
큐 (Queue)
- 시간 순서상 먼저 집어 넣은 데이터가 먼저 나오는 선입선출 FIFO(First In First Out)형식으로 데이터를 저장하는 자료구조
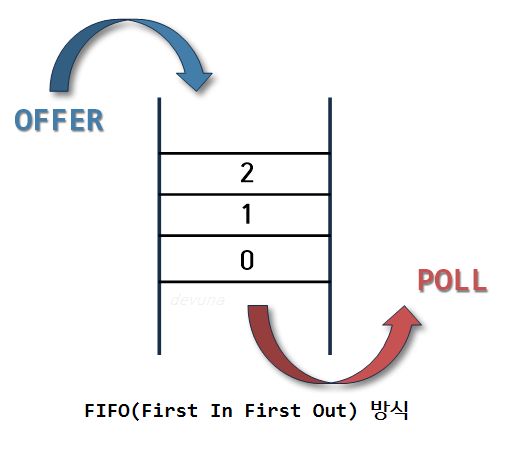
- 정해진 한 곳(top)을 통해서 삽입, 삭제가 이루어지는 스택과는 달리 큐는 한쪽 끝에서 삽입 작업이, 다른 쪽 끝에서는 삭제 작업이 양쪽으로 이루어진다.
- 삭제 연산만 수행되는 곳을 프론트(front), 삽입 연산만 이루어지는 곳을 리어(rear)로 정하여 각각의 연산 작업만 수행된다.
- rear에서 이루어지는 삽입 연산을 인큐(enqueue) 라고 한다.
- front에서 이루어지는 삭제 연산을 디큐(dequeue) 라고 한다.
- 데이터 접근, 삽입, 삭제가 빠르지만 중간에 위치한 데이터에 대한 접근이 불가능하다.
시간복잡도
- enqueue의 경우 queue의 맨 뒤에 데이터를 추가하면 완료되기 때문에 시간복잡도는 O(1) 이다. 이와 비슷하게 dequeue의 경우 맨 앞의 데이터를 삭제하면 완료 되기 때문에 동일하게 O(1)의 시간복잡도를 갖는다.
| 연산 종류 | 시간복잡도 |
|---|---|
| 삽입 | O(1) |
| 삭제 (delete) | O(1) |
| 삭제 (remove) | O(N) |
| 검색 | O(N) |
구현 방식
선형 큐 (Linear Queue)
- 선형 배열을 사용하여 구현된 큐
- 삽입을 위해서는 계속해서 요소들을 이동시켜야 한다.
front,rear는 증가만 하는 방식으로,front앞쪽에 공간이 있더라도 삽입할 수 없는 경우가 발생할 수 있다.
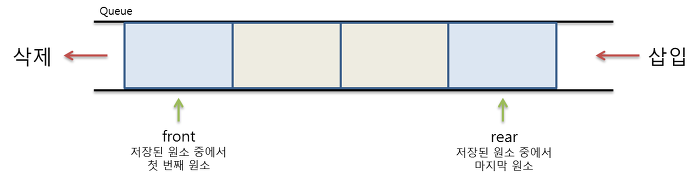
push
- push를 이용해 데이터가 들어오면 rear위치에 데이터를 집어넣고 rear를 +1한다.
