Pandas?
대부분의 데이터는 table의 형태로 나타낼 수 있다. Pandas는 이러한 데이터를 다루기 위해 Series와 DataFrame을 제공한다.
Pandas 설치하기
- Pandas는 다음 코드로 설치할 수 있다.
pip install pandas
Pandas 시작하기
- 저번시간에 다루었던 Numpy처럼 Pandas도 관행적으로 pd라는 단축어로 사용한다.
import pandas as pd
Series
-
Series는 1차원 데이터를 다루기 위한 객체로, Numpy의 array와 사용법이 거의 유사하다.
Index를 지정해줄 수 있고, Index가 같이 출력된다는 특징이 있다.
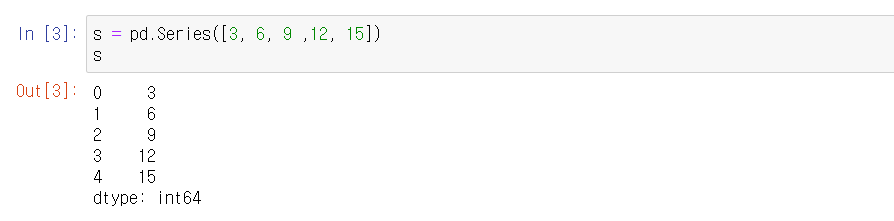
pd.Series()함수를 사용하여 생성한다.
Series선언을 할때 대문자 S를 실수하지 않도록 조심할 필요가 있다.
-
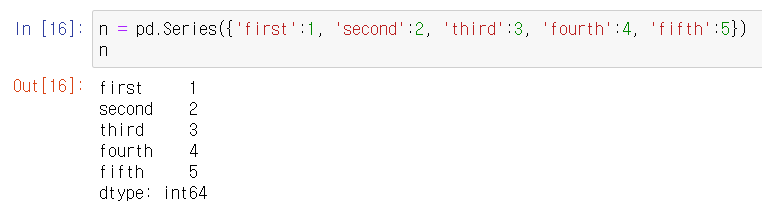
Index 지정해서 Series 생성하기.
-
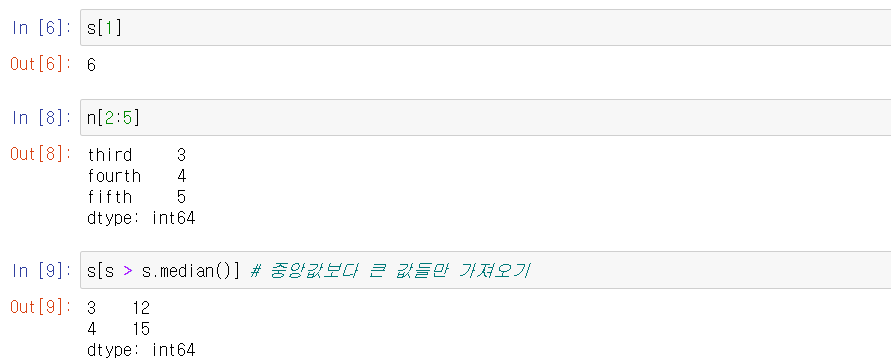
조건을 사용해서 값들을 가져올 수 있다.
-
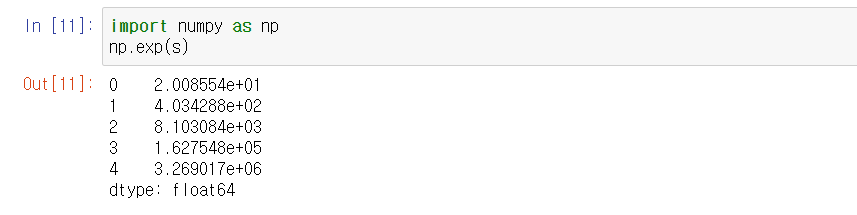
numpy의 함수를 Series에 사용할 수 있다.
Serise는 Python의 Dictionary와 상당히 유사한 모습을 보인다.
- Dictionary에서 사용했던 Key-Value 관계를 그대로 적용할 수 있다.
