
Redis란?
Redis는 메모리 기반의 NoSQL 데이터베이스로 Key, Value 구조의 비정형 데이터를 메모리에 저장하여 빠른 읽기 및 쓰기 속도를 제공합니다. 주로 캐시나 세션 저장소로 사용됩니다.
데이터베이스, 캐시, 메세지 브로커로 사용되며 인메모리 데이터 구조를 가진 저장소입니다.
Redis의 특징
-
Redis는 디스크 기반의 DB와 달리 메모리(RAM)에 데이터를 저장하는 메모리 기반 저장소입니다. 그래서 읽기/쓰기 속도가 매우 빠릅니다.
-
Redis는 단일 스레드로 동작하는데, 이는 멀티 스레드보다 단일 스레드가 더 간단하고, Redis의 작업 대부분이 빠르기 때문입니다. 하지만 병렬 처리가 필요한 작업에서는 여러 인스턴스를 사용하여 확장성을 확보할 수 있습니다.
-
Redis는 문자열, 리스트, 세트, 해시, 정렬된 세트 등 다양한 데이터 구조를 지원합니다. 이를 통해 다양한 종류의 데이터를 효율적으로 처리할 수 있습니다.
-
TTL (Time to Live): Redis는 키에 대해 TTL을 설정할 수 있습니다. TTL이 만료되면 해당 키는 자동으로 삭제됩니다.
Redis Persistence(영속성)
Redis는 데이터를 디스크에 저장하여 재시작 시 복구할 수 있습니다.
-
RDB (Redis Database):
- RDB 영속성은 명시된 간격마다 dateset의 해당 시점의 스냅샷을 수행합니다.
.rdb파일 생성. - 장점: 빠른 복구, 성능 영향 적음.
- 단점: 마지막 스냅샷 이후 데이터 손실 (예: 300초 간격 → 최대 300초).
- 예:
save 300 10(300초 내 10번 쓰기 시 스냅샷).
- RDB 영속성은 명시된 간격마다 dateset의 해당 시점의 스냅샷을 수행합니다.
-
AOF (Append-Only File):
- 서버로 수신된 모든 쓰기 작업을 기록하고 서버 재시작 시 수행돼서 원래의 데이터 셋을 재구축합니다.
- 장점: 데이터 손실 최소 (fsync
everysec→ 최대 1초). - 단점: 파일 크기 증가, 복구 느림.
- 예:
appendfsync everysec.
-
혼합 모드:
- RDB와 AOF 결합, 빠른 복구와 내구성 균형.
- 예:
appendonly yes,save 300 10.
-
비활성화:
- 서버가 수행 중인 동안에만 데이터를 존재하게 하려면 영속성을 완전히 비활성화할 수 있습니다.
- 예:
save "",appendonly no.
💡 Redis는 인메모리 스토어로, 빠른 응답을 위해 Picket 프로젝트의 랭킹 검색에서 캐시로 사용됩니다. 하지만 메모리는 휘발성이므로 영속성 옵션과 통신 오류 대응이 중요합니다.
Picket Project에서의 영속성
-
캐시 역할: Redis는 키(예:
ranking:popular_keywords)를 저장, 원본 데이터는 RDS(예:SearchLog)에 저장 -
영속성 필요 낮음:
- 데이터 손실 허용, 스케줄러가 즉시 갱신
redisTemplate.expire(POPULAR_KEYWORD_RANKING_KEY, 1, TimeUnit.HOURS);
- 데이터 손실 허용, 스케줄러가 즉시 갱신
-
RDS 폴백
List<Object[]> topKeywords = searchLogRepository.findTopKeywordsSince(LocalDateTime.now().minusDays(1)); -
설정:
save "",appendonly no로 디스크 I/O 제거, 성능 최적화. -
재시작 시:
ranking:popular_keywords소실, 스케줄러 또는 폴백으로 복구.
