저번에 이어서 이번에는 모델에 변수를 추가해서 점수를 향상시켜 볼것이다.
처음 변수로 추가할 데이터는 "datetime"칼럼의 데이터중 몇시에 빌렸는지
즉, hour(시간)데이터를 추가할 것이다.
이전에 진행했던 csv파일을 읽은 직후에 코드를 추가한다.
train["datetime"]= train["datetime"].astype("datetime64") #날짜형식으로 바꾸기 , 64는 크기
train["hour"]=train["datetime"].dt.hour
test["datetime"]= test["datetime"].astype("datetime64")
test["hour"]=test["datetime"].dt.hour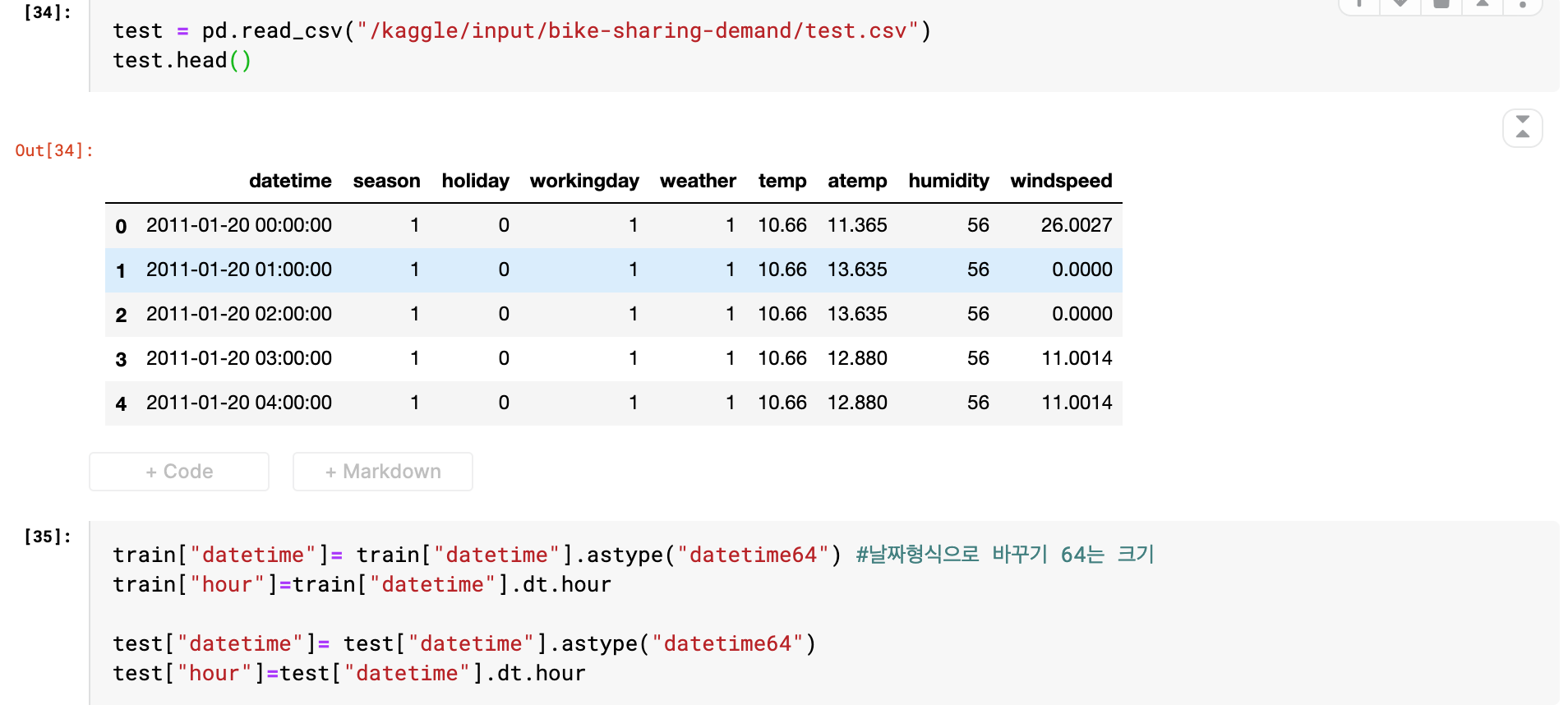
- 코드에 대한 설명을 하자면 train_set과 test_set의 "datetime"칼럼에 데이터의 형식이 기존에는 object형식이라서 학습에 사용하지 못했기 때문에 .astype()함수를 사용하므로써 날짜 형식으로 바꾼다.
