저번 포스트에 이어서 모델의 점수를 더 향상시켜보려고 한다.
저번에는 'datetime'에 hour데이터만 빼서 피쳐로 사용하여 모델을 학습시켰는데 이번에는 'datetime'에 year, weekday를 우선 추가해 보겠다.
train["datetime"]= train["datetime"].astype("datetime64") #날짜형식으로 바꾸기 64는 크기
train["hour"]=train["datetime"].dt.hour
train["year"]=train["datetime"].dt.year # year 데이터 받기
train["weekday"]=train["datetime"].dt.weekday #weekday데이터 받기
test["datetime"]= test["datetime"].astype("datetime64")
test["hour"]=test["datetime"].dt.hour
test["year"]=test["datetime"].dt.year
test["weekday"]=test["datetime"].dt.weekday
저번 포스트에서 year을 추가한 것 처럼 year과 weekday를 train_set과 test_set에 칼럼에 데이터를 추가한다.
- dt.weekday : 요일 반환 (0:월, 1:화, 2:수, 3:목, 4:금, 5:토, 6:일)
- dt.year : datetime중 연도 반환
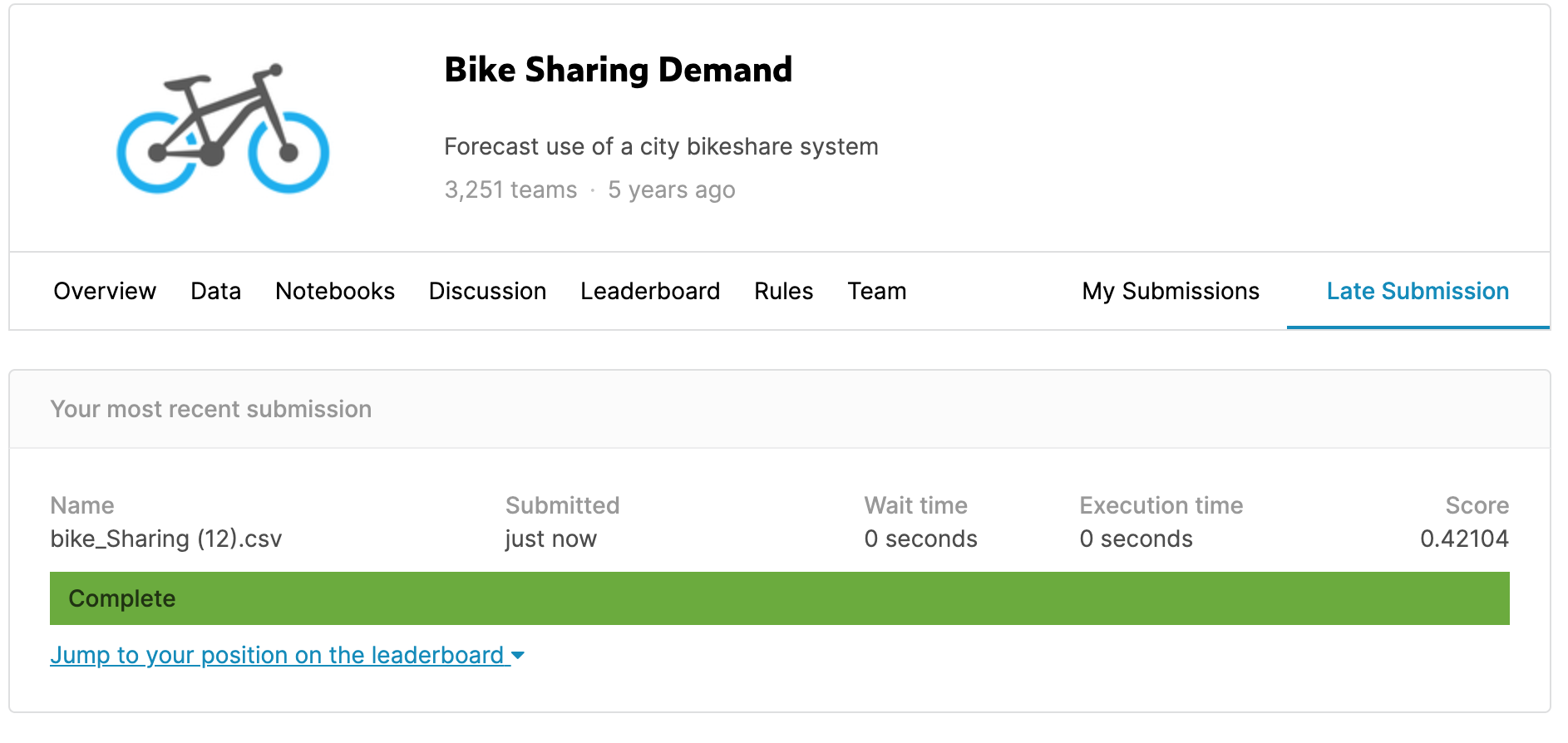
그리고 전체 코드를 실행하고 제출을 하게되면 점수가 0.42104로 모델의 점수가 향상된 것을 볼 수 있다.
이 점수를 Leaderboard를 통해 등수를 확인해보니 459등 인 것을 확인할 수 있었다.
저번 코드보다 약 236등 정도 향상되었다. 상위 14%로 저번 상위 41%보다 엄청나게 향상되었다.