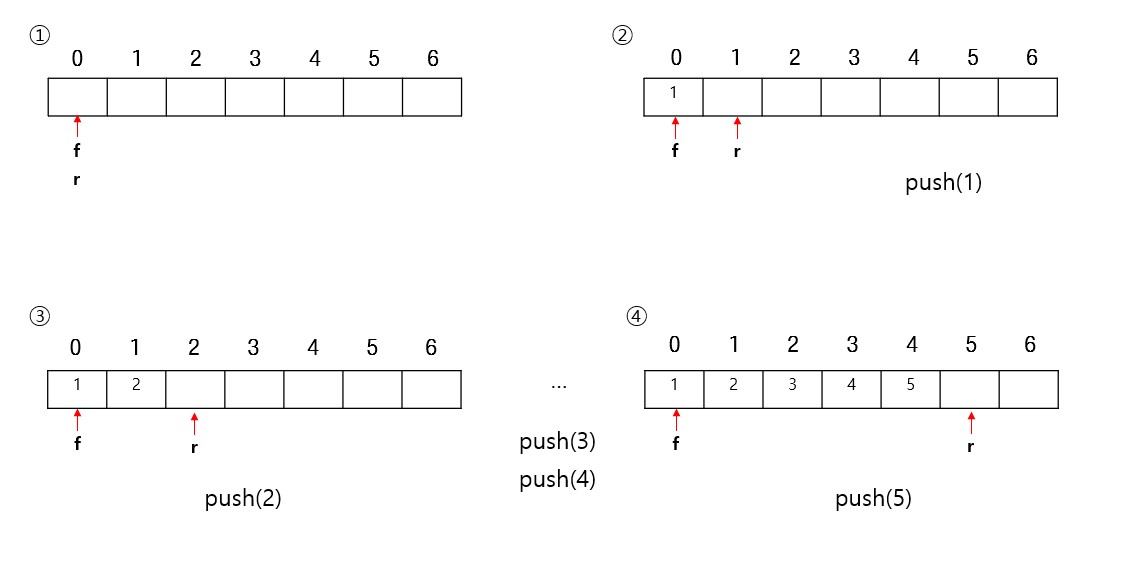
pop
- 큐(Queue)에서 데이터를 빼낼 때는 front위치에 있는 값을 가져오고 front를 +1 한다.
- 이때 우리가 보기에는 데이터가 삭제되는거 같지만, 더이상 접근하지 못할 뿐 사실 데이터는 존재한다.
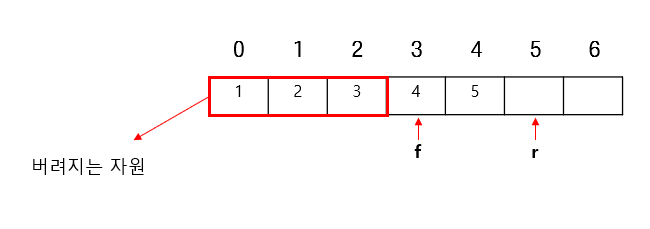
문제점
- pop 수행 당시 데이터를 사용하고 해당 위치는 더이상 접근하지도, 사용하지도 않는다.
- 계속해서 데이터가 들어와야한다면 더 큰 크기가 필요하며, 버려지는 공간도 계속해서 생길 것이므로 자원 낭비가 발생할 수 있다.
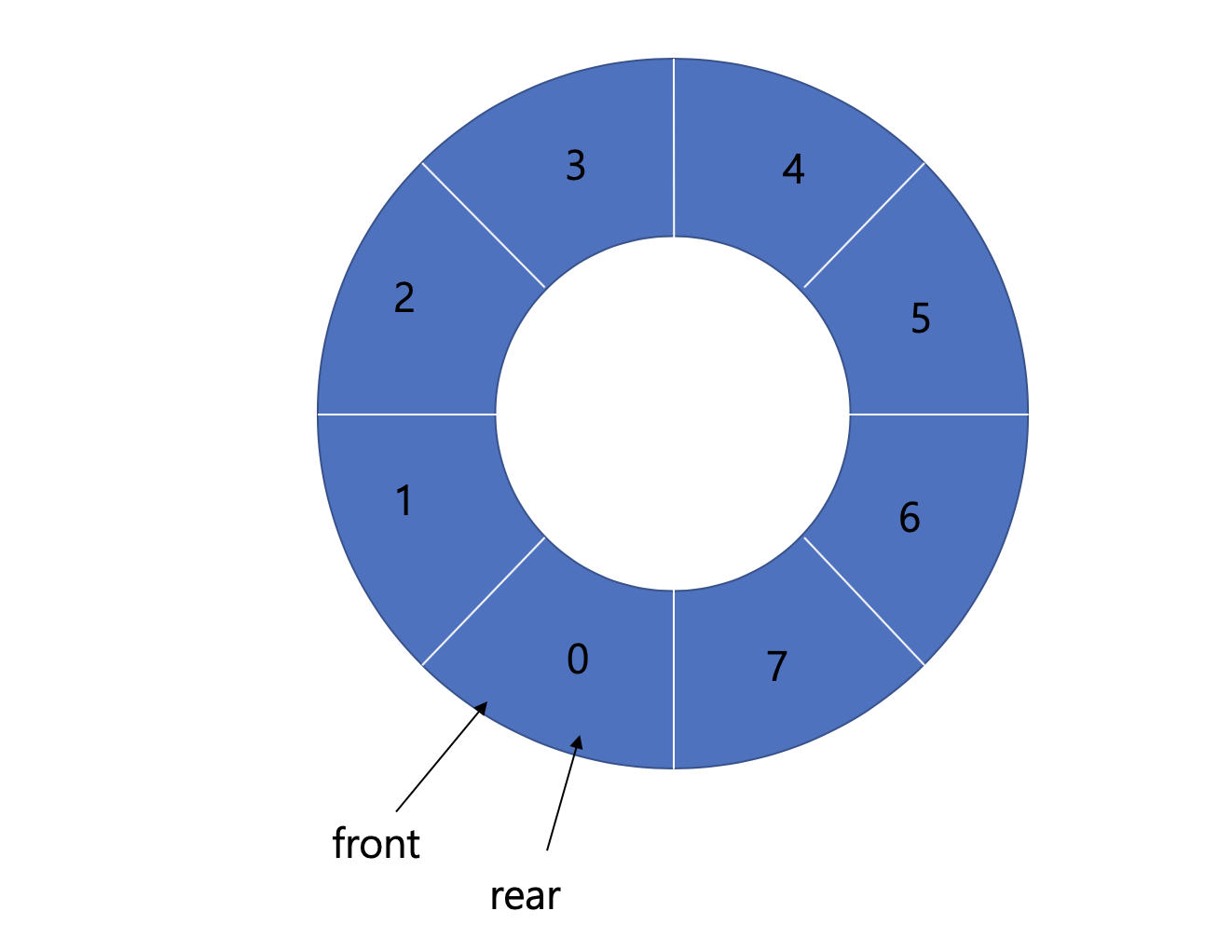
원형 큐 (Circular Queue)
- 원형 형태를 가지는 큐
- 데이터 삽입, 삭제 시 인덱스가 점점 뒤로 밀리면서 앞에 있던 공간을 사용하지 못하는 선형 큐의 문제점을 보완
- FIFO 구조이며, front 위치에 데이터를 가져오고 rear에 삽입하는 기본적인 기능은 선형 큐와 동일하다.
