
<수업 내용>
- df.idxmax(axis=0) : 가장 큰 값을 갖는 인덱스 출력
- 데이터 프레임 컬럼명 변경
- df.columns=['컬럼명']
- df.rename(columns={0:'컬럼명'}, inplace =True)
데이터 불러오기
import pandas as pd
AAPL = pd. read_csv("https://raw.githubusercontent.com/jin0choi1216/dataset/main/AAPL.csv", index_col=0)
AAPL.head()
AAPL.tail()
데이터 추출하기
AAPL[AAPL['Close']>=150]
AAPL[(AAPL['Close']>=150) &(AAPL['Open']>=160)]
AAPL.query('Close>=150 and Open >=160')
- & : and
- | : or
#쿼리 구문을 사용
AAPL.query("Volume<=75000000")
AAPL.query("Date>='2023-01-01'")
AAPL.query('Open > Close') #컬럼간의 대소 비교 후 추출AAPL[AAPL['Volume'].isin([302220800,260022000])]
AAPL.query('Volume in [302220800,260022000]')
AAPL.query('Volume=="117467900"')- 인덱스를 칼럼으로 만들기
AAPL.reset_index()실습
Q. Volume 이 평균이상이면서 Open이 Close보다 높은 데이터를 선택한 데이터 프레임을 가져오기
AAPL[(AAPL["Volume"]>=AAPL["Volume"].mean())&(AAPL["Open"]>=AAPL["Close"])]
apply(**)
#데이터 불러오기
df_kospi = pd.read_csv('https://raw.githubusercontent.com/jin0choi1216/dataset/main/KOSPI_stocks.csv', index_col=0)
df_kospi.head()# 방법1
def check_change(data):
if data >0:
return '오른주식'
else:
return '내린주식'
df_kospi['방법1']=df_kospi['ChagesRatio'].apply(check_change)
df_kospi.head()
#방법2
df_kospi['방법2']=df_kospi['ChagesRatio'].apply(lambda x :'오른주식' if x>0 else '내린주식')
df_kospi.head()#방법3
import numpy as np
df_kospi['방법3']=np.where(df_kospi['ChagesRatio'] > 0, '오른주식', '내린주식')
df_kospi.head()- .value_counts() : 컬럼 값의 개수 세주기