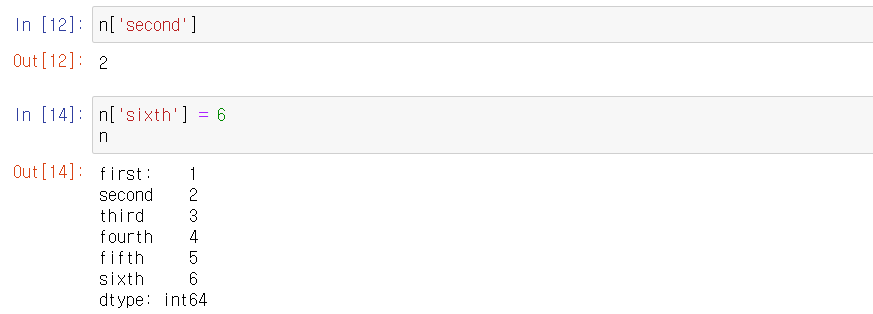
Dictionary에 값을 추가하듯이 사용할 수 있다.
- in을 사용하여 key가 있는지 확인 할 수 있다.
만약 Series에 없는 key에 접근하면 error가 발생하기 때문에 이를 방지하기 위해
.get()메서드를 사용하여 예외처리를 할 수 있다.

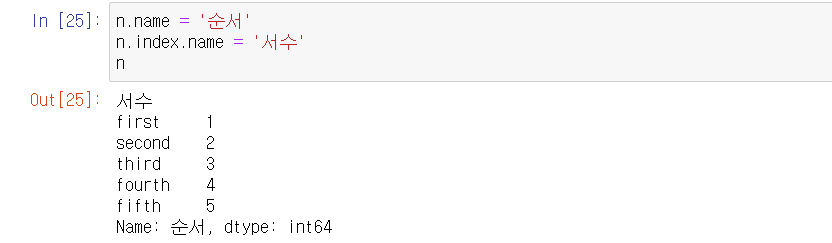
- Series의 이름과 Index의 이름을 지정할 수 있다.
DataFrame
- DataFrame은 2차원 데이터에 행, 영 모두에 인덱스를 붙인다고 볼 수 있다.
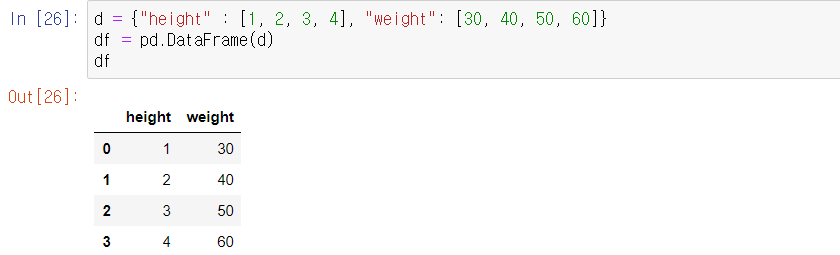
2차원 데이터를 다루기 위한 객체로 pd.DataFrame() 함수를 사용하여 생성한다.
Series와 마찬가지로 대문자 D와 F를 실수하지 않도록 조심하자.
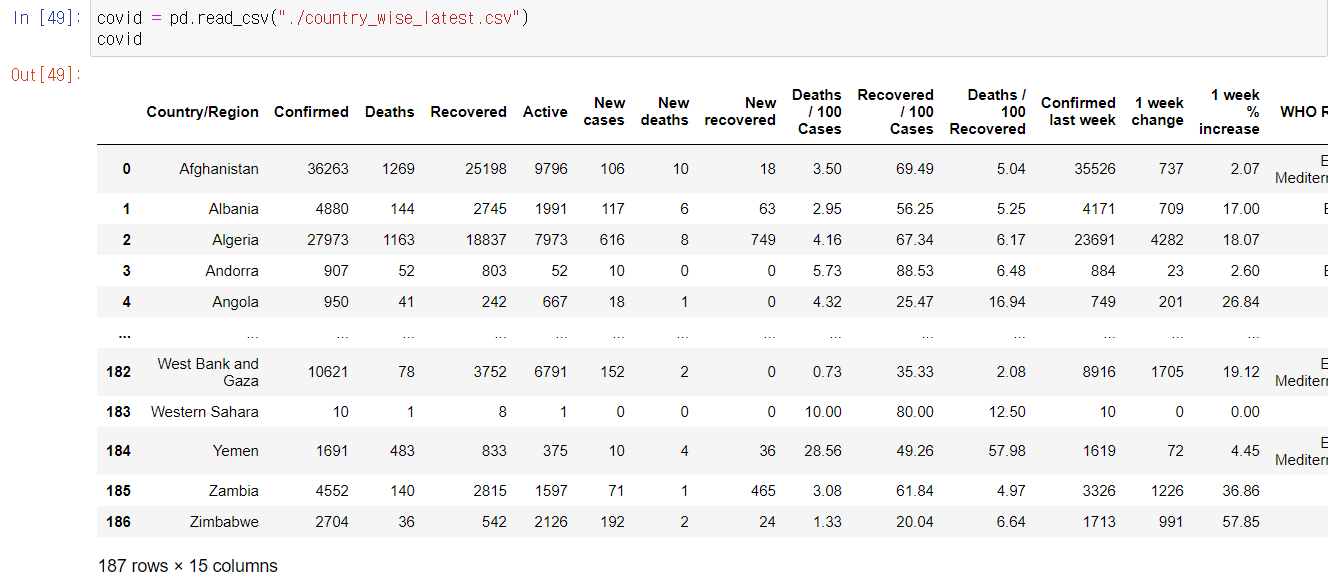
- pd.read_csv() 함수를 사용하여 csv파일을 DataFrame으로 생성할 수 있다.