🙋♀️ Picket 프로젝트 랭킹 시스템에서는 Redis는 캐시로 사용하고 원본 데이터를
SearchLog테이블에 저장하기 때문에 영속성 필요성이 낮다. 따라서 영속성을 비활성화하고, Redis가 사용 불가능하거나 캐시된 데이터가 없을 경우 RDS로 폴백(fallback)하여 시스템 안정성을 유지한다.
랭킹 시스템은 조회수, 좋아요, 인기 검색어 랭킹이 있는데 이 때 조회수는Showtable에, 좋아요 수는Liketable에, 인기 검색어는SearchLogtable에 저장한다.
Redis를 이용한 캐싱과 RDS로의 Fallback 처리 플로우 차트
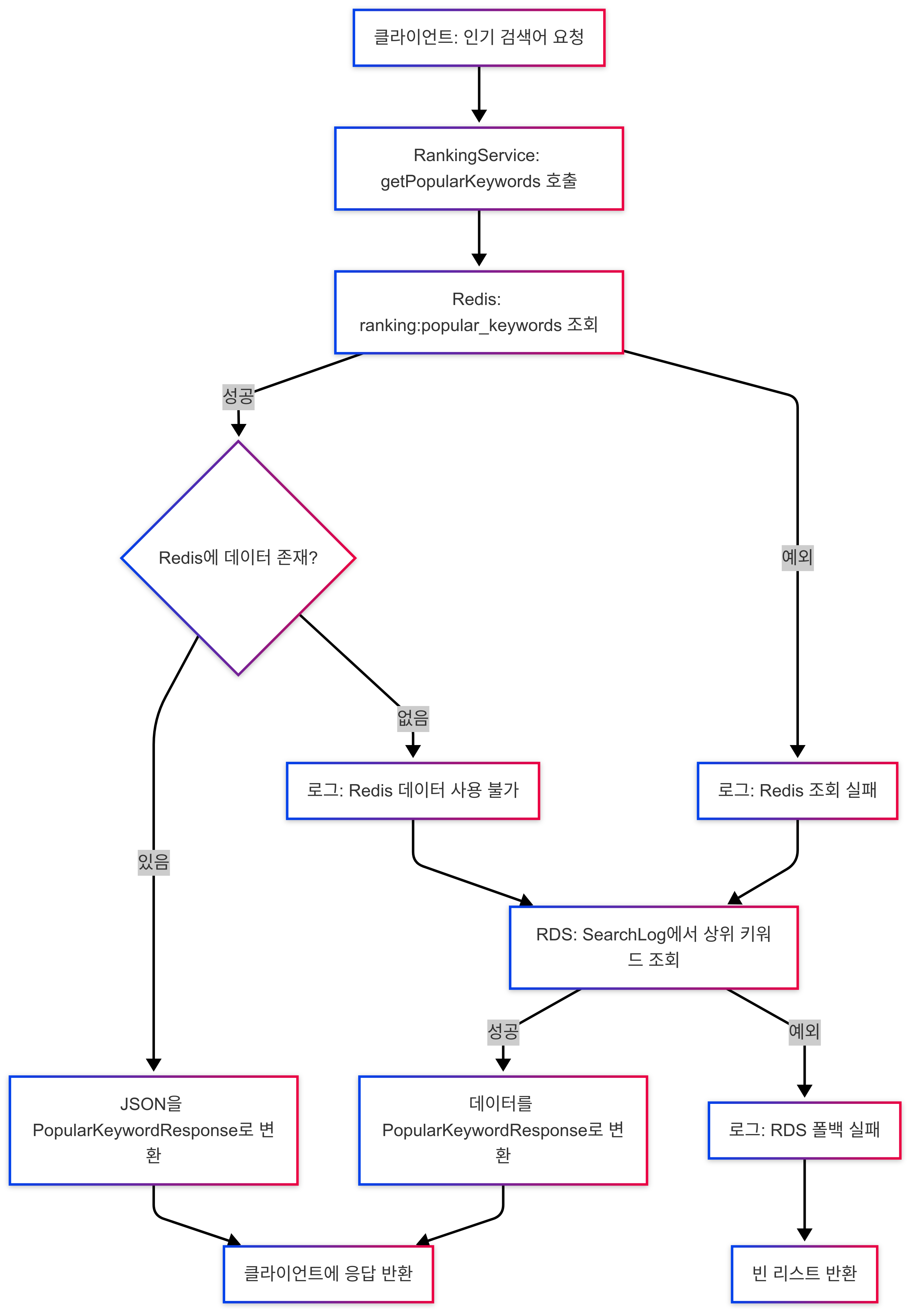
flowchart TD
A[클라이언트: 인기 검색어 요청] --> B[RankingService: getPopularKeywords 호출]
B --> C[Redis: ranking:popular_keywords 조회]
C -->|성공| D{Redis에 데이터 존재?}
C -->|예외| E[로그: Redis 조회 실패]
D -->|있음| F[JSON을 PopularKeywordResponse로 변환]
D -->|없음| G[로그: Redis 데이터 사용 불가]
E --> H[RDS: SearchLog에서 상위 키워드 조회]
G --> H
H -->|성공| I[데이터를 PopularKeywordResponse로 변환]
H -->|예외| J[로그: RDS 폴백 실패]
I --> K[클라이언트에 응답 반환]
F --> K
J --> L[빈 리스트 반환]💻 RankingService.getPopularKeywords
public List<PopularKeywordResponse> getPopularKeywords() {
List<String> jsonKeywords = null;
try {
jsonKeywords = redisTemplate.opsForList().range("ranking:popular_keywords", 0, -1);
} catch (Exception e) {
log.warn("Redis 조회 실패, RDS로 폴백: {}", e.getMessage());
}
if (jsonKeywords != null && !jsonKeywords.isEmpty()) {
List<PopularKeywordResponse> keywords = jsonKeywords.stream()
.map(json -> {
try {
PopularKeyword keyword = objectMapper.readValue(json, PopularKeyword.class);
return PopularKeywordResponse.toDto(keyword);
} catch (Exception e) {