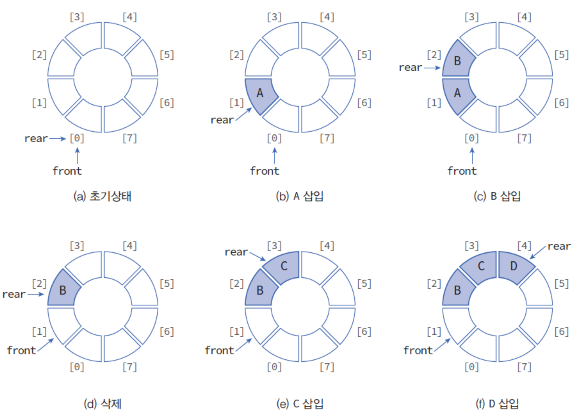
- 다만, rear가 배열의 마지막까지 도달했는데 만약 배열의 맨 앞의 데이터가 빠져서 빈 공간이 생기면 rear는 다시 첫 인덱스로 돌아가 데이터를 저장 할 수 있다.
- 데이터의 맨 앞과 맨 뒤의 위치를 기억하기 때문에 기존의 큐처럼 데이터를 매번 한 칸씩 당겨오지 않아도 공간이 허락하는 한 데이터를 빠르게 처리할 수 있다.
- 원형 큐를 구현하기 위해 나머지 연산자(%)를 활용할 수 있다.
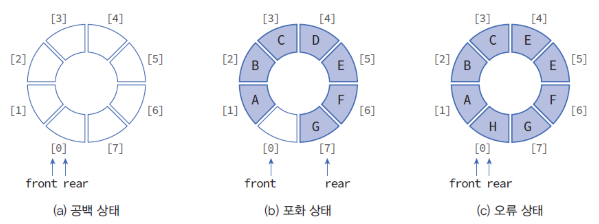
- 포화상태 :
front == (rear+1) % MAX_QUEUE_SIZE
- 포화상태 :
큐의 확장 & 활용 예시
우선순위 큐
- 시간 순서상 먼저 집어 넣은 데이터가 먼저 나오는 선입선출 FIFO(First In First Out) 구조로 저장하는 Queue 자료구조와 달리 우선순위큐(priority queue)는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나온다.
