<수업 내용>
데이터 분석 프로세스
-
문제정의 > 데이터 수집 > 데이터 전처리 > 탐색적 데이터 분석(EDA) > 데이터 모델링 및 알고리즘 선택 > 모델 학습 및 평가 > 결과 해석 > 의사 결정 및 개선
- 데이터 수집 방법 : 데이터 베이스, 공공 데이터, Open API, RPA, 웹 스크래핑
파이썬 라이브러리
- numpy : 수학적연산, 다차원 배열 및 행렬 연산에 유용. 딥러닝에 활용도가 높다
- pandas : 데이블 형태의 데이터를 조작하고 분석하기 위한 라이브러리. 머신러닝에 활용도가 높다
- matplotlib : 그래프 및 차트를 그리는 라이브러리.
- seaborn : matplotlib기반의 통계용 그래프 라이브러리. 좀더 간편하고 다양한 그래프를 그릴 수 있다
- plotly: 인터랙티브한 그래프를 그리기 위한 라이브러리. 웹사이트나 대쉬보드에서 사용하기 적합합니다.
- pytorch : 페이스북에서 만든 오픈소스 딥러닝 라이브러리.
- tensorflow : 구글에서 만든 오픈소스 딥러닝 라이브러리.
- scikit-learn(sklearn) : 머신러닝 라이브러리. 분류, 회귀, 클러스터링 등 다양한 알고리즘 제공
데이터 분석
- pandas : 데이터 핸들링
- matplotlib, seaborn, plotly : 데이터 시각화
머신러닝
- pandas, numpy : 데이터 핸들링
- matplotlib, seaborn, plotly : 데이터 시각화
- scikit-learn : 모델링
딥러닝
- numpy : 데이터 핸들링
- matplotlib, seaborn, plotly : 데이터 시각화
- tensorflow, pytorch
Pandas
시리즈 :1차원 데이터 배열로서, 모든 데이터 유형을 포함할 수 있다.데이터프레임에서 하나의 열을 추출하면 시리즈가 반환된다. 인덱스(각 항목의 고유한 이름)와 값(각 항목의 데이터)으로 구성된다.
import pandas as pd
# 시리즈 생성
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
print(s)EX)
import pandas as pd
prices =[1000, 1010, 1020]
Series1=pd.Series(prices)
Series1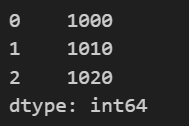
# 인덱스 설정
dates=pd.date_range('20230101', periods=3)
Series2=pd.Series(prices, index= dates)
Series2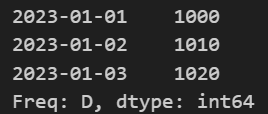
# 값 추가
Series2['2023-01-04']=1030
Series2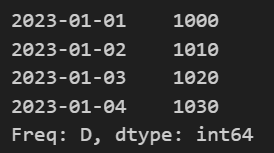
Series2[1:3] #슬라이싱으로 값 불러오기
Series2[2] #인덱싱으로 값 불러오기데이터프레임 : 행과 열이 있는 테이블 형태의 데이터 구조. 시리즈들의 집합
import pandas as pd
# 데이터프레임 생성
data = {'이름': ['A', 'B', 'C', 'D'],
'나이': [20, 30, 25, 28],
'성별': ['여', '남', '여', '남']}
df = pd.DataFrame(data)
print(df)EX)
prices = {
'SK 텔레콤' : [44000,44500,45000],
'삼성전자' : [70100, 70200, 70300],
'LG 전자' : [85000,85500,86000]
}
df1=pd.DataFrame(prices)
df1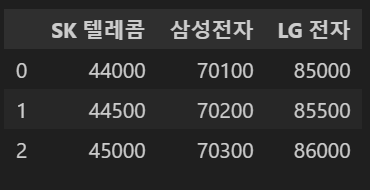
#인덱싱 추가
df2=pd.DataFrame(prices,index=dates)
df2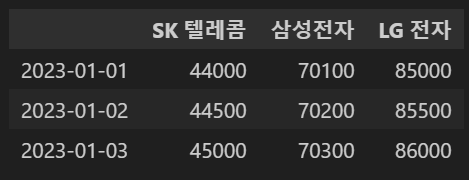
- 데이터 선택
- loc : index, column 으로 데이터 가져온다
- iloc :데이터 순서로 데이터 가져온다 ex)
df2.iloc[:,0]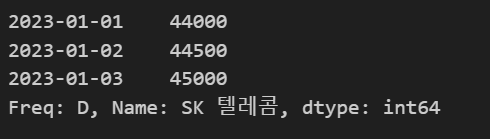
실습
Q1. 2023년 1월 2일 ~ 2023 1월 3일 까지의 '삼성전자', 'LG전자' 데이터를 가져와주세요.