- .rank() , .rank(ascending=False) : 컬럼 값을 높은 순서로 정렬하기
실습
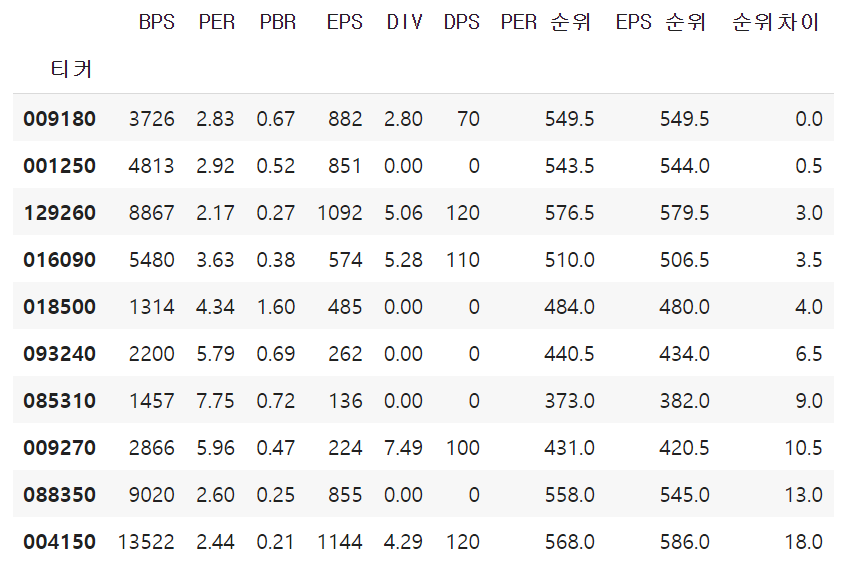
Q. 주당 순이익(EPS)이 0이상 기업 중 PER순위 -EPS순위의 차이가 가장 적은 10개의 기업 출력
df = pd.read_csv('https://raw.githubusercontent.com/jin0choi1216/dataset/main/market_fundamental_20230817.csv', index_col = '티커')
df_2=df[df["EPS"]>=0]
df_2["PER 순위"]=df_2["PER"].rank(ascending=False)
df_2["EPS 순위"]=df_2["EPS"].rank()
df_2["순위차이"]=abs(df_2["PER 순위"]-df_2["EPS 순위"])
df_2.sort_values(by="순위차이", ascending=True, inplace= True)
df_2.head(10)
Group by
df_krx = pd.read_csv("https://raw.githubusercontent.com/jin0choi1216/dataset/main/KRX_stocks.csv", index_col=0)
df_krx.head()
df_krx.groupby('Market').mean()["ChagesRatio"]
df_krx[["Market","ChagesRatio"]].groupby("Market").mean()

- .agg() : 컬럼별로 다른게 연산 하고자 할 때
df_krx[["Market","ChagesRatio","Stocks"]].groupby("Market").agg({"ChagesRatio":"max","Stocks":"min"})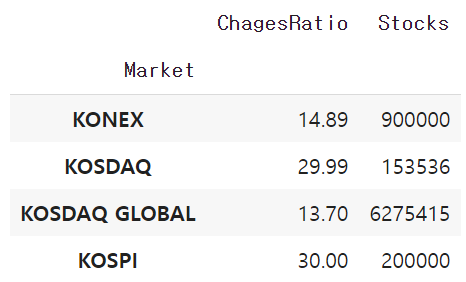
df_krx[["Market","ChagesRatio","Stocks"]].groupby("Market").agg({"ChagesRatio":["max","sum"],"Stocks":["min","mean"]})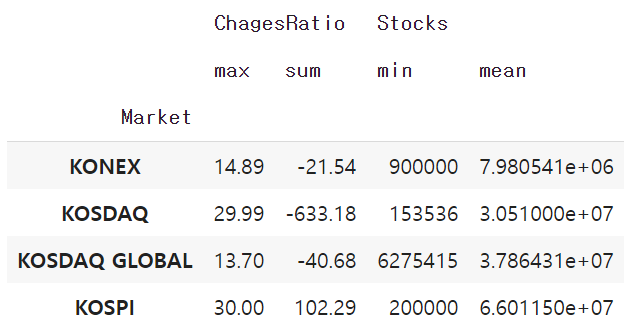
merge()
market_price_change = pd.read_csv('https://raw.githubusercontent.com/jin0choi1216/dataset/main/market_price_change_2022.csv')
purchases_of_equities = pd.read_csv('https://raw.githubusercontent.com/jin0choi1216/dataset/main/purchases_of_equities_2022.csv')market_price_change.head(2)