- Queue 와 Priority queue 시간 복잡도 비교
| Queue | Priority queue | |
|---|---|---|
| 삽입 | enqueue | dequeue |
| 삭제 | push | pop |
큐의 활용 예시
- 데이터를 입력된 순서대로 처리해야 할 때
- BFS 알고리즘
- 프로세스 관리
- 대기 순서 관리
스택 (Stack)
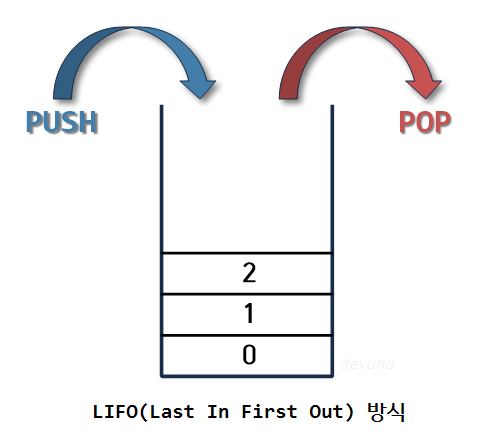
- 시간 순서상 가장 최근에 추가한 데이터가 가장 먼저 나오는 후입선출 LIFO(Last In First Out)형식으로 데이터를 저장하는 자료구조
- stack에서 데이터를 추가하는 것을 push라고 하고 데이터를 추출 하는 것은 pop이라고 한다.
- push와 pop은 모두 stack의 top에 원소를 추가하거나 삭제하는 형식으로 구현된다.
- top 을 통해 접근하기 때문에 데이터 접근, 삽입, 삭제가 빠르다.
- top 위치 이외의 데이터에 접근할 수 없기 때문에 탐색이 불가능하며, 탐색하기 위해서는 모든 데이터를 꺼내면서 진행해야 한다.
시간복잡도
- push의 경우 stack의 맨 뒤에 데이터를 추가하면 완료되기 때문에 시간복잡도는 O(1)
- pop의 경우도 맨 뒤의 데이터를 삭제하면 완료 되기 때문에 O(1)의 시간복잡도를 갖는다.
| 연산 종류 | 시간복잡도 |
|---|---|
| 삽입 | O(1) |
| 삭제 (delete) | O(1) |
| 삭제 (remove) | O(N) |
| 검색 | O(N) |
스택의 활용 예시
- 재귀 알고리즘
- DFS 알고리즘
- 작업 실행 취소와 같은 역추적 작업이 필요할 때
- 괄호 검사, 후위 연산법, 문자열 역순 출력 등
Stack 두 개를 이용하여 Queue 구현하기
- queue의
enqueue()를 구현할 때 첫 번째 stack을 사용하고,dequeue()를 구현할 때 두 번째 stack을 사용하면 queue를 구현할 수 있다. - 편의상
enqueue()에 사용할 stack을instack이라고 부르고dequeue()에 사용할 stack을outstack이라고 하자. - 두 개의 stack으로 queue를 구현하는 방법은 다음과 같다.
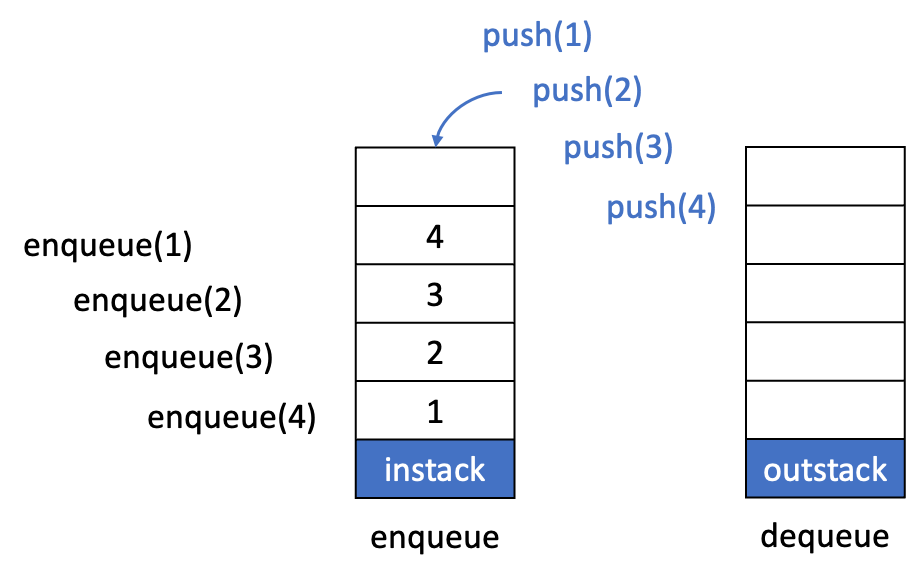
enqueue()
- instack에
push()를 하여 데이터를 저장한다.