df2.iloc[1:3,1:3]
df2.loc[['2023-01-02','2023-01-03']][['삼성전자','LG 전자']]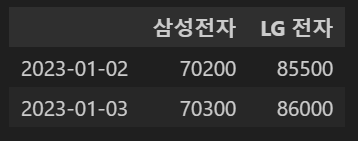
Q2. 데이터 70200원 가져오기 (iloc, loc 각각 활용)
df2.iloc[1,1]
df2.loc['2023-01-02','삼성전자']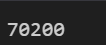
- loc는 인덱스, 열의 정확한 명칭으로 데이터를 불러올 수 있고, iloc는 정수로 데이터를 불러올 수 있다
- 데이터 확장
- concat : 그냥 가져다 붙이는 것
- merge : 공통된 칼럼이나 인덱스가 있는 경우
s1=pd.Series([500000,500500,501000], index=dates, name='LG 화학')
concat_df2=pd.concat([df2,s1],axis=1)
concat_df2
* axis=1은 열 방향으로 붙이는 것, axis=0은 행 방향으로 붙이는 것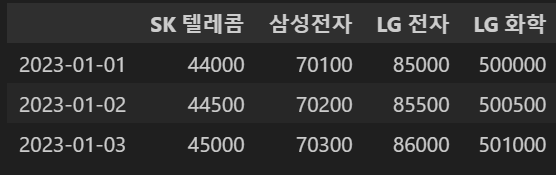
#데이터 프레임의 열을 시리즈로 불러와서 연산 후 열로 추가
concat_df2['LG 화학_add_500']=concat_df2['LG 화학']+500
concat_df2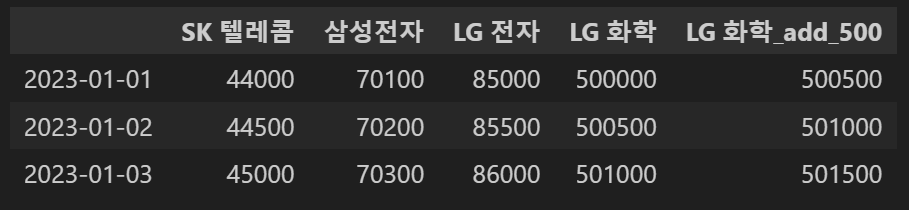
