<수업 내용>
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
import torch
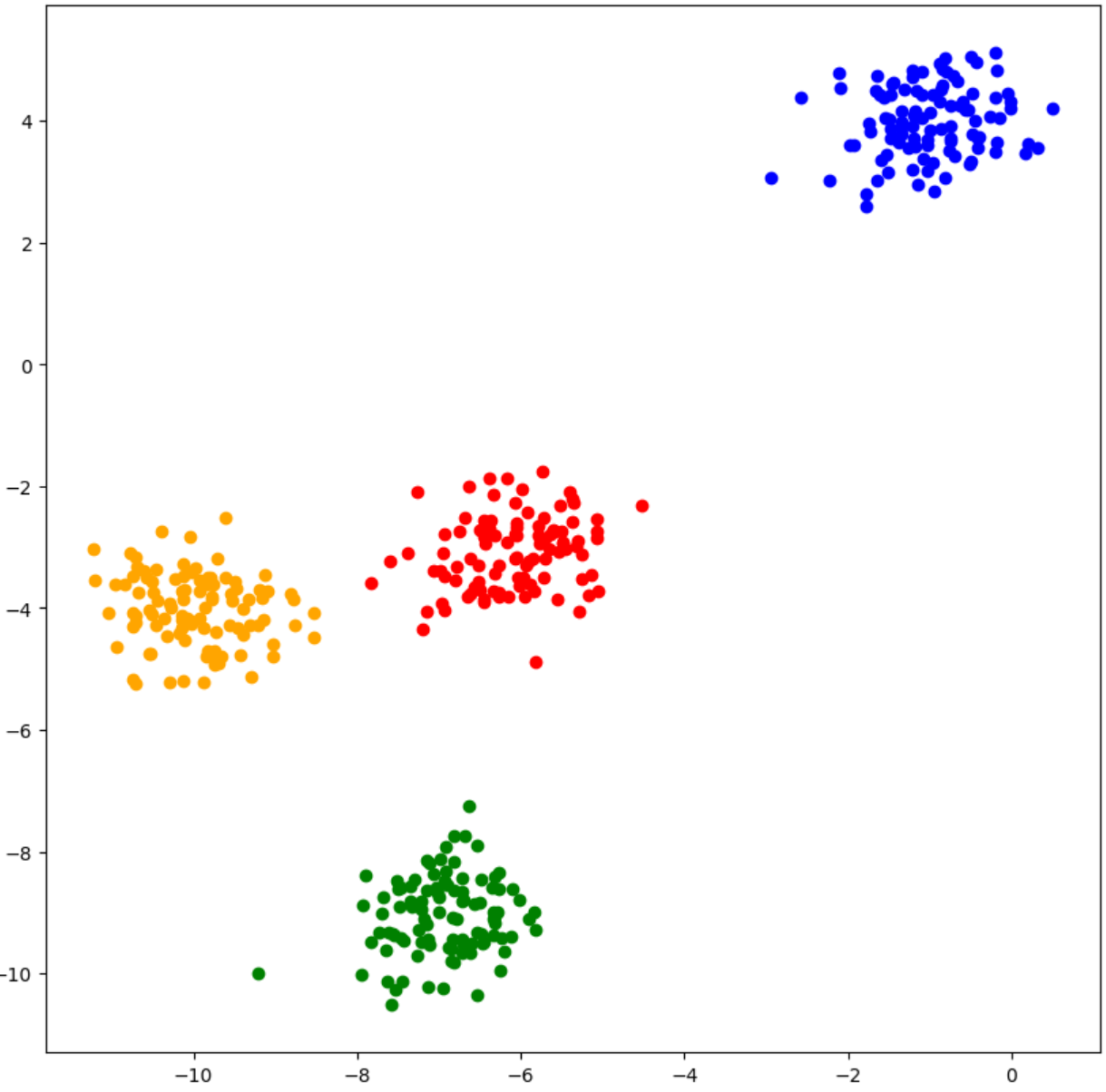
X, y = make_blobs(n_samples= 400, n_features= 2, centers =[[-10,-4],[-7,-9], [-6,-3], [-1, 4]], cluster_std = 0.6)
fig, ax = plt.subplots(figsize=(10,10))
print(y.shape)
X1, X2, X3, X4 = X[y==0], X[y==1], X[y==2], X[y==3]
ax.scatter(X1[:,0], X1[:,1], color ='orange')
ax.scatter(X2[:,0], X2[:,1], color ='green')
ax.scatter(X3[:,0], X3[:,1], color ='red')
ax.scatter(X4[:,0], X4[:,1], color ='blue')
import torch.nn as nn
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.fc1 = nn.Linear(in_features = 2, out_features= 16)
self.fc1_act = nn.ReLU()
self.fc2 = nn.Linear(in_features = 16, out_features= 32)
self.fc2_act = nn.ReLU()
self.fc3 = nn.Linear(in_features = 32, out_features= 4)
def forward(self, x):
x = self.fc1(x)
x = self.fc1_act(x)
x = self.fc2(x)
x = self.fc2_act(x)
x = self.fc3(x)
return x
model = Classifier()
loss_function = nn.CrossEntropyLoss()
from torch.optim import SGD
LR = 0.1
if torch.cuda.is_available(): DEVICE = 'cuda'
elif torch.backends.mps.is_available(): DEVICE = 'mps'
else: DEVICE = 'cpu'
optimizer = SGD(model.parameters(), lr =LR)
from torch.utils.data import TensorDataset, DataLoader
from tqdm import tqdm
import time
N_SAMPLES = 400
