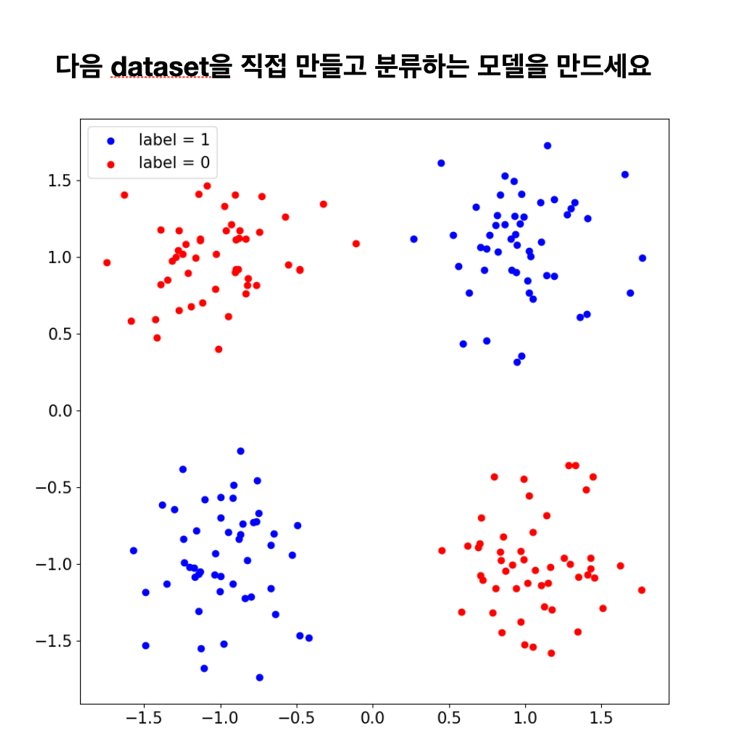
<수업 내용>
make_moons 데이터 학습
from sklearn.datasets import make_moons
import torch
from torch.utils.data import TensorDataset, DataLoader
import torch.nn as nn
from torch.optim import SGD
import matplotlib.pyplot as plt
## 뉴런 모델 만들기(linear, sigmoid)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(in_features=2, out_features=3)
self.sigmoid1 = nn.Sigmoid()
self.linear2 = nn.Linear(in_features=3, out_features=1)
self.sigmoid2 = nn.Sigmoid()
# self.linear3 = nn.Linear(in_features=2, out_features=1)
# self.sigmoid3 = nn.Sigmoid()
def forward(self, x):
x = self.linear1(x)
x = self.sigmoid1(x)
x = self.linear2(x)
x = self.sigmoid2(x)
# x = self.linear3(x)
# x = self.sigmoid3(x)
k = x.view(-1)
return k
## 모델 학습 전 코드 홤수화
def get_device():
if torch.cuda.is_available(): DVICE = 'cuda'
elif torch.backends.mps.is_available() : DEVICE = 'mps'
else : DEVICE = 'cpu'
return DEVICE
def get_dataset(N_SAMPLES, BATCH_SIZE):
X, y = make_moons(n_samples = N_SAMPLES, noise = 0.2)
dataset = TensorDataset(torch.FloatTensor(X), torch.FloatTensor(y))
dataloader = DataLoader(dataset, batch_size = BATCH_SIZE)
return dataloader
def train(dataloader, N_SAMPLES, model, loss_function, optimizer, DEVICE):
epoch_loss = 0.
