이전 포스팅까지 우선순위 큐의 개념부터 시작하여 선택 정렬, 삽입 정렬, 힙 정렬을 알아 보았다. 그리고 분할정복에 기반한 합병 정렬과 퀵 정렬도 공부했다.
이들 모두 원소들을 비교하며 정렬하기에 비교 정렬 알고리즘이라고도 한다.
다만, 선택 정렬과 삽입 정렬은 O(N^2)의 시간복잡도로 성능이 다소 낮고, 나머지 힙 정렬, 합병 정렬, 퀵 정렬은 O(N logN)에 수행된다. 여기서 퀵 정렬은 최악에 O(N^2)이다.
해당 포스팅은 지금까지의 비교정렬 알고리즘들에 대한 하한과 정렬 안정성을 다룬다.
비교정렬의 하한
지금까지의 비교정렬 알고리즘의 최고 성능은 O(N logN)이다. 이보다 더 빨리 수행할 수는 없을까? 이에 대한 답은 비교정렬 시간 성능의 이론적 하한에 있다.
비교정렬 시간 성능의 하한(lower bound)이란, N개 원소들을 비교하여 정렬하는 데 필요한 최소한의 시간을 말한다.

하한은 쉽게 말해, 원소들을 정렬하기 위해 비교를 해야 하는데 이러한 저울질을 몇 번 해야 하는지를 말하고 있다.
N개의 유일한 키가 있다고 했을 때, N개는 N!개의 순서가 존재한다. 우리에게 익숙한 오름차순 정렬, 내림차순 정렬은 N! 중 오직 하나의 순열만이 정렬 순서를 나타낸다.
비교정렬 알고리즘의 최선은 저울을 한 번 달아 N! 중 절반을 고려 대상에서 날려 버리는 것이다(1~100까지의 Up%Down 게임에서 50을 외치는). 따라서, 한 번의 비교 결과가 N!/2개의 고려 대상을 남기는 것이 최선이다. 다음의 비교는 N!/4의 고려 대상을 남길 것이다. 이렇게 쭉쭉 진행하면 분모에 2의 제곱이 계속되고 고려 대상은 1이 남게 된다.
결정트리
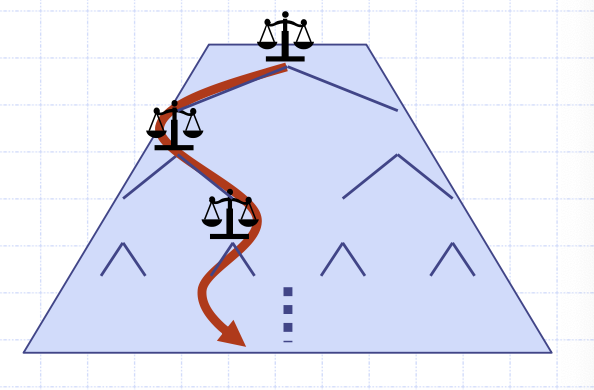
이진트리가 있을 때 비교를 수행하고 그 결과에 따라 한쪽 부트리로만 쭉쭉 내려가 visit하는 것을 결정트리라 한다. 그림과 같이 루트에서부터 최종 한 개로 하향만 한다. 이 결정트리의 노드의 총 개수는 N!개다.
여기서 중요한 사실 2가지는 알고리즘이 하향하는 과정에서 결정트리 노드에서마다 1번씩 비교를 하기 때문에 총 비교 횟수는 하향 경로 상의 노드 개수라는 것과, 이 노드 개수는 어느 방향이든 결정트리의 높이와 일치한다는 것이다. 결정트리의 높이가 총 비교정렬 시간의 하한이다.
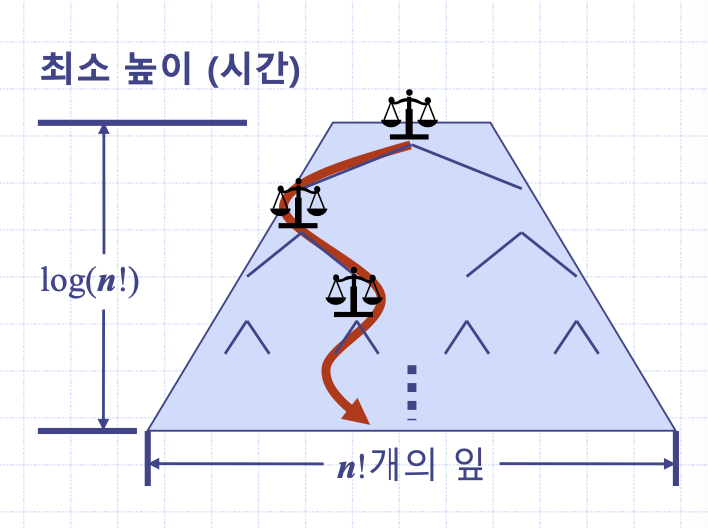
N개의 포화이진트리의 높이는 적어도 logN + 1이기 때문에, N!개의 노드가 존재하는 결정트리의 높이는 적어도 logN!이다.
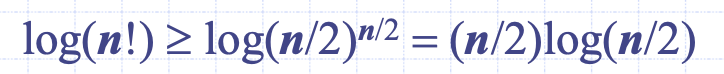
따라서, 어떠한 비교정렬 알고리즘도 최소 log(N!) 시간을 쓰게된다. 이는 어떠한 비교정렬 알고리즘이라도 빅-오메가(N logN)에 수행된다는 것을 의미한다. 결론적으로 힙 정렬, 합병 정렬, 퀵 정렬은 점근적 시간 성능에서 최선의 비교정렬 알고리즘이다.
정렬 안정성
비교정렬 알고리즘을 공부할 때, 많은 알고리즘에서 유일키를 가정했다. 정렬의 안정성은 동일키의 경우를 본다.
Key1과 Key2가 있을 때, 두 키값은 같고 초기 상태에서 Key1이 Key2보다 앞서 있었다면 정렬 후에도 Key1은 Key2의 앞에 있어야 정렬 알고리즘이 stable하다고 한다. 예를 들어 온라인 쇼핑몰에서 장바구니를 최근 출시 순으로 보고 있다가 낮은 가격순으로 봤을 때, 비안정적인 비교정렬 알고리즘은 동일 가격 상품들의 순서가 태그마다 바뀔 것이다.
결론적으로 선택 정렬, 삽입 정렬, 합병 정렬은 안정적이지만, 힙 정렬, 퀵 정렬은 비안정적이다. 힙 정렬은 downHeap(), upHeap() 과정에서 동일키들의 원래 순서가 바뀔 가능성이 있고 퀵 정렬은 partition()에서 피봇 선택 등에 따른 변수들로 동일키들의 순서가 뒤바뀔 수 있기 때문이다. 안정적이지 않은 정렬은 멀리 떨어진 원소와의 swap을 한다는 공통점이 있다.
참고 : 국형준. 알고리즘 원리와 응용. 21세기사, 2018.