X, y = make_blobs(n_samples= N_SAMPLES, n_features= 2, centers =[[-10,-4],[-7,-9], [-6,-3], [-1, 4]], cluster_std = 0.6)
dataset = TensorDataset(torch.FloatTensor(X), torch.LongTensor(y))
BATCH_SIZE = 10
dataloader = DataLoader(dataset, batch_size = BATCH_SIZE)
EPOCHS = 100
total_loss= []
total_acc = []
with tqdm(total=EPOCHS, desc='Processing') as pbar:
for epochs in range(EPOCHS):
epoch_loss = 0.
n_corrects = 0
for X_, y_ in dataloader:
X_, y_ = X_.to(DEVICE), y_.to(DEVICE)
pred = model.forward(X_)
loss = loss_function(pred, y_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss +=loss.item()*len(X_)
max_values, max_indices = torch.max(pred, dim=1)
n_corrects += (max_indices == y_).sum().item()
epoch_loss /= N_SAMPLES
total_loss.append(epoch_loss)
epoch_acc = n_corrects/ N_SAMPLES
total_acc.append(epoch_acc)
pbar.update(1)
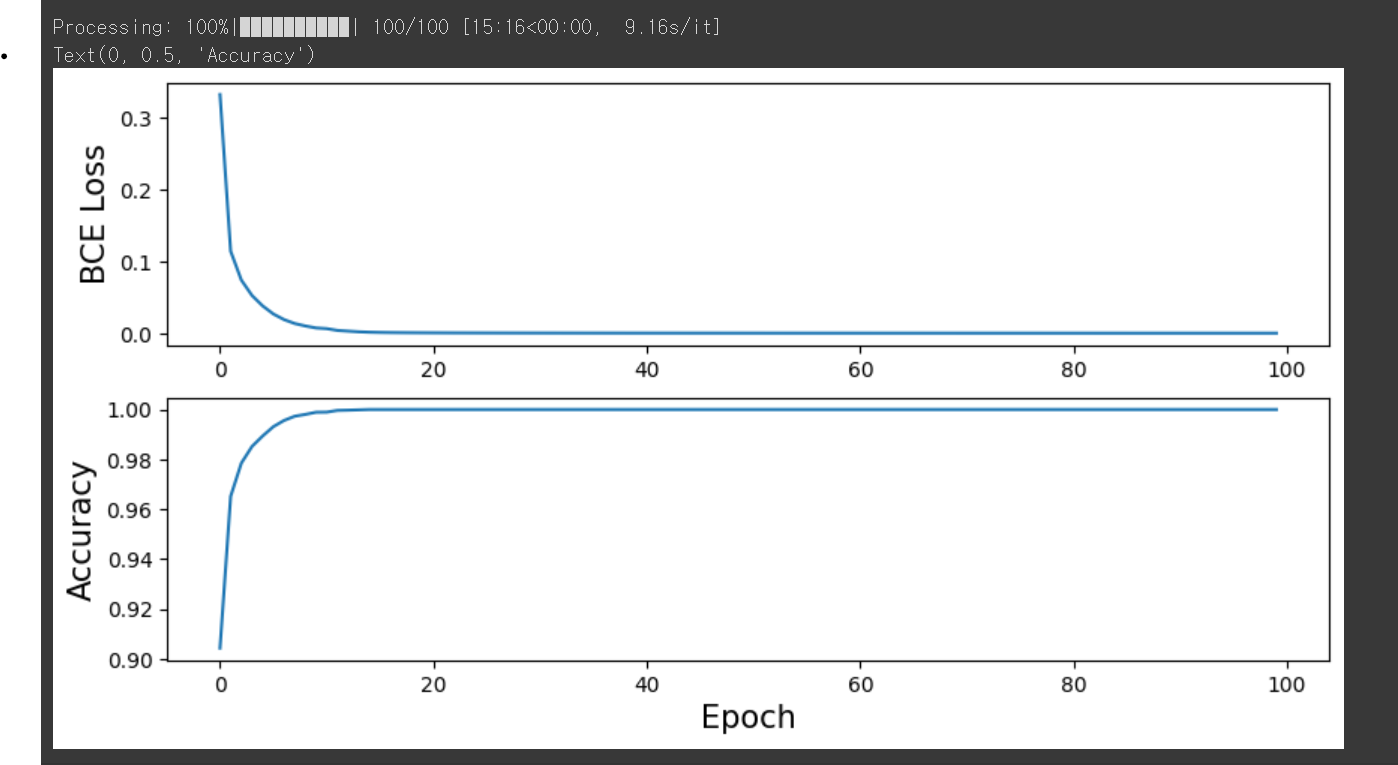
fig, ax = plt.subplots(2,1, figsize=(10,5))
ax[0].plot(total_loss)
ax[1].plot(total_acc)
ax[0].tick_params(labelsize=10)
ax[1].tick_params(labelsize=10)
ax[1].set_xlabel("Epoch", fontsize=15)
ax[0].set_ylabel("BCE Loss", fontsize = 15)
ax[1].set_ylabel("Accuracy", fontsize = 15)
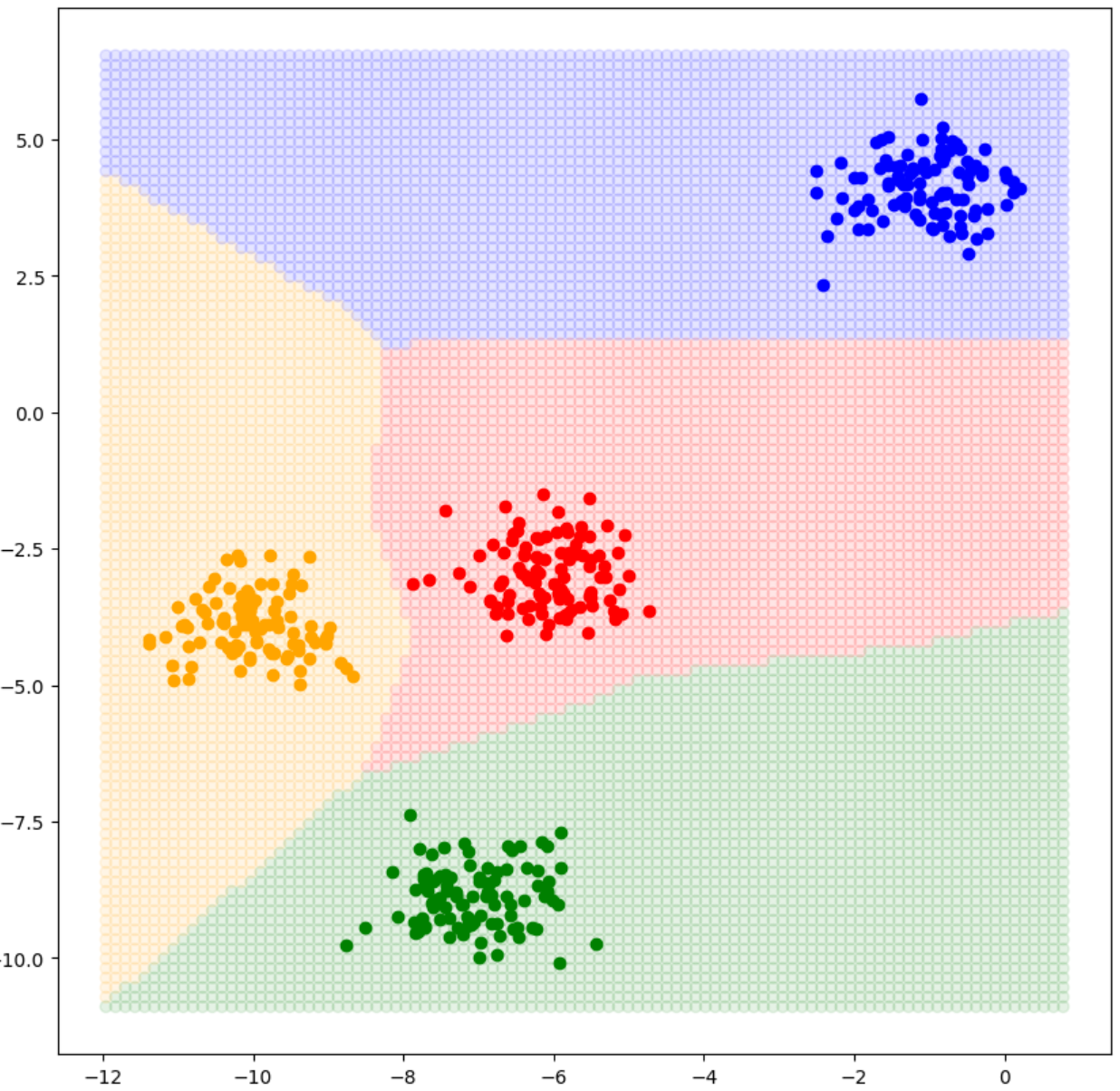
fig, ax = plt.subplots(figsize=(10,10))
X1, X2, X3, X4 = X[y==0], X[y==1], X[y==2], X[y==3]
ax.scatter(X1[:,0], X1[:,1], color ='orange')
ax.scatter(X2[:,0], X2[:,1], color ='green')
