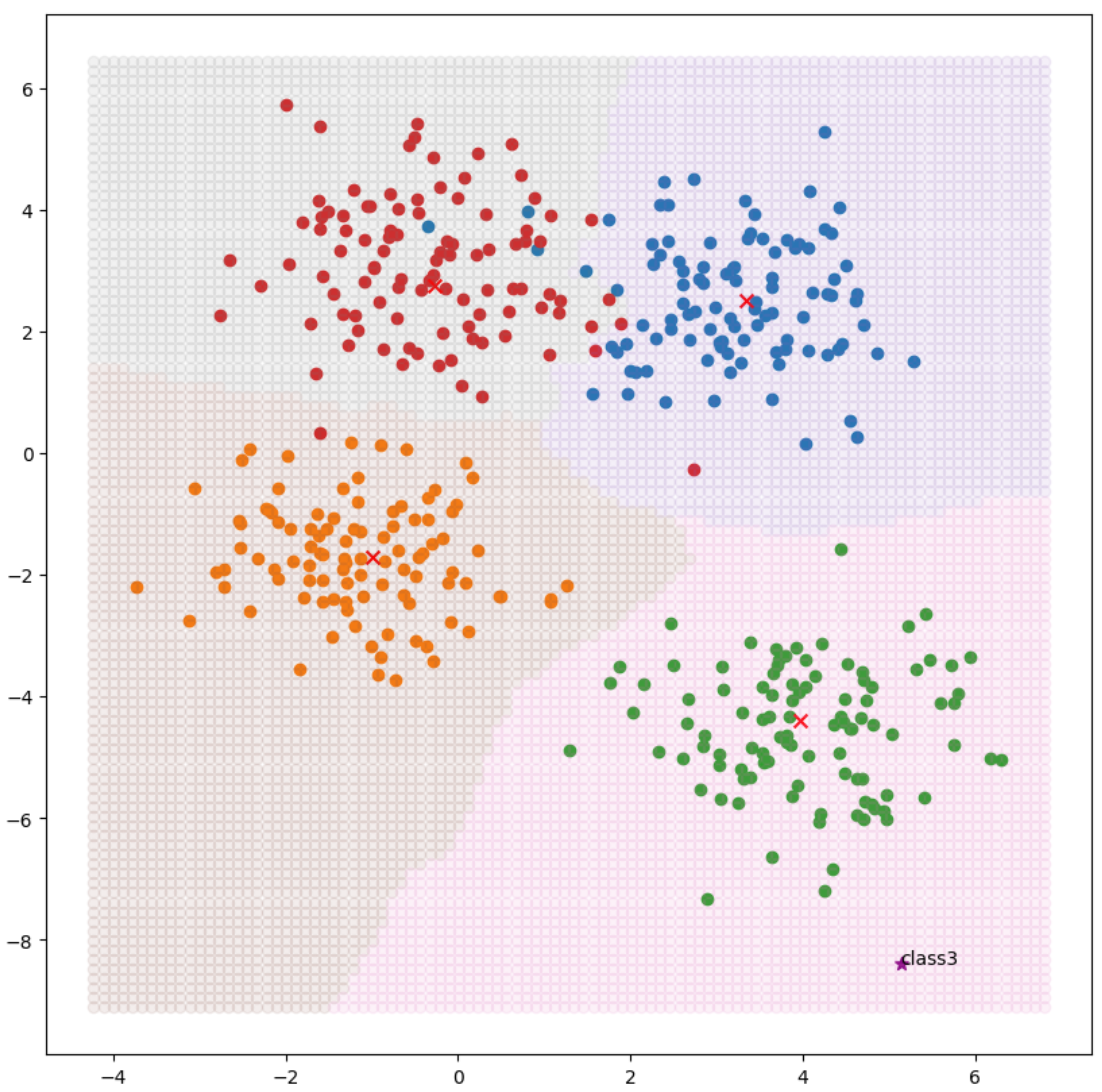
<수업 내용>
import numpy as np
import matplotlib.pyplot as plt
n_class=4
n_data=100
centroid_x=np.random.uniform(-5,5,size=n_class)
centroid_y=np.random.uniform(-5,5,size=n_class)
fig,ax=plt.subplots(figsize=(10,10))
data_set=[]
for i in range(n_class):
data=np.random.normal([centroid_x[i], centroid_y[i]], 1, size=(n_data, 2))
data_set.append(data)
ax.scatter(data_set[i][:,0] ,data_set[i][:,1])
ax.scatter(centroid_x[i], centroid_y[i], c='red', marker='x', s=50)
features=np.vstack(data_set)
target = []
for class_idx in range(n_classes):
data_ = np.full((100,), class_idx)
target.append(data_)
target = np.hstack(target)
test_data=np.random.uniform(-10, 10, size=2)
euclidean=[]
for i in range(len(features)):
distance=((test_data[0]-features[i][0])**2+(test_data[1]-features[i][1])**2)**(1/2)
euclidean.append(distance)
K=5
def find_class(K):
idx_distance=np.argsort(euclidean)
idx_min_distance=[]
for j in range(K):
indices = np.where(idx_distance == j)
idx_min_distance.append(indices)
test_target=[]
for i in idx_min_distance:
test_target.append(target[i])
uniques, cnts = np.unique(test_target, return_counts=True)
return uniques[np.argmax(cnts)]
ax.scatter(test_data[0],test_data[1], c='purple', marker='*', s=50)
ax.text(test_data[0],test_data[1],s=f'class{find_class(5)}')
x_lim=ax.get_xlim()
y_lim=ax.get_ylim()
X=np.linspace(x_lim[0],x_lim[1],100)
Y=np.linspace(y_lim[0],y_lim[1],100)
X_,Y_=np.meshgrid(X,Y)
grid_=np.vstack([X_.flatten(),Y_.flatten()]).T
euclidean_ = []
for i in range(len(grid_)):
grd = np.sum((features-grid_[i])**2,axis=1)
distance = np.sqrt(grd)
euclidean_.append(distance)
final=[]
test_target_=[]
sort_idx=[]
for i in range(len(euclidean_)):
idx_distance_= np.argsort(euclidean_[i])
target_closest = target[idx_distance_]
knn_target = target_closest[:5]
uniques, cnts = np.unique(knn_target, return_counts=True)
most_frequent = np.argmax(cnts)
y_hat = uniques[most_frequent]
final.append(y_hat)
final=np.array(final)
for i in range(n_class):
target_=grid_[final==i]
ax.scatter(target_[:,0],target_[:,1],alpha=0.1)