n_corrects = 0
for X, y in dataloader:
X, y =X.to(DEVICE), y.to(DEVICE)
pred = model.forward(X)
loss = loss_function(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss+=loss.item()*len(X)
pred =(pred > 0.5).type(torch.float)
n_corrects+=(pred ==y).sum().item()
epoch_loss /= N_SAMPLES
epoch_acc = n_corrects/ N_SAMPLES
return epoch_loss, epoch_acc
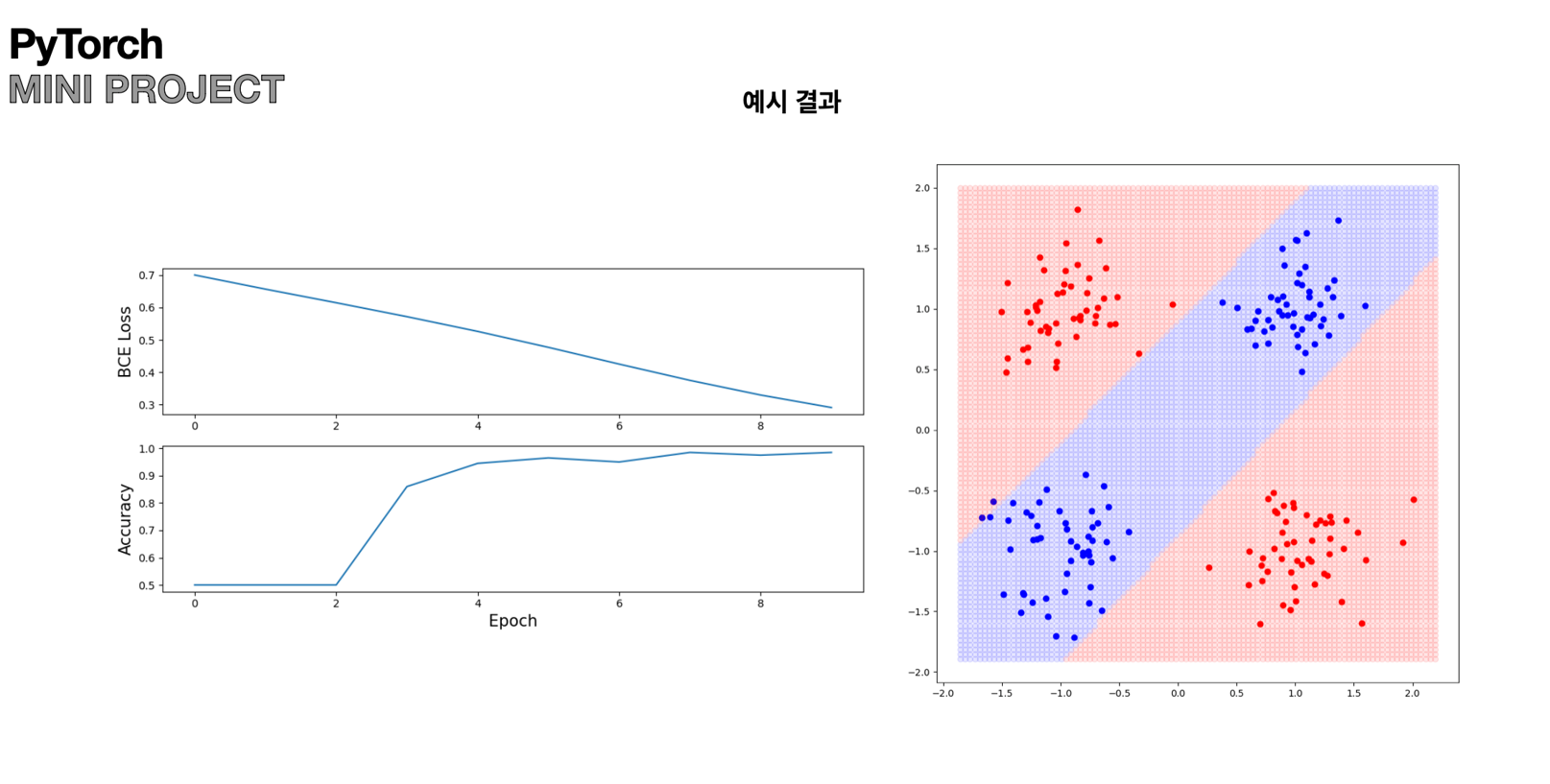
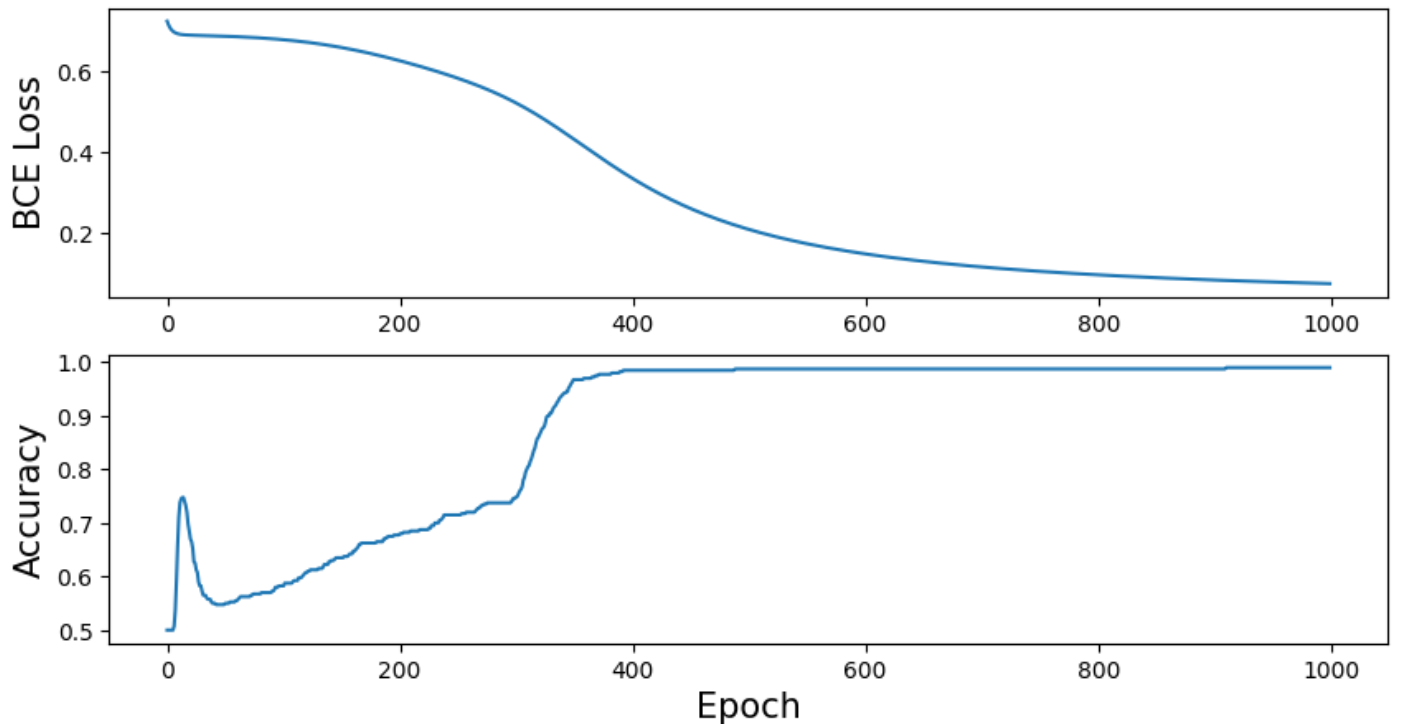
def vis_losses_accs(losses, accs):
fig, ax= plt.subplots(2,1,figsize=(10,5))
ax[0].plot(losses)
ax[1].plot(accs)
ax[0].tick_params(labelsize=10)
ax[1].tick_params(labelsize=10)
ax[1].set_xlabel("Epoch", fontsize=15)
ax[0].set_ylabel("BCE Loss", fontsize = 15)
ax[1].set_ylabel("Accuracy", fontsize = 15)
## 모델 학습 코드
N_SAMPLES =300
BATCH_SIZE = 10
EPOCHS = 1000
LR = 0.01
DEVICE = get_device()
data_loader = get_dataset(N_SAMPLES, BATCH_SIZE)
model = Model().to(DEVICE)
loss_function = nn.BCELoss()
optimizer = SGD(model.parameters(), lr=LR)
losses, accs = [], []
for epoch in range(EPOCHS):
epoch_loss, epoch_acc = train(data_loader, N_SAMPLES, model, loss_function, optimizer, DEVICE)