ax.scatter(X3[:,0], X3[:,1], color ='red')
ax.scatter(X4[:,0], X4[:,1], color ='blue')
x_lim=ax.get_xlim()
y_lim=ax.get_ylim()
X1=np.linspace(x_lim[0],x_lim[1],100)
Y1=np.linspace(y_lim[0],y_lim[1],100)
X_,Y_=np.meshgrid(X1,Y1)
grid_ = np.hstack([X_.reshape(-1, 1), Y_.reshape(-1, 1)])
grid_= torch.FloatTensor(grid_).to(DEVICE)
red_list = []
blue_list = []
pred = model.forward(grid_)
max_values, max_indices = torch.max(pred, dim=1)
max_indices = max_indices.to('cpu').numpy()
grid_ = grid_.to("cpu")
color_list =['orange','green','red', 'blue']
ax.scatter(grid_[:,0],grid_[:,1], c=[color_list[i] for i in max_indices], alpha =0.1)
import torch
import matplotlib.pyplot as plt
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
import numpy as np
import torch
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
dataset = MNIST(root='data', train=True, download=True, transform=None)
fig, ax = plt.subplots(2, 5, figsize=(20, 10))
for i in range(5):
img, label = dataset[i]
ax[0][i].imshow(img, cmap='gray')
ax[0][i].set_title(f"Label: {label}")
ax[0][i].axis('off')
for i in range(5, 10):
img, label = dataset[i]
ax[1][i-5].imshow(img, cmap='gray')
ax[1][i-5].set_title(f"Label: {label}")
ax[1][i-5].axis('off')
plt.tight_layout()
print(dataset[0])

import matplotlib.pyplot as plt
import numpy as np
import torch
