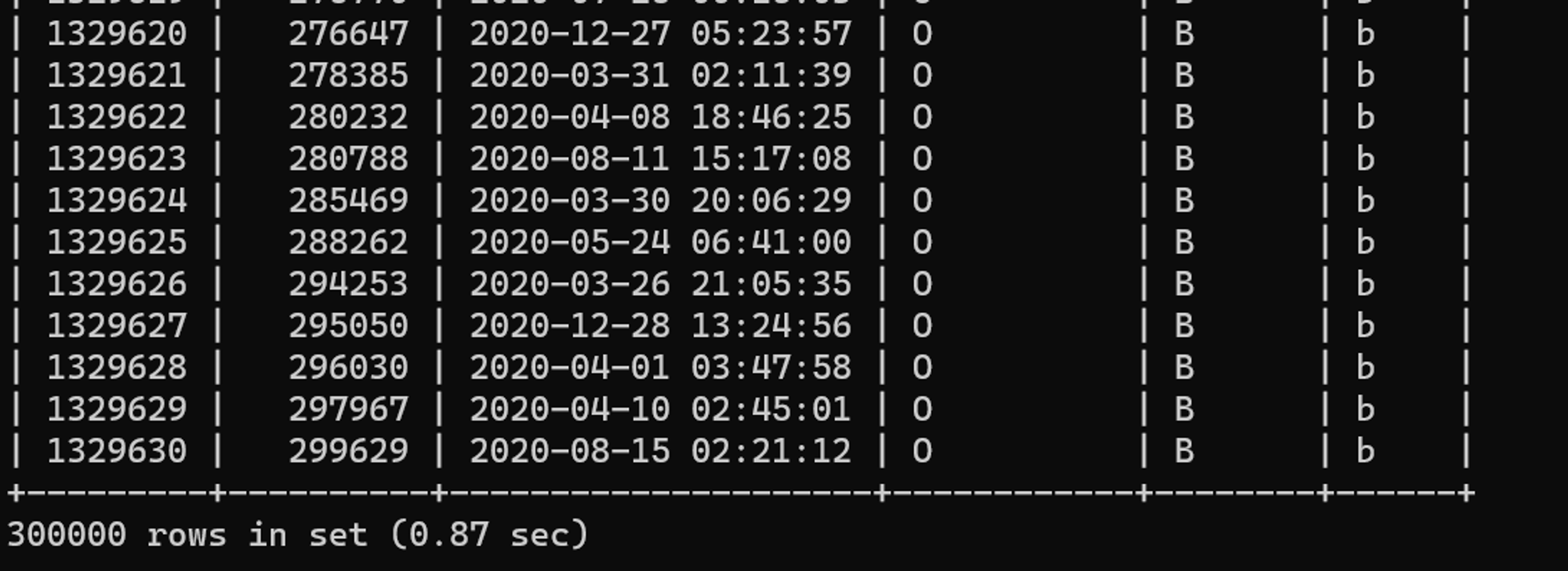
튜닝 전 실행 계획
사원출입기록 테이블은 I_출입문 인덱스를 사용해 데이터를 접근한다. 이때 출입문 B에 대한 명확한 상수화 조건으로 접근 범위를 줄여 ref 항목이 const 로 출력된다.

튜닝 수행
출입문 B는 총 60만 건의 전체 데이터 중 30만 건을 차지하고 있다. 실행 계획에 따르면 I_출입문 인덱스로 인덱스 스캔을 수행한다. 이는 인덱스에 접근한 뒤 테이블에 랜덤 액세스하는 방식이지만, 전체 데이터의 약 50%를 조회하고자 인덱스를 활용하는 게 과연 효율적인지 고민해봐야 한다.
튜닝 결과
튜닝 후 SQL문
SELECT *
FROM 사원출입기록 IGNORE INDEX(I_출입문)
WHERE 출입문 = 'B'대량 데이터를 인덱스 스캔으로 조회하는 쿼리에 대해 내부 실행 인덱스를 무시할 수 있도록 IGNORE INDEX 라는 힌트를 사용할 수 있다.
튜닝 후 실행 결과

0.48초로 수행 시간이 개선되었다.
튜닝 후 실행 계획

테이블 풀 스캔 방식으로 쿼리가 실행된다. 이러면 랜덤 액세스가 발생하지 않고 한 번에 다수의 페이지에 접근하는 테이블 풀 스캔 방식으로 수행되어 더 효율적이다.
범위 조건으로 인덱스를 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT 이름, 성
FROM 사원
WHERE 입사일자 BETWEEN STR_TO_DATE('1994-01-01', '%Y-%m-%d')
AND STR_TO_DATE('2000-12-31', '%Y-%m-%d')튜닝 전 수행 결과
튜닝 전 실행 계획