purchases_of_equities.head(2)
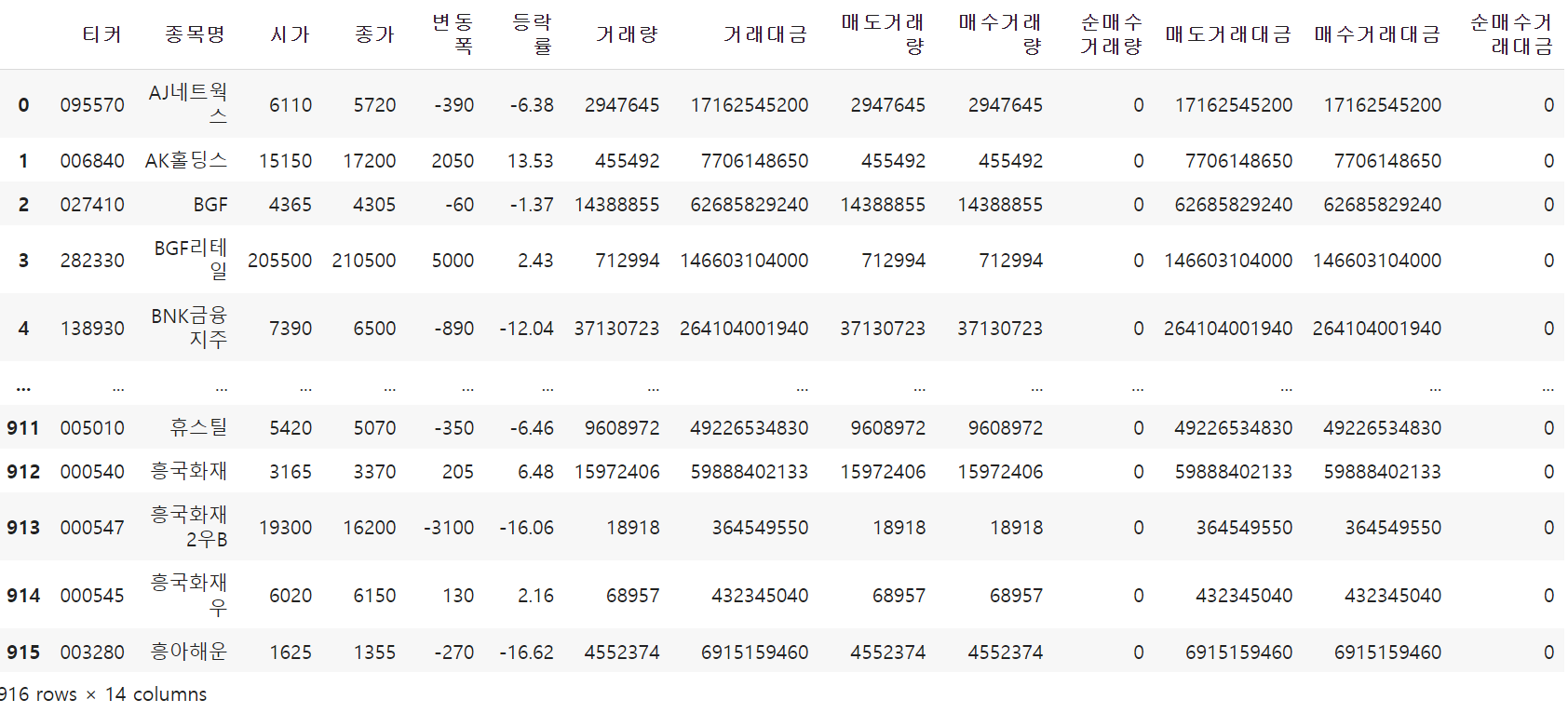
merge1=pd.merge(left= market_price_change,right=purchases_of_equities, on=["티커","종목명"])
merge1 #inner기준
merge2=pd.merge(left= market_price_change,right=purchases_of_equities, on=["티커","종목명"],how="left")
merge2 #왼쪽 기준
merge3=pd.merge(left= market_price_change,right=purchases_of_equities, on=["티커","종목명"],how="right")
merge3 #오른쪽 기준
merge4=pd.merge(left= market_price_change,right=purchases_of_equities, on=["티커","종목명"],how="outer")
merge4 #양쪽 기준
- 컬럼이름이 다르다면?
purchases_of_equities2=purchases_of_equities.rename(columns={"티커": "이름변경_티커", "종목명": "이름변경_종목명"})
pd.merge(left=market_price_change, right=purchases_of_equities2, left_on=["티커","종목명"],right_on=["이름변경_티커","이름변경_종목명" ], how="inner")
결측치 개수 확인
- .isnull()
- .isnull().sum()
pivot table
GOOGL = pd.read_csv('https://raw.githubusercontent.com/jin0choi1216/dataset/main/GOOGL.csv')
AAPL = pd.read_csv('https://raw.githubusercontent.com/jin0choi1216/dataset/main/AAPL.csv')
#concat으로 붙이기
GOOGL["Symbol"]="GOOGLE"
AAPL["Symbol"]="AAPL"
df=pd.concat([GOOGL,AAPL])
df
#pivot_table활용
pd.pivot_table(data=df, index="Date", columns ="Symbol", values="Close")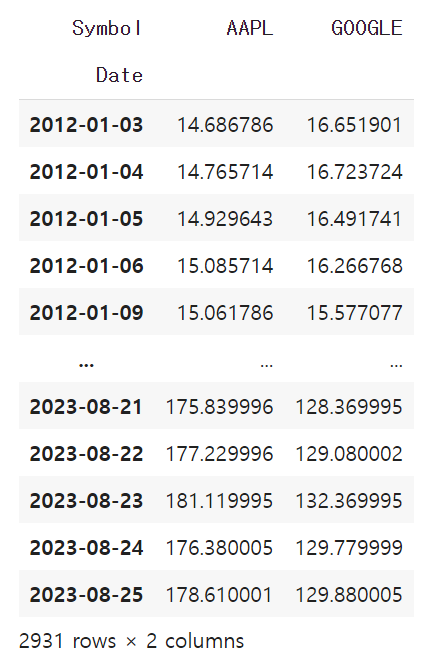
pd.pivot_table(data=df, index=["Date","Symbol"],values="Close")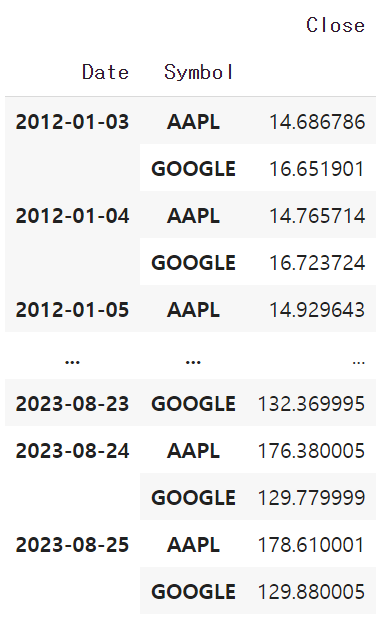
pd.pivot_table(data=df, index=["Date","Symbol"],values="Close", aggfunc="mean")