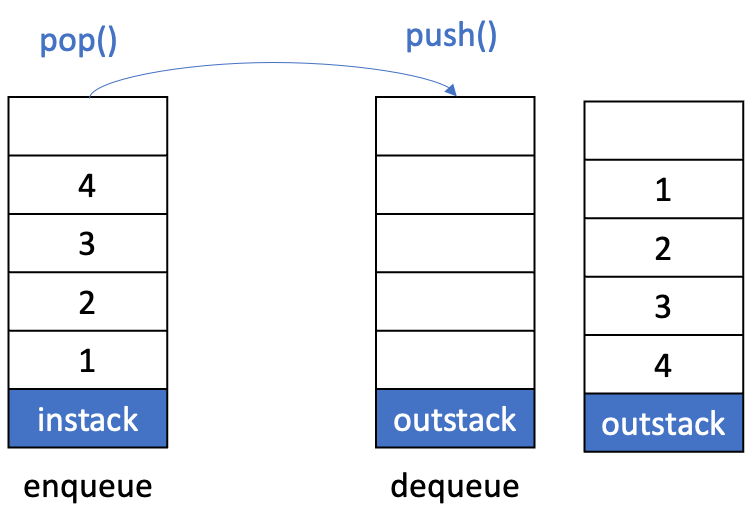
dequeue()
- 만약 outstack이 비어 있다면
instack.pop()을 하고outstack.push()를 하여 instack에서 outstack으로 모든 데이터를 옮겨 넣는다.- 이 결과로 가장 먼저 왔던 데이터는 outstack의 top에 위치하게 된다.
- 이 결과로 가장 먼저 왔던 데이터는 outstack의 top에 위치하게 된다.
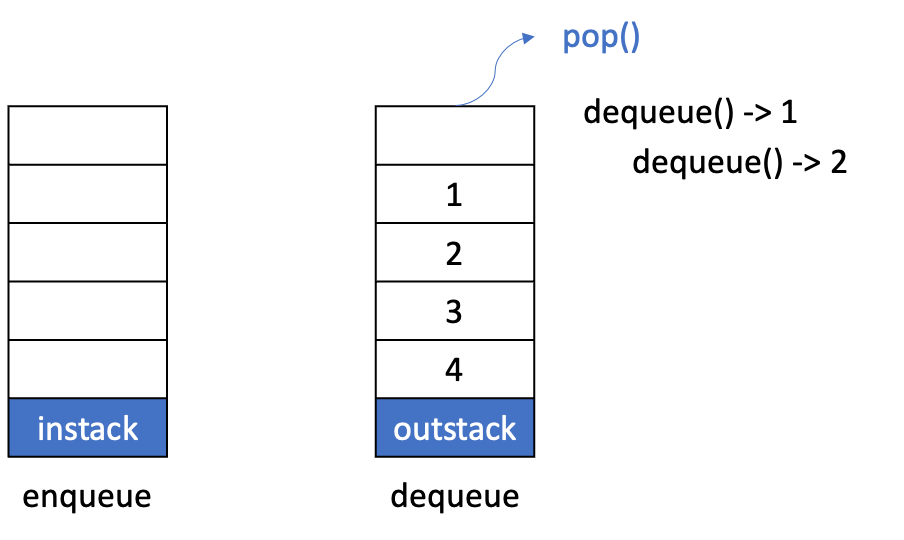
outstack.pop()을 하면 가장먼저 왔던 데이터가 가정 먼저 추출된다. (FIFO)
Queue 두 개로 Stack 구현하기
- 편의상
push()에 사용할 queue는 q1이라고 부르고pop()에 사용할 queue를 q2라고 하자. - 두 개의 queue로 stack을 구현하는 방법은 다음과 같다.