losses.append(epoch_loss)
accs.append(epoch_acc)
# print(f'Epoch: {epoch + 1}')
# print(f'Loss: {epoch_loss: .4f}-ACC:{epoch_acc:.4f}\n')
vis_losses_accs(losses, accs) 실습
from sklearn.datasets import make_moons
import torch
from torch.utils.data import TensorDataset, DataLoader
import torch.nn as nn
from torch.optim import SGD
import matplotlib.pyplot as plt
def get_device():
if torch.cuda.is_available(): DEVICE = 'cuda'
elif torch.backends.mps.is_available() : DEVICE = 'mps'
else : DEVICE = 'cpu'
return DEVICE
def get_dataset(N_SAMPLES, BATCH_SIZE):
X, y = make_blobs(n_samples= N_SAMPLES, centers =[[1,-1],[1,1],[-1,-1],[-1,1]] , n_features= 2, cluster_std = 0.3)
y[y==2]=1
y[y==3]=0
dataset = TensorDataset(torch.FloatTensor(X), torch.FloatTensor(y))
dataloader = DataLoader(dataset, batch_size = BATCH_SIZE)
return dataloader, X, y
def train(dataloader, N_SAMPLES, model, loss_function, optimizer, DEVICE):
epoch_loss = 0.
n_corrects = 0
for X, y in dataloader:
X, y =X.to(DEVICE), y.to(DEVICE)
pred = model.forward(X)
loss = loss_function(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss+=loss.item()*len(X)