df[["Date","Symbol","Close"]].groupby(["Date","Symbol"]).mean()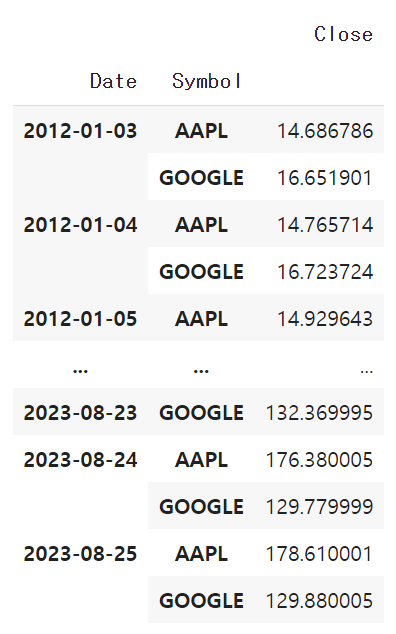
시계열 데이터 다루기
from datetime import datetime
date1= datetime(2023,9,12)
date1 #년,월,일
date2=datetime(2023,9,12,15,33,30)
date2 #년,월,일,시,분,초
print(date2.year)
print(date2.month)
print(date2.day)
print(date2.hour)
print(date2.weekday()) #월요일 0
import pandas as pd
date3='2023-09-12'
datetime_date3=pd.to_datetime(date3)
print(datetime_date3.year)
>2023datetime_date3.strftime("%Y%m")
> 202309#형식을 정해지지 않으면 의도와 다른 자료형이 나올 수 있다
date4='23-01-01'
pd.to_datetime(date4)
>Timestamp('2001-01-23 00:00:00')
date4='23-01-01'
pd.to_datetime(date4,format="%y-%m-%d")
>]
date4='23-01-01'
pd.to_datetime(date4,format="%y-%m-%d")
Timestamp('2023-01-01 00:00:00')
AAPL = pd.read_csv('https://raw.githubusercontent.com/jin0choi1216/dataset/main/AAPL.csv')
AAPL.head()
AAPL["Date"]=pd.to_datetime(AAPL['Date'])
AAPL["Year"]=AAPL["Date"].dt.year
AAPL["Month"]=AAPL["Date"].dt.month
AAPL["Day"]=AAPL["Date"].dt.day
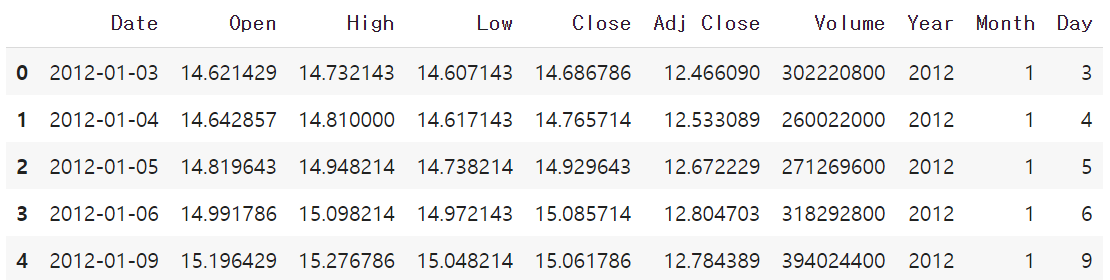
AAPL.head()
- APPL["Close"].diff() : 위 행에서 아래 행을 뺀 차이를 출력
- APPL["Close"].pct_change() : 위 행에서 아래 행의 차이를 퍼센트로 출력
- APPL["Close_shift1"]=AAPL["Close"].shift(1) :행을 하나 아래로 내려준다
이동평균 vs 누적평균
- 누적 평균: AAPL["ex_mean"]=AAPL["Close"].expanding().mean()
- 이동 평균 (window size=5):
AAPL["MA5"]=AAPL["Close"].rolling(window=5).mean()