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
from tqdm import tqdm
import time
from torch.optim import SGD
BATCH_SIZE = 32
dataset = MNIST(root='data', train = True, download =True, transform=ToTensor())
dataloader = DataLoader(dataset, batch_size= BATCH_SIZE)
unique_labels = set()
for batch_X, batch_y in dataloader:
unique_labels.update(batch_y.numpy().tolist())
print("유니크한 레이블 값:", unique_labels)
len(dataloader.dataset)
>>
유니크한 레이블 값: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
60000
-------------------------------------------------------------------------
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.fc1 = nn.Linear(in_features = 784, out_features= 392)
self.fc1_act = nn.ReLU()
self.fc2 = nn.Linear(in_features = 392, out_features= 196)
self.fc2_act = nn.ReLU()
self.fc3 = nn.Linear(in_features = 196, out_features= 10)
def forward(self, x):
x = self.fc1(x)
x = self.fc1_act(x)
x = self.fc2(x)
x = self.fc2_act(x)
x = self.fc3(x)
return x
LR = 0.1
if torch.cuda.is_available(): DEVICE = 'cuda'
elif torch.backends.mps.is_available(): DEVICE = 'mps'
else: DEVICE = 'cpu'
model = Classifier().to(DEVICE)
loss_function = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr =LR)
EPOCHS = 10
total_loss= []
total_acc = []
with tqdm(total=EPOCHS, desc='Processing') as pbar:
for epochs in range(EPOCHS):
epoch_loss = 0.