일부분의 값들만 참조 하기.
- DataFrame 모든 값을 참조하기에는 양이 너무 많아 일부분의 값들만 참조하고자 하는 경우가 있을 것이다. 그럴 경우에는 특정 함수를 사용하여 해결할 수 있다.
head(n) : 처음 n개의 데이터를 참조
tail(n) : 마지막 n개의 데이터를 참조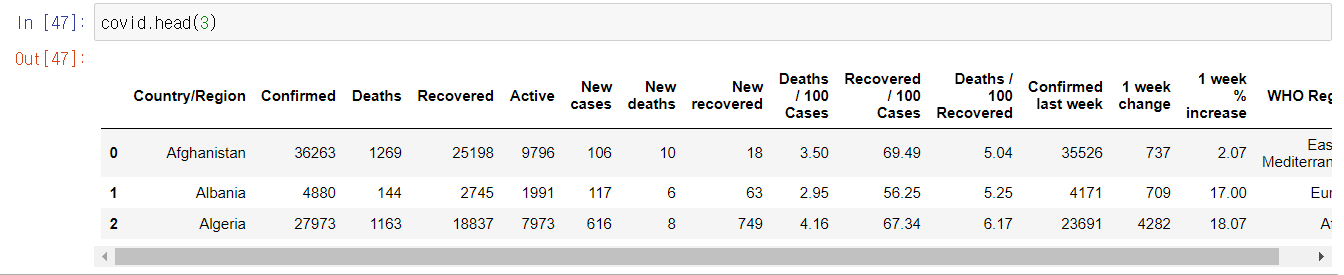
데이터 접근하기
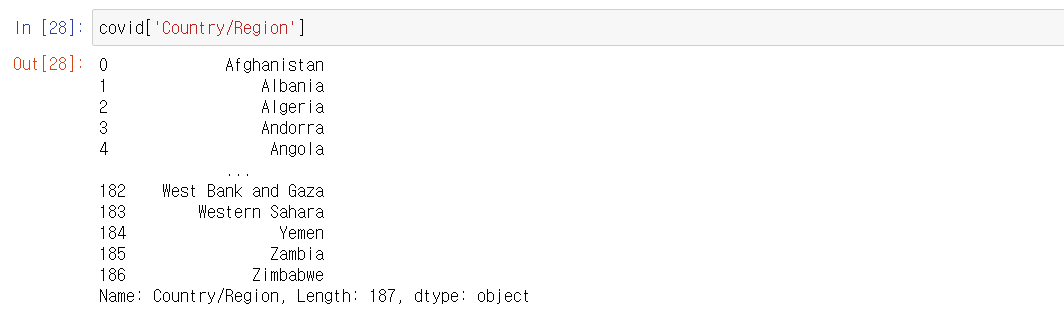
- DataFrame은 열 이름을 키로, 열 Series를 값으로 가지는 Dictionary 와 비슷하다고 볼 수 있다. 때문에 열 이름을 키값으로 하여 인덱싱 할 수 있다.
- df['column_name'] or df.column_name 두 가지 방법으로 인덱싱 할 수 있는데, 열 이름에 공백이 포함될 경우 df.column_name은 사용하지 못한다.