# 행 추가하기
concat_df2.loc['2023-01-06',:]=[44000,7100,85000,45500,505000]
concat_df2
# 행에 연산을 하고 추가하기
concat_df2.loc['2023-01-05',:]=concat_df2.loc['2023-01-06',:]-100
concat_df2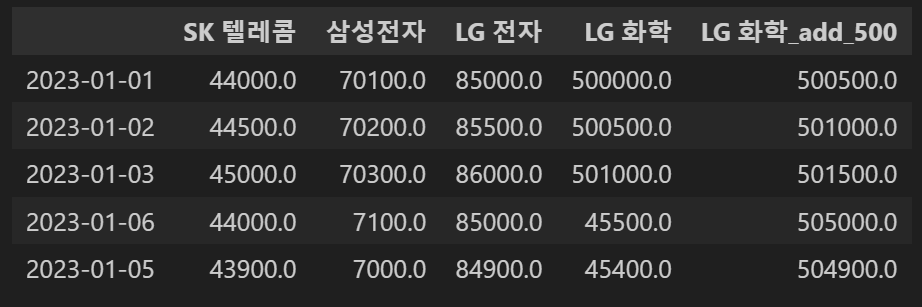
# 인덱스 정렬하기
concat_df2.sort_index()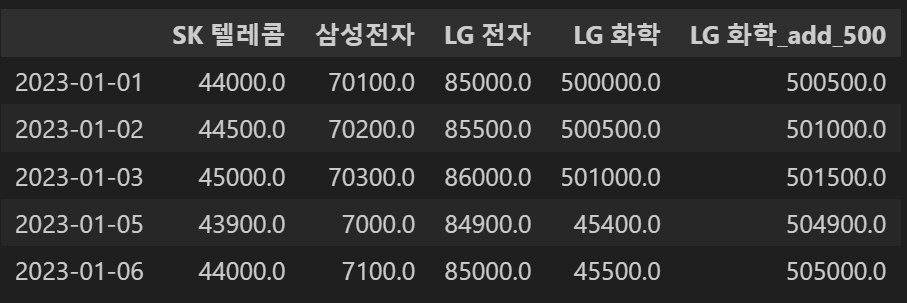
concat_df2.sort_values(by='삼성전자')
concat_df2.sort_values(by='삼성전자',ascending=False) #내림차순* 오름차순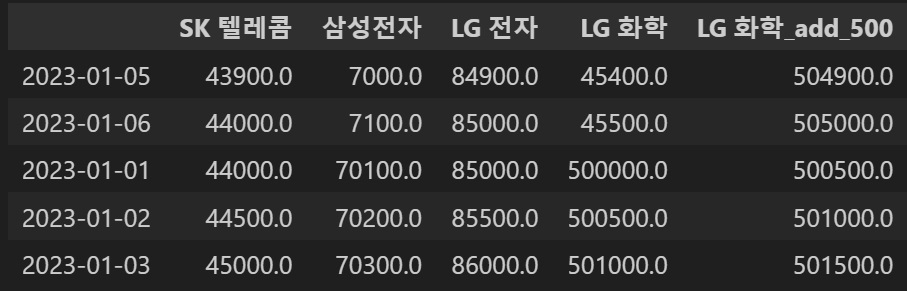
* 내림차순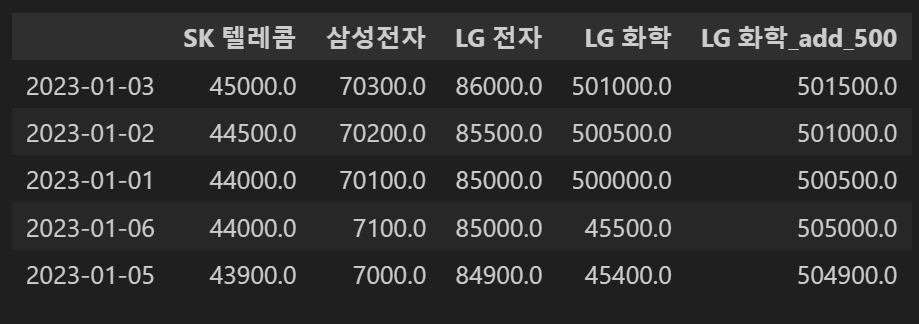
-데이터 삭제
concat_df2.drop('2023-01-03') #다른 변수에 저장을 해야 데이터 삭제가 반영된다
concat_df2.drop('2023-01-03',inplace=True)
concat_df2 #inplace를 넣으면 변수 지정을 하지 않아도 된다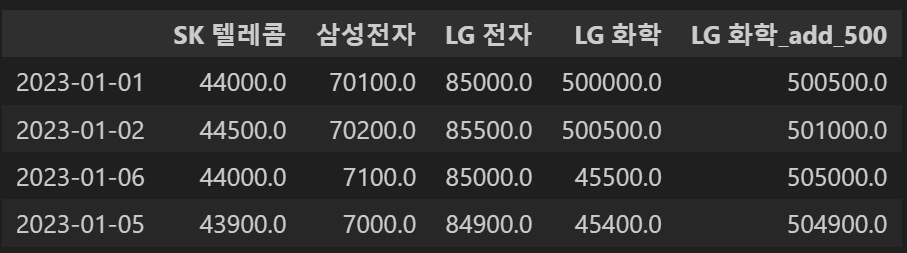
concat_df2.drop('LG 화학_add_500', axis=1, inplace=True)