이후 train_set과 test_set에 "hour"이라는 새로운 칼럼을 추가하고 그 데이터를 날짜 형식으로 변환한 "datetime"칼럼의 데이터중 dt.hour함수를 통해 시간데이터를 추출하여 추가한다.
새로운 변수를 추가할 때 그 변수로 쓰일 데이터가 과연 효과가 있는지 알 수 있는 방법이 있는데(무작정 추가하면 오히려 점수가 하락하는 효과가 있기때문..) 첫 번째 방법이
변수를 그룹화하여 결과 칼럼과의 변화를 확인하기
print(train.groupby("hour")["count"].mean()) #hour을 기준으로 그룹을 만들고 count의 변화를 보는 방법
train.groupby("hour")["count"].median() #median은 중간값 mean은 평균값
#print()는 이전에 출력된 결과가 묻히지 않게 무조건 출력해주는 함수다음 코드를 추가하므로써 새로 추가된 "hour" 칼럼의 변화에 따른 "count" 칼럼의 결과를 볼 수 있다.

- hour칼럼에 따른 count의 평균(mean)값 출력

- hour칼럼에 따른 count의 중간(median)값 출력
평균만 출력하는 것이 아닌 중간값도 확인하는 이유는 평균만 이용시 결과값의 신뢰도가 높지않기 때문이다.
두번째방법은
변수 중요도 확인하기
pd.Series(rf.feature_importances_,index=train2.columns).sort_values(ascending=False) #변수 중요도 확인- feature_importances를 사용하면 변수의 중요도를 시각화해서 볼 수 있다.
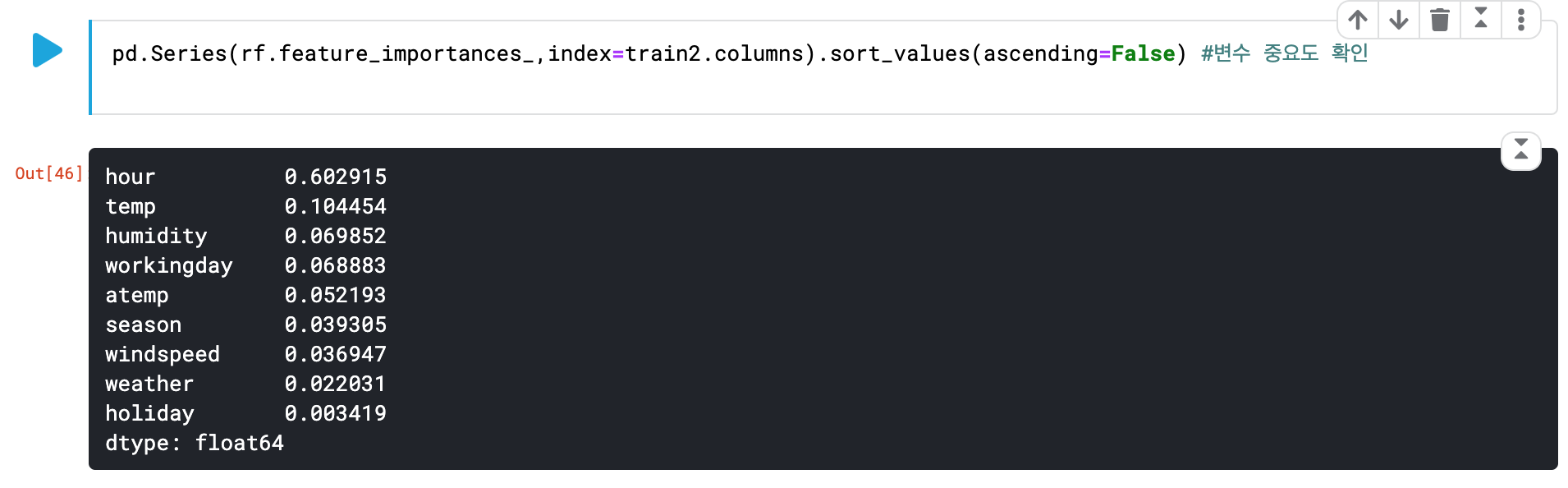
새로 추가한 "hour"칼럼의 중요도가 0.602915로 상당히 높은 편임을 시각적으로 이해할 수 있다.