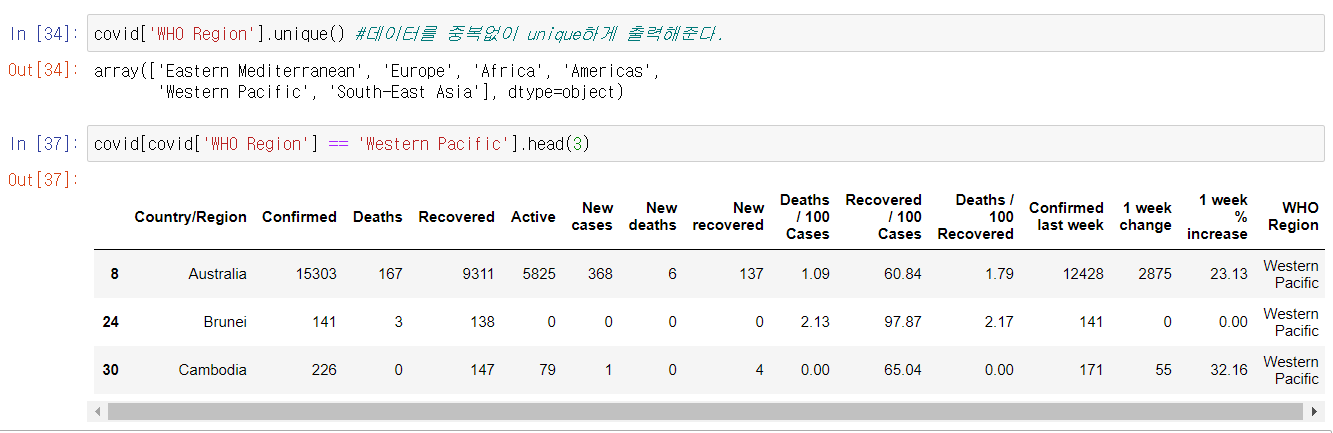
조건에 부합하는 데이터 추출하기
- 조건식을 사용하여 조건에 부합하는 data만을 추출할 수 있다.
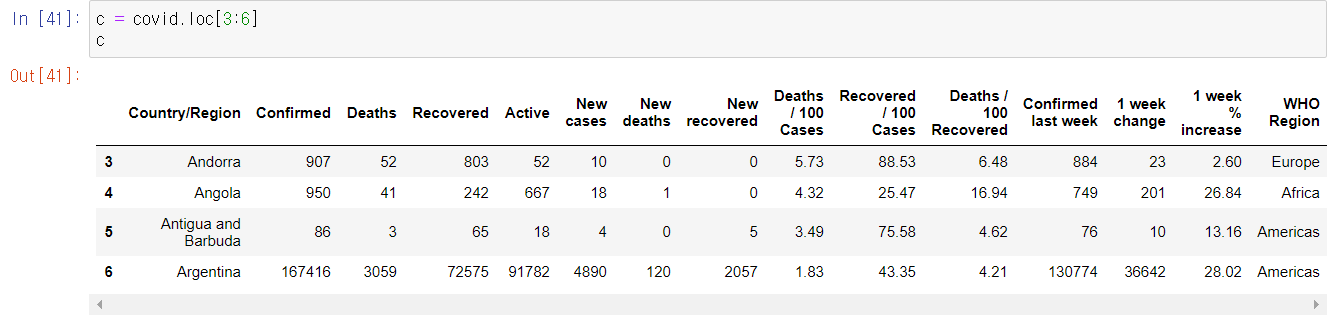
행 인덱싱
- 행 단위로 인덱싱을 하고자 한다면 index slicing을 사용할 수 있다.
인덱스를 이용해서 가져오기
- 데이터값을 가져올 때 숫자 인덱스를 이용해서 가져오거나, 이름을 이용해서 가져올 수 있다.
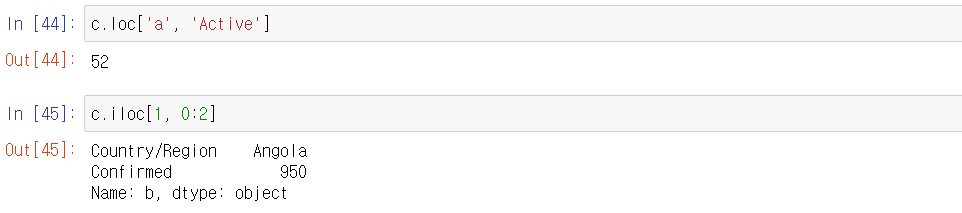
- 이름 인덱스 이용하기 .loc[row, col]
- 숫자 인덱스 이용하기 .iloc[rowidxm, colidx]
groupby 활용하기
- 특정한 기준을 바탕으로 DataFrame을 분할하고 통계함수 sum(), mean(), median()등을 적용해서 각 데이터를 압축한다.
그리고 적용된 결과를 바탕으로 새로운 Series를 생성해낸다.

Pandas의 Series와 DataFrame을 사용하는 방법에 대해 자세하게 알아보았다.
과거에 수치해석을 배우면서 pandas의 시각화 기능을 사용한적이 있는데, 기존에 알고있던 것보다 모르는게 더 많았던 시간이었다. 보다 자세한 데이터 처리 방법을 학습한 유익한 시간이었다.