# 행삭제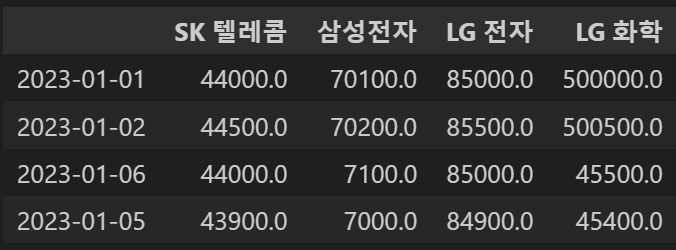
- 데이터 합
concat_df2['주가 총액']=concat_df2.sum(axis=1)
concat_df2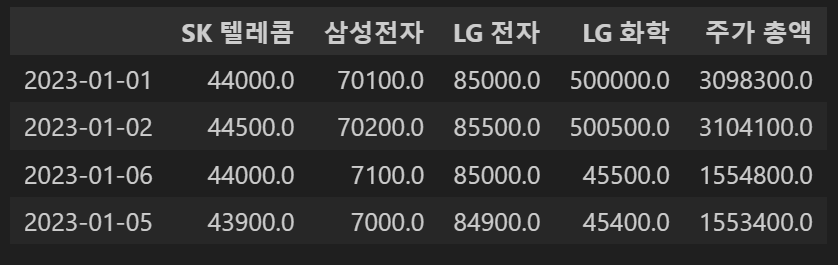
- 데이터 요약
#데이터의 기술통계량 요약
concat_df2.describe()
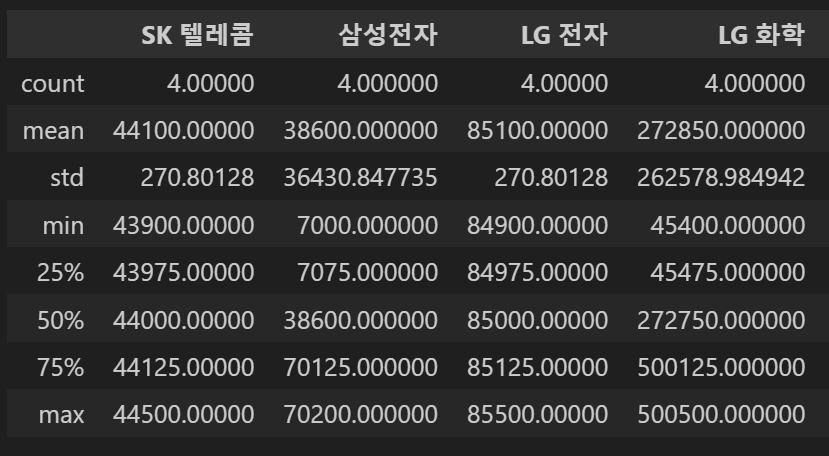
- 결측치 처리
- 대체 : fillna, interpolate
- 제거 : dropna,drop_duplicates
# 결측치 만들어 주기
import numpy as np
concat_df2.loc['2023-01-05',['LG 화학','LG 전자']]=np.NaN
concat_df2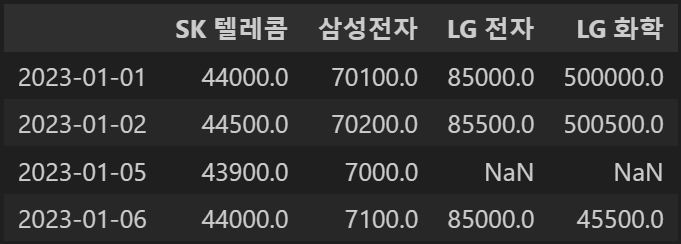
concat_df2.dropna() #결측치가 포함된 행 삭제
concat_df2.dropna(axis=1) #결측치가 포함된 열 삭제
concat_df2.fillna(0)#0으로 채우기
concat_df2.fillna(method='ffill')#바로 앞 값으로 채우기
concat_df2.fillna(method='bfill')#뒤 값으로 채우기
concat_df2.interpolate()#전 후의 중간값으로 채우기