I_입사일자인덱스로 범위 스캔을 수행한다.extra : Using index condition을 통해 스토리지 엔진에서 입사일자의 조건절로 인덱스 스캔을 수행하는 것을 알 수 있다.Using MRR을 통해 랜덤 액세스가 아닌 순차 스캔으로 최적화하여 처리됨을 알 수 있다.
쿼리 튜닝
전체 데이터는 총 300,024건인데, 튜닝 전 SQL의 결과 건수는 48,875건이므로 17%정도의 데이터를 조회한다. 인덱스를 사용하는 것이 효율적인지 고민해봐야 한다. 한편, 입사일자 기준 매번 수 년에 걸친 데이터 조회가 잦다면, 인덱스 스캔으로 랜덤 액세스 부하가 발생하는 것보다는 테이블 풀 스캔을 고정적으로 설정하는 것이 나을 것이다.
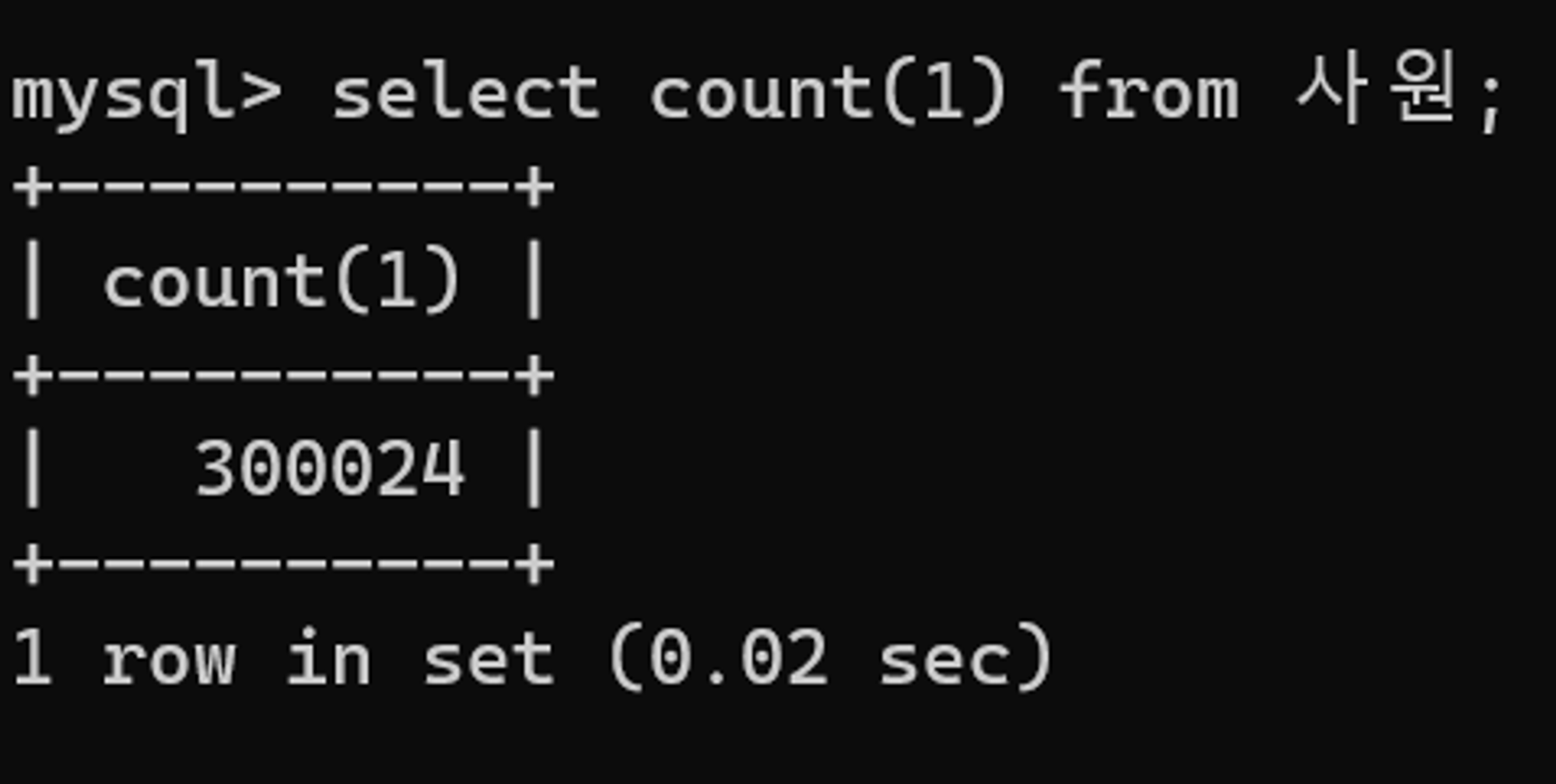
튜닝 결과
튜닝 후 SQL문
SELECT 이름, 성
FROM 사원
WHERE YEAR(입사일자) BETWEEN '1994' AND '2000'입사일자 열로 생성한 인덱스를 사용하지 않게 의도적으로 인덱스 열을 변형한 쿼리이다.
튜닝 후 수행 결과
0.14초로 수행 시간이 개선되었다.
튜닝 후 실행 계획

테이블 풀 스캔으로 인덱스 없이 다수 페이지에 접근하여 더 효율적으로 SQL문이 수행된다.