pred =(pred > 0.5).type(torch.float)
n_corrects+=(pred ==y).sum().item()
epoch_loss /= N_SAMPLES
epoch_acc = n_corrects/ N_SAMPLES
return epoch_loss, epoch_acc
def vis_losses_accs(losses, accs):
fig, ax= plt.subplots(2,1,figsize=(10,5))
ax[0].plot(losses)
ax[1].plot(accs)
ax[0].tick_params(labelsize=10)
ax[1].tick_params(labelsize=10)
ax[1].set_xlabel("Epoch", fontsize=15)
ax[0].set_ylabel("BCE Loss", fontsize = 15)
ax[1].set_ylabel("Accuracy", fontsize = 15)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(in_features=2, out_features=2)
self.sigmoid1 = nn.Sigmoid()
self.linear2 = nn.Linear(in_features=2, out_features=1)
self.sigmoid2 = nn.Sigmoid()
def forward(self, x):
x = self.linear1(x)
x = self.sigmoid1(x)
x = self.linear2(x)
x = self.sigmoid2(x)
k = x.view(-1)
return k
N_SAMPLES =400
BATCH_SIZE = 10
EPOCHS = 1000
LR = 0.01
DEVICE = get_device()
data_loader, X, y = get_dataset(N_SAMPLES, BATCH_SIZE)
model = Model().to(DEVICE)
loss_function = nn.BCELoss()
optimizer = SGD(model.parameters(), lr=LR)
losses, accs = [], []
for epoch in range(EPOCHS):