concat_df2.drop_duplicates()# 중복값 삭제
concat_df2.drop_duplicates('삼성전자')#'삼성전자'열의 중복값을 기준으로 행 삭제
idx=concat_df2['삼성전자'].drop_duplicates().index
concat_df2.loc[idx, :]#'삼성전자'열의 중복값을 기준으로 행 삭제실습
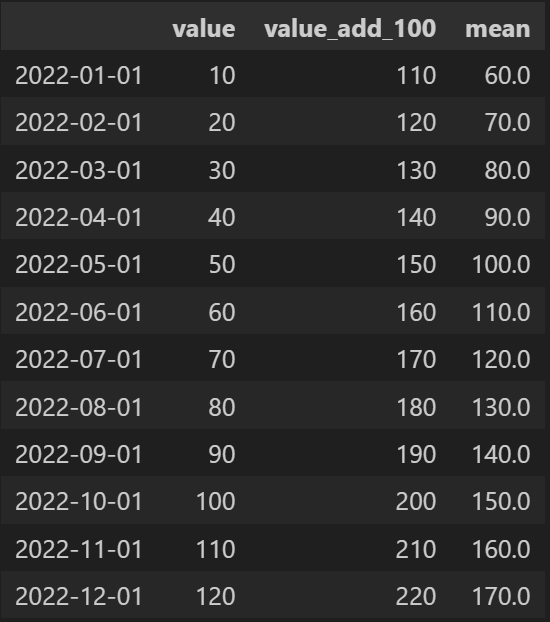
Q1. 2022-01-01 ~ 2022-12-01 월초 인덱스를 생성
df3=pd.DataFrame(index=dates)
df3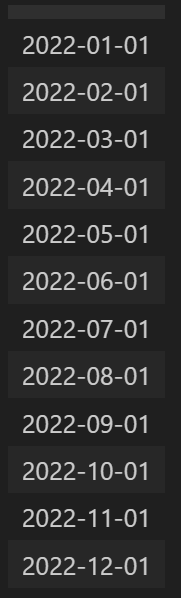
Q2. Q1에서 생성한 인덱스를 가지고 데이터프레임 생성(값은 자율, 이때 칼럼이름은 value)
df3=pd.DataFrame(column,index=dates)
df3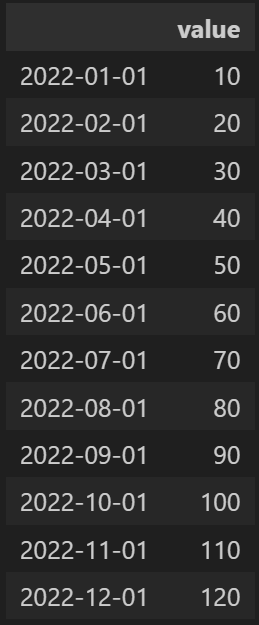
Q3. value 칼럼에서 100을 더한 value_add_100 칼럼을 생성해주세요.
df3['value_add_100']=df3['value']+100
df3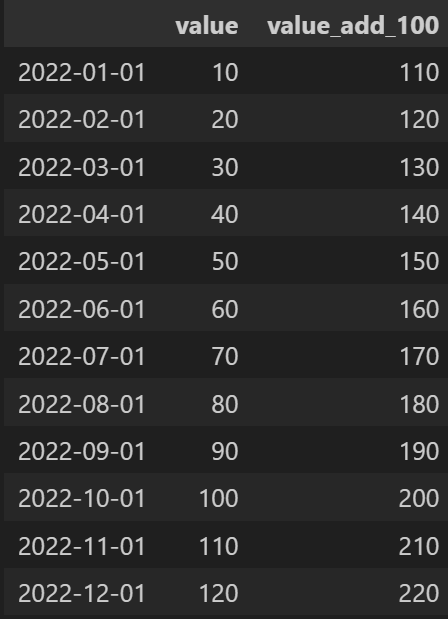
Q4. value 칼럼과 value_add_100 칼럼을 평균한 mean 칼럼을 생성해주세요.
df3['mean']=df3.mean(axis=1)
df3