데이터셋 구성
훈련셋 중 일부를 검증셋으로 추출하고, 나머지 훈련셋을 이용하여 모델을 학습시키고, 매 에포크마다 검증셋으로 모델을 검증한다.
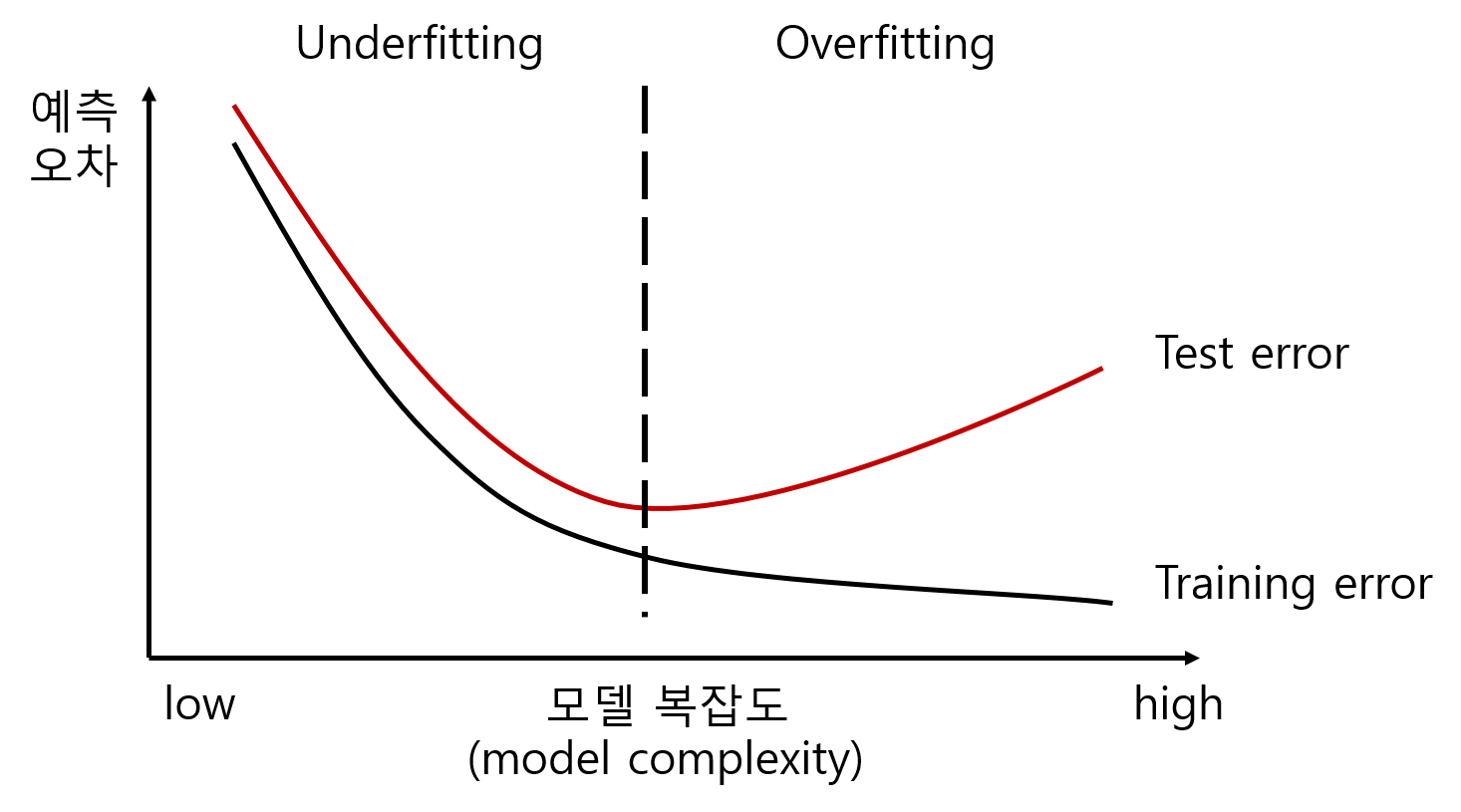
검증셋을 이용하여 데이터를 학습을 진행하다 보면, 검증셋에 과도하게 피팅되어 새로운 실제 데이터에 대해서는 오차값이 증가하는 현상이 발생하는데 이를 오버피팅 이라고 한다.
오버피팅(Overfitting)
오버피팅이란 머신러닝에서 데이터가 과하게 학습된 상태를 의미한다.
일반적으로 학습 데이타는 실제 데이타의 부분 집합이므로 학습데이타에 대해서는 오차가 감소하지만 실제 데이타에 대해서는 오차가 증가하게 된다.
오버피팅 방지하기
오버피팅을 방지하는 방법으로는 3가지 정도의 방법이 있다.
-
오버피팅이 되는 에포크를 확인하였다면, 오버피팅 전의 에포크 만큼 모델을 학습시킨다.
-
콜백함수를 사용하여, 오버피팅이 감지되면 조기 중단을 시킨다.
-
콜백함수를 사용하여, 매 에포크마다 검증셋의 손실값을 체크한 후, 이전 손실값보다 낮은 경우 모델을 파일로 저장한다.
1번의 방법은 2번의 학습을 해야하고, 2번의 방법은 학습이 더 진행될 수 있음에도 불구하고 설정조건에 의해 조기 중단될 수 있으므로, 3번의 방법을 사용하는것이 바람직하다.