epoch_loss, epoch_acc = train(data_loader, N_SAMPLES, model, loss_function, optimizer, DEVICE)
losses.append(epoch_loss)
accs.append(epoch_acc)
# print(f'Epoch: {epoch + 1}')
# print(f'Loss: {epoch_loss: .4f}-ACC:{epoch_acc:.4f}\n')
vis_losses_accs(losses, accs)
import numpy as np
from sklearn.datasets import make_blobs
print(X.shape)
print(y.shape)
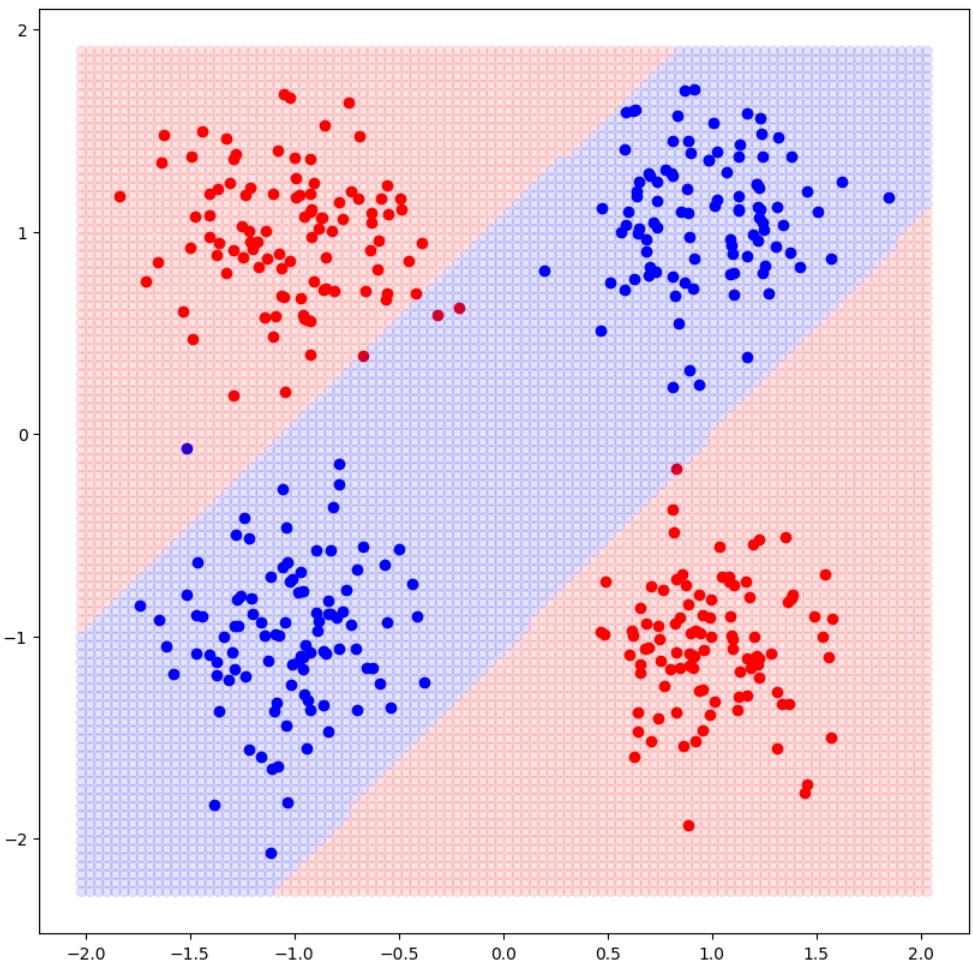
fig, ax =plt.subplots(figsize = (10,10))
X_pos, X_neg = X[y==0], X[y==1]
ax.scatter(X_pos[:,0], X_pos[:,1], color='red')
ax.scatter(X_neg[:,0], X_neg[:,1], color='blue')
x_lim=ax.get_xlim()
y_lim=ax.get_ylim()
X1=np.linspace(x_lim[0],x_lim[1],100)
Y1=np.linspace(y_lim[0],y_lim[1],100)
X_,Y_=np.meshgrid(X1,Y1)
grid_ = np.hstack([X_.reshape(-1, 1), Y_.reshape(-1, 1)])
grid_= torch.FloatTensor(grid_).to(DEVICE)
red_list = []
blue_list = []
pred = model.forward(grid_)
pred =(pred > 0.5).type(torch.float).to("cpu").numpy()
print(pred)
grid_ = grid_.to("cpu")
print(np.unique(pred, return_counts=True))
print(grid_)
color_list =['red', 'blue']
ax.scatter(grid_[:,0],grid_[:,1], c=[color_list[int(p)] for p in pred], alpha =0.1)