priorty queue
선택 정렬, 추후 삽입 정렬을 다룰 예정인데, 그 전에 우선순위 큐에 대한 이야기를 먼저 할 필요가 있다.
우선순위 큐는 알고리즘이 아닌 자료구조이다. 우선순위 큐라는 자료구조를 이용한 정렬(선택 정렬, 삽입 정렬)이 알고리즘이 되겠다.
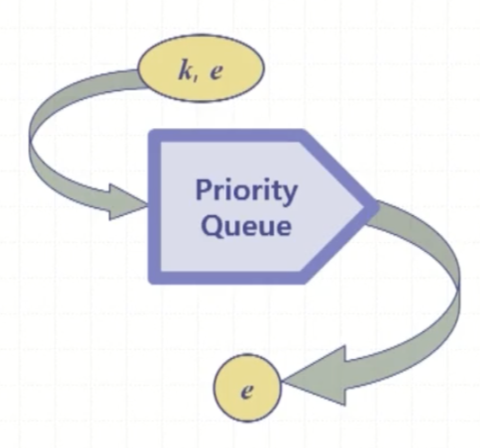
우선순위 큐에 대한 개념은 간단하다. 큐에 어떤 원소가 들어올 때, 우선순위에 따라 원소를 저장하고 있다가 우선순위에 따라서 원소를 출력하든 반환하든 하는 것이다.
우선순위 큐의 주요 메서드는 다음과 같다.
- insert(k)
- removeMin()
삽입과 삭제가 가장 중요할 것이다.
removeMin()은 k값이 가장 낮은 원소를 우선순위가 높다고 가정하고 있기 때문이다. k가 높을 수록 우선순위가 큰 것이라면 removeMax()가 될 것이다.
우선순위 큐의 의사코드는 다음과 같다.
Alg priorityQueue(L){
input list L
output sorted list L
P <- empty PQ //1. 우선순위 큐 준비
while(!L.isEmpty()){ //2. L의 원소들을 하나씩 빼서 P에 insert
e <- L.removeFirst()
P.insert(e)
}
while(!P.isEmpty()){ //3. P의 원소들을 하나씩 빼서 L에 insert
e <- P.removeMin()
L.addLast(e)
}
return정렬되지 않은 리스트를 정렬하여 반환하고 있다.
L의 원소를 하나씩 빼서 P에 insert한 후, L에 다시 돌려주는 느낌.
그런데 우선순위 큐에 insert하는 방식에는 2가지가 있다.
막 넣냐 vs 순서대로 넣냐
막 넣는 것은 우선순위 큐가 무순리스트, 순서대로 차곡차곡 넣는 것이라함은 순서리스트로 우선순위 큐가 짜여져 있는 것이다. 두 성격의 우선순위 큐를 비교해보자.
- 우선순위 큐가
무순리스트인 경우
- unordered. 순서가 없다.
- insert() : O(1). 아무렇게나 넣어도 되기 때문이다.
- remove() : O(N). 제거 시에 최소 키값을 찾기 위한 시간이 걸린다.
- 우선순위 큐가
순서리스트인 경우
- ordered.
- insert() : O(N). 어떤 원소가 큐에 들어가려면 반드시 그 자리를 찾아야 한다.
- remove() : O(1). 키값 순서대로 있기 때문에 첫 번째를 빼면 된다.
매를 먼저 맞냐, 나중에 맞냐라 할 수 있겠다.
매를 먼저 맞게 된다면(순서리스트), 삽입 정렬이다.
매를 나중에 맞게 된다면(무순리스트), 선택 정렬이다.
selection sort
매를 나중에 맞는,
우선순위 큐가 무순리스트로 구성되는 선택 정렬을 알 아 보 자.
실행 시간
insert()
- n회의 insert 작업
- insert() 1회에 O(1) 시간 소요
remove()
- n회의 remove 작업
- remove()는 최초 O(N) 마지막 O(1)
- N + (N-1) + ... + 2 + 1
- N * (N-1) / 2
최종적으로 O(N^2)의 시간이 걸린다.
제자리 선택 정렬
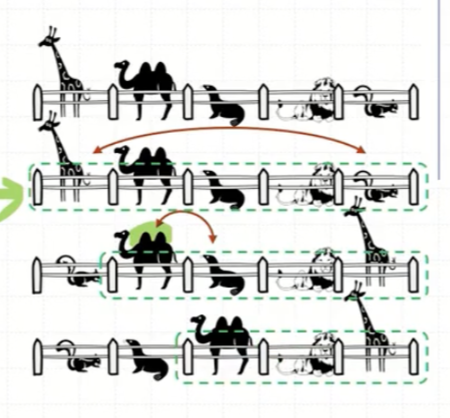
앞선 의사코드에서는 input list L 외에 외부 list P의 공간을 추가적으로 사용했다. 외부 메모리를 사용하지 않고 L에서 상수 메모리를 사용해 선택 정렬 알고리즘을 수행하는 것을 제자리 선택 정렬 알고리즘이라고 한다.
상수 공간에서 이루어지는 선택 정렬은 리스트의 앞부분을 정렬 상태로 유지하고 원소들을 swap() 해 나가는 형태로 알고리즘이 진행된다.
다음은 제자리 선택 정렬의 의사코드다.
Alg inPlaceSelectSort(A)
input array A of N keys
output sorted array A
for(idx <- 0 to N-2){
minLoc <- idx
for(j <- idx+1 to N-1){
if(A[j] < A[minLoc]){
minLoc <- j
}
}
A[idx] <-> A[minLoc]
}
returnminLoc은 반복문 상에서 최솟값의 위치가 된다. idx는 그 최솟값이 들어갈 위치를 말한다.
idx는 0부터 N-2를 검사한다. N-1을 고려하지 않는 이유는 N-2까지 반복문을 돌면 배열 전체가 정렬이 되기 때문이다.
minLoc은 최초 idx로 초기화를 한다.
내부 반복문으로 들어가서는 idx의 뒷부분부터 배열의 끝까지 검사한다. 반복문에서 최솟값의 위치를 알아낸 후 idx 원소와 minLoc 원소를 교환한다. minLoc을 선택하여 교환해 나가는 로직이다.
성능
선택 정렬은 완전히 정렬된 데이터가 input으로 들어오더라도 O(N^2)가 걸리게 된다. minLoc이 초기화 시에 정확하게 맞아 떨어지더라도 알고리즘 상에서는 내부 반복문을 O(N)의 시간복잡도로 돌아야 하기 때문이다.
참고 : 국형준. 알고리즘 원리와 응용. 21세기사, 2018.