n_corrects = 0
for X_, y_ in dataloader:
X_, y_ = X_.view(-1,28*28).to(DEVICE), y_.to(DEVICE)
pred = model.forward(X_)
loss = loss_function(pred, y_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss +=loss.item()*len(X_)
max_values, max_indices = torch.max(pred, dim=1)
n_corrects += (max_indices == y_).sum().item()
epoch_loss /= len(dataloader.dataset)
total_loss.append(epoch_loss)
epoch_acc = n_corrects/ len(dataloader.dataset)
total_acc.append(epoch_acc)
pbar.update(1)
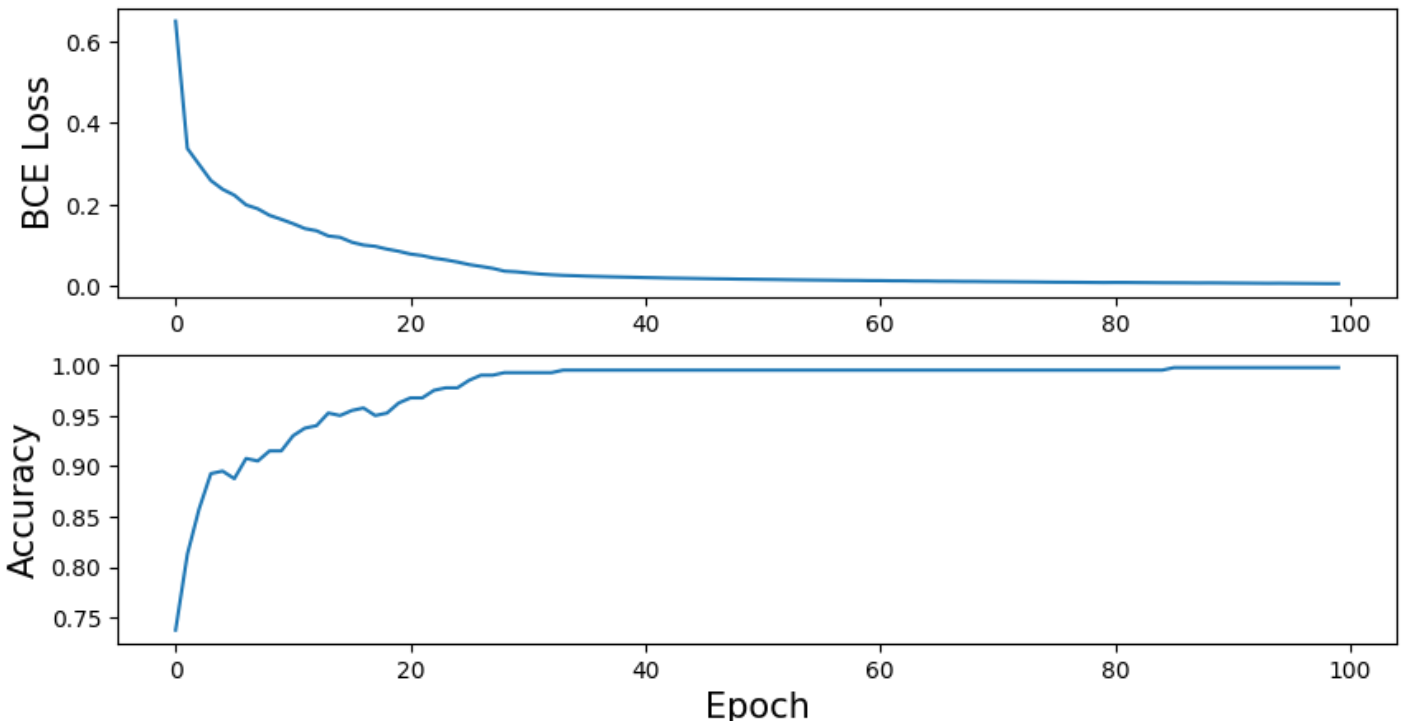
fig, ax = plt.subplots(2,1, figsize=(10,5))
ax[0].plot(total_loss)
ax[1].plot(total_acc)
ax[0].tick_params(labelsize=10)
ax[1].tick_params(labelsize=10)
ax[1].set_xlabel("Epoch", fontsize=15)
ax[0].set_ylabel("BCE Loss", fontsize = 15)
ax[1].set_ylabel("Accuracy", fontsize = 15)