단지, 년도 관련 데이터와 요일 관련 데이터를 추가했을 뿐인데 말이다.
pd.Series(rf.feature_importances_,index=train2.columns).sort_values(ascending=False) #변수 중요도 확인코드를 통해서 변수 중요도를 확인해보면
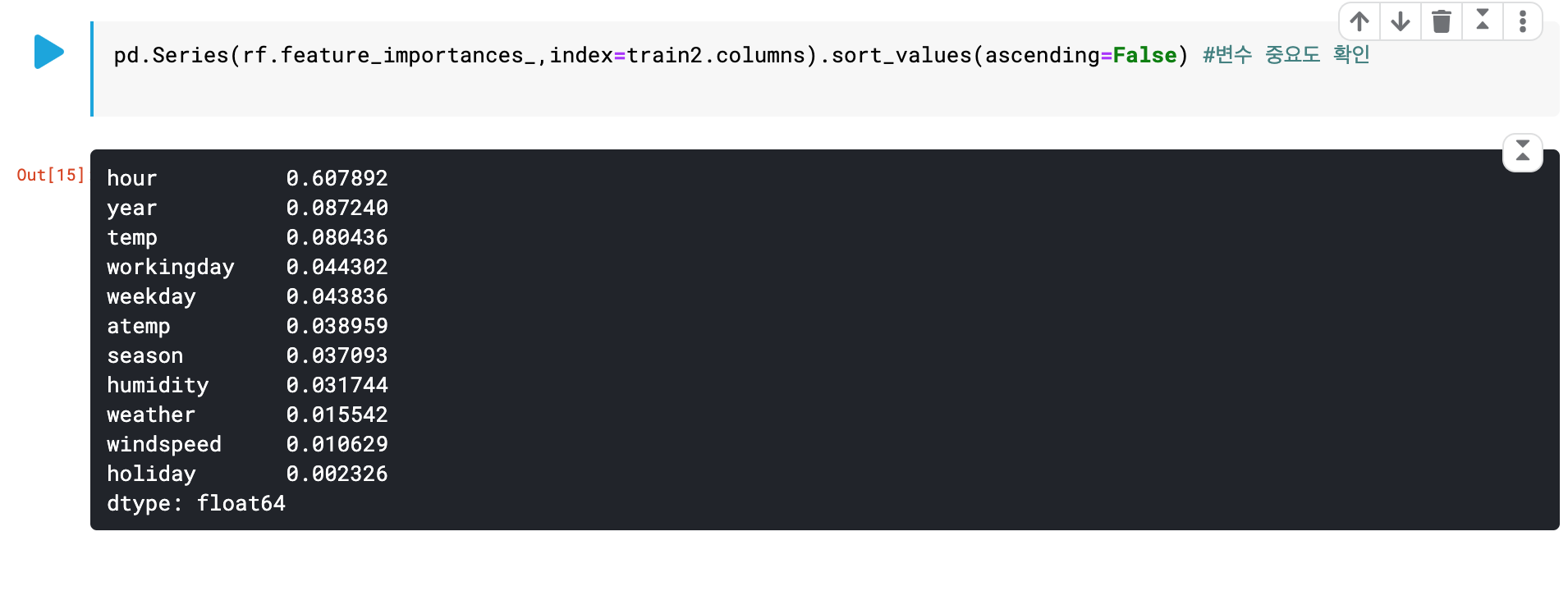
year칼럼과 weekday칼럼이 중요도중 상위권에 있는것을 볼 수 있다.
-> 중요도에서 상위권을 차지한다는 것은 그 데이터가 모델학습에 중요하다.
이 대회에서 사용한 모델은 '랜덤 포레스트'라는 모델인데
랜덤포레스트(RandomForest)
- 기계 학습에서의 랜덤 포레스트(영어: random forest)는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종으로, 훈련 과정에서 구성한 다수의 결정 트리로부터 부류(분류) 또는 평균 예측치(회귀 분석)를 출력함으로써 동작한다.
랜덤포레스트 모델은 트리 모델을 사용하기 때문에 모델의 의사결정 나무개수를 정해줘야한다.
from sklearn.ensemble import RandomForestRegressor
rf= RandomForestRegressor(n_estimators =100)
rf.fit(train2,train["count"])
result = rf.predict(test2)모델을 생성할때 n_estimators가 바로 의사결정 나무개수를 정하는 변수이다.
default값은 10인데 학습시킬 모델의 데이터가 복잡해지면 나무개수를 늘리는게 효과적이다. 하지만 너무 많이 늘리게 되면 발생하는 문제가 바로 오버피팅 즉, 과대적합 문제가 발생하게 되므로 적절하게 조절하여 생성해야 한다.
Overfitting(과대적합)이란
- 필요 이상의 특징을 발견하여 학습 데이터에선 높은 정확도를 보이지만 테스트 데이터나 새로운 데이터에는 정확도가 낮게 나오는 경우를 과대적합이라고 한다.
일반적으로 100개로 나무개수를 지정하게 되면 대부분 과대적합이 일어나지 않고 학습률이 높아진다.
데이터가 단순하든 복잡하든 랜덤포레스트는 가지수가 늘어나면 모델의 점수가 올라가지만 어느 정도가 되면 점수는 조금 올라가고 가지수가 늘어난만큼 시간이 오래걸리게되서 비효율적인 모델이 된다.
가지수를 100으로 설정하고 실행한 전체 코드의 제출 결과 점수는 0.42031으로 전체 Leaderboard에서 449등, 상위 13%에 해당되는 점수를 획득하였다.
다음 포스트에서는 데이터의 시각화를 통해 아웃라이어 즉, 튀는 값을 잡아 모델의 학습능력을 향상 시키는 것을 포스트 할 예정이다.