->즉, 새로추가한 칼럼이 모델의 학습 정확도를 더 높여줄 수 있다.
이후 코드를 저장 한 후 제출을 하게되면 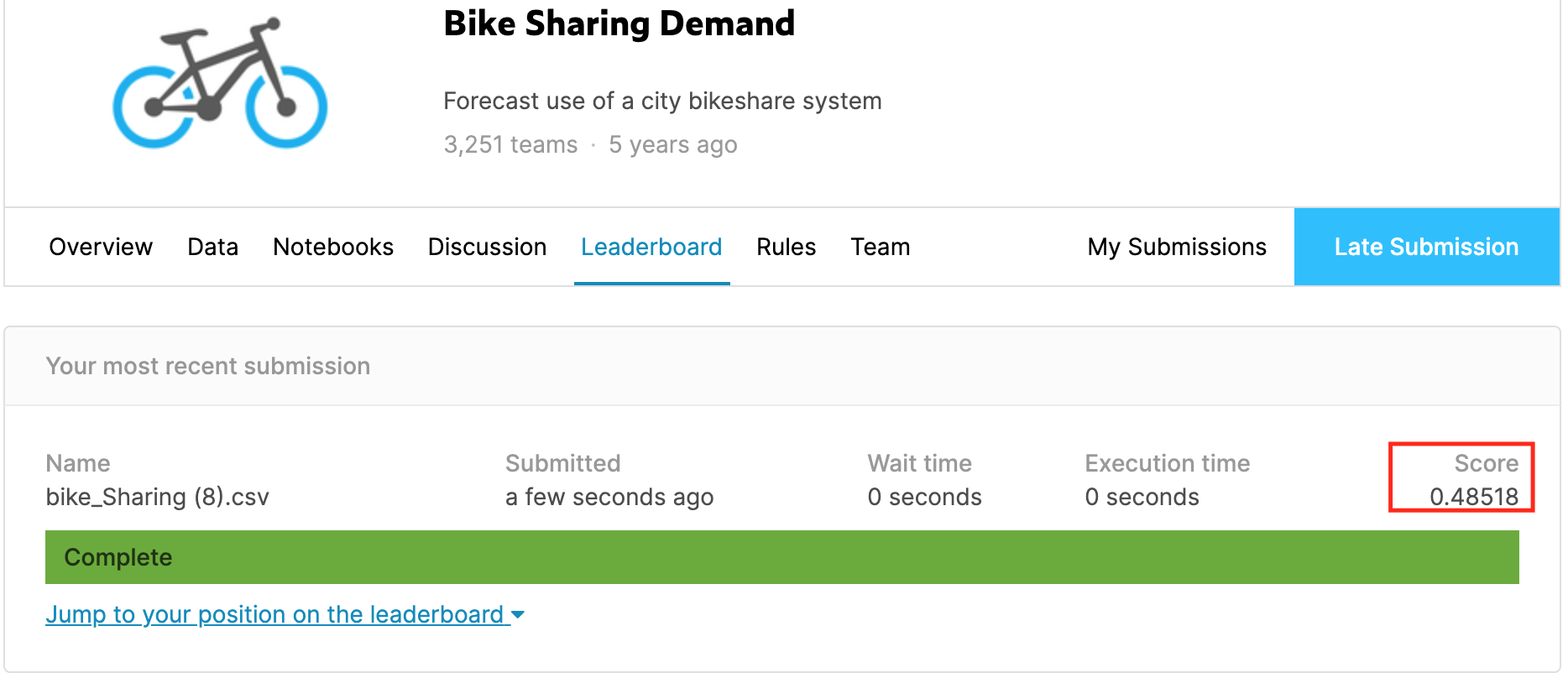
점수가 0.48518로 더욱 정확해졌으며 등수는 1338등으로 저번의 결과인 3039등보다 약 1700등정도 증가하였고 상위 41%가 되었다.
어려운 과정을 통한 것도 아니고 겨우 hour(시간)에 대한 데이터만 변수로 추가해주었을 뿐인데 2배가량 등수가 증가 하였다.
물론 이게 최종 결과는 아니다, 아직 사용하지 않은 의미있는 데이터가 너무 많이 있다.
다음 포스트에서는 나의 최종 점수까지의 진행과정을 포스트할 예정이다.
오랫만에 캐글을 다시 켜서 그런지 다시한번 복습하는 느낌이였고 흥미가 돌아와서 좋았다.