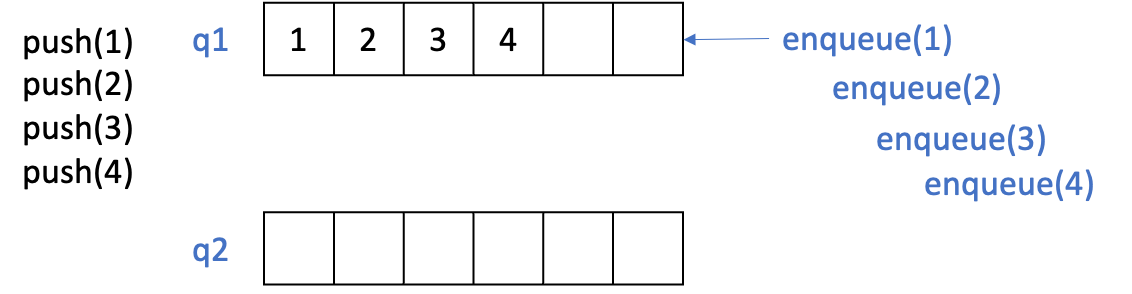
push()
- q1으로 enqueue()를 하여 데이터를 저장한다.
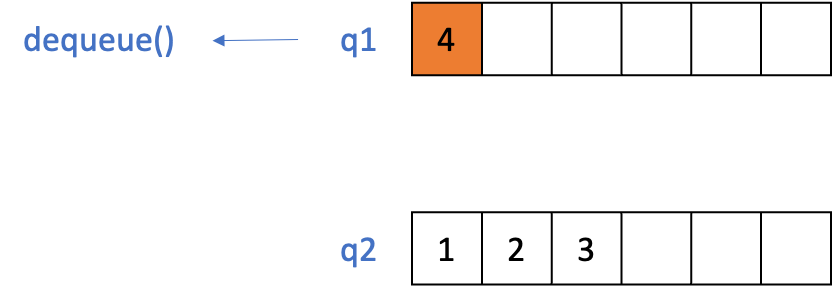
pop()
- q1에 저장된 데이터의 갯수가 1 이하로 남을 때까지
dequeue()를 한 후, 추출된 데이터를 q2에enqueue()한다.- 결과적으로 가장 최근에 들어온 데이터를 제외한 모든 데이터는 q2로 옮겨진다.

- 결과적으로 가장 최근에 들어온 데이터를 제외한 모든 데이터는 q2로 옮겨진다.
- q1에 남아 있는 하나의 데이터를
dequeue()해서 가장 최근에 저장된 데이터를 반환한다.(LIFO)
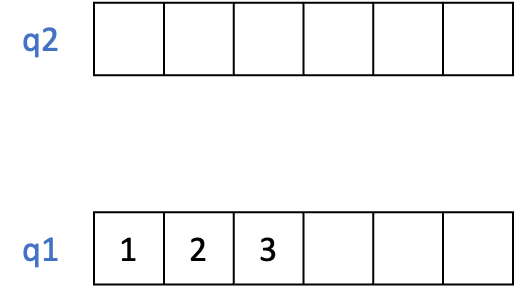
- 다음에 진행될
pop()을 위와 같은 알고리즘으로 진행하기 위해 q1과 q2의 이름을 swap한다.
예상 면접 질문
- Queue는 무슨 자료구조 인가요?
- Stack은 어떤 자료구조 인가요?
- Stack 두 개를 이용하여 Queue를 구현해 보세요.
- Queue 두 개를 이용하여 Stack을 구현해 보세요.
- Queue vs priority queue를 비교하여 설명해 주세요.
References
[자료구조] 스택 Stack, 큐 Queue, 덱 Deque
[자료구조] 스택 (STACK), 큐(QUEUE) 개념/비교 /활용 예시
[자료구조] 큐, 선형 큐
[자료구조] 스택과 큐, 데크(Stack, Queue, Deque)

코드로 꿈을 펼치는 개발자의 이야기, 노력과 열정이 가득한 곳 🌈