log.error("검색 키워드 역직렬화 실패: {}", json, e);
return null;
}
})
.filter(keyword -> keyword != null)
.toList();
log.info("Redis에서 {}개 검색 키워드 조회 완료", keywords.size());
return keywords;
}
log.warn("Redis 데이터 사용 불가, RDS로 폴백");
try {
List<Object[]> topKeywords = searchLogRepository.findTopKeywordsSince(LocalDateTime.now().minusDays(1));
List<PopularKeywordResponse> fallbackKeywords = topKeywords.stream()
.map(row -> PopularKeyword.toEntity(
(Category) row[0],
(Long) row[1],
LocalDateTime.now()
))
.map(PopularKeywordResponse::toDto)
.toList();
log.info("RDS에서 {}개 검색 키워드 조회 완료", fallbackKeywords.size());
return fallbackKeywords;
} catch (Exception e) {
log.error("RDS 폴백 실패, 빈 리스트 반환: {}", e.getMessage());
return List.of();
}
}A: 인기 검색어 요청 -> GET /api/v2/rankings/popular-keywords
B: RankingService에서 getPopularKeywords 호출
C: 호출 성공 시 -> redisTemplate.opsForList().range
D: Redis에 데이터 존재? -> jsonKeywords != null && !jsonKeywords.isEmpty()
E: 호출 실패 시 -> log.warn("Redis 조회 실패, RDS로 폴백: {}")
G: Redis에 데이터 없음 -> log.warn("Redis 데이터 사용 불가, RDS로 폴백")
H: SearchLog에서 상위 키워드 조회 -> searchLogRepository.findTopKeywordsSince
F: Redis에 데이터 있음 -> JSON 역직렬화 (objectMapper.readValue)
I: SearchLog에서 상위 키워드 조회 성공 -> RDS 데이터 변환 (PopularKeyword.toEntity)
J: SearchLog에서 상위 키워드 조회 실패 -> log.error("RDS 폴백 실패, 빈 리스트 반환: {}")
K: client에 응답 반환 return keywords 또는 return fallbackKeywords
L: 빈 리스트 반환 return List.of()
