[논문리뷰] LLaVA: Large Language and Vision Assistant (Visual Instruction Tuning)
논문리뷰
Visual Instruction Tuning
Improved Baselines with Visual Instruction Tuning
0. 시작하기 앞서...
LLaVA는 출시 당시 가장 우수한 오픈소스 Vision-Language 모델이었다. 8개의 A100 서버랙으로 하루만 학습해도 충분했다. 그럼에도 불구하고 Training Recipe, Data mixture, Code를 모두를 공개하여 오픈소스 AI에 크게 기여했다.
1. Introduction
우리는 하나의 범용 AI를 만들고자 한다. 이를 위해서는 멀티모달 능력, 특히 시각적 및 언어적 지시를 잘 따르는 것이 중요하다.
한계점
하지만 이전 연구에는 다음과 같은 한계가 있었다:
범용 작업이 아닌 특정 작업들이 이미 모델의 설계 구조에 내재되어 있다. 따라서 모달리티 간 상호작용과 일반화 능력이 매우 부족하다.
NLP
NLP에서는 Alpaca나 Vicuna 같은 LLM들이 고품질의 지시를 따르는 샘플을 통해 미세 조정된다. 이를 통해 LLM이 더 나은 지시를 따르는 능력을 가지고 인간의 선호와 더욱 잘 맞춰진다.
이 논문에서는 이 NLP의 성공을 "Visual Instruction Tuning"을 통해 MLLM으로 확장하고자 하며, 이를 통해 컴퓨터 비전 능력을 가진 범용 AI에 한 걸음 더 다가가고자 한다.
연구 질문
이 논문은 "LM에 효과적인 것으로 입증된 instruction tuning 기법을 멀티모달 도메인(Image-Text)으로 어떻게 확장할 수 있는가?"라는 질문에 답하고자 한다.
4가지 기여
이 논문은 다음과 같은 네 가지 기여를 했다고 주장한다
1. Multimodal instruction-following data: GPT-4를 사용하여 Image-Text pairs를 적절한 instruction-following 형식으로 변환하는 파이프라인을 제시하였다
2. Large multimodal models: CLIP encoder + Vicuna Decoder
3. Multimodal instruction-following benchmark: LLaVA-Bench
4. Open-source
2. GPT-assisted Visual Instruction Data Generation

어떻게 multimodal instruction-following dataset을 만들었을까?
먼저, COCO 이미지 캡션 데이터를 사용했다. COCO 데이터셋은 기본적으로 입력으로 사용할 이미지와 그 이미지와 관련된 5개의 캡션을 제공한다. 또한 이미지 내 객체에 대한 바운딩 박스도 포함되어 있다.

이것이 우리가 COCO 데이터셋에서 사용할 수 있는 입력이다. 그러나 이것만으로는 Instruction-following dataset이 충분하지 않기 때문에, COCO dataset에서 얻은 이미지, Caption, BB를 이용하여 GPT-4(텍스트 전용)로 few-shot prompting을 통해 Conversation 58K, Detailed description 23K, complex reasoning 77K를 포함한 총 158K의 language-image instruction-following samples을 생성했다.
이떄 conversation dataset은 multi-turn(질문-답변이 여러번 반복되는)으로 생성되었다.
3. Visual Instruction Tuning
1. Architecture

LLaVA의 전체적인 아키텍처는 위와 같다.
LLaVA는 언어 모델로 Vicuna를 사용하며, Vision 인코더로는 CLIP ViT-L/14를 사용한다.
Language Instruction는 바로 Language model에 입력된다. 데이터셋의 입력과 출력은 다음과 같다.



시스템 메시지는 기존의 Vicuna-v0 시스템 메시지를 사용했다. 질문과 답변은 여러 쌍으로 구성되며, 손실은 초록색으로 표시된 답변 토큰에 대해서만 계산된다. 또한 이미지와 언어 지시의 순서는 무작위로 바뀔 수 있다. 개인적으로 이 부분이 매우 똑똑하다고 느꼈다. 실제로 LLM으로 코딩 같은 작업을 할 때 순서에 따라 답변의 퀄리티가 바뀌는 경우가 많기 때문에, 이를 방지하기 위해 순서를 랜덤하게 바꾸는 것은 좋은 아이디어인 것 같다.
대화의 두 번째 지시부터는 사진 없이 언어 지시만 입력으로 사용된다.
2. Training
Train의 두 부분으로 이루어진다.
1. Pre-training
2. Fine-tuning
Stage 1: Pre-training for Feature Alignment
Vision Encoder의 출력 벡터와 Language Model의 입력 벡터가 차원이 맞지 않거나 의미적으로 맞지 않을 수 있다. 이를 맞추기 위해 간단한 선형 Projection Matrix W를 추가하여 Feature Alignment 수행한다.

코드에서도 이를 확인할 수 있다.

그 후, Feature Alignment를 학습하기 위해 CC3M 데이터셋에서 595K 이미지-텍스트 쌍을 필터링하여 사용한다. 이 데이터셋에 instruction을 추가하여 single-turn 데이터 처럼 사용하고, Vision Encoder와 Language Model의 가중치를 고정한 상태에서 Projection Matrix W만을 학습한다.
Stage 2: Fine-tuning End-to-End
Vision Encoder의 가중치를 여전히 고정한 상태에서, 이전에 생성했던 158K insturctio-following samples를 사용하여 Projection W와 Language Model의 가중치를 업데이트한다. 논문에서는 Science QA에 대한 벤치마크를 위해 Science QA 데이터셋에 맞춰 fine-tuning도 실시했다.
4. Experiments
Multimodal Chatbot

사진에서 보듯이 LLaVA는 꽤나 대답을 잘하는 것을 알 수 있다.
Quantitative Evaluation

GPT-4(텍스트 전용)가 생성한 결과와 LLaVA가 생성한 결과를 GPT-4가 어느 것을 선호하는지 테스트해본 결과, LLaVA는 85.1%의 선호도를 얻었다. 이는 Instruction Tuning을 하지 않았을 때의 21.5%와 비교해 4배 가까운 성과이다.
또한, 모든 데이터셋을 활용했을 때 최고 점수를 흭득했다.
Limitation

위 사진에서 딸기맛 요거트가 없음에도 불구하고 LLaVA는 딸기와 요거트를 패치들의 단순한 집합으로 인식해 딸기맛 요거트가 있다고 잘못 답변했다. 이는 데이터셋에 이러한 유형의 사진이 없었기 때문이다. 저자는 더 복잡한 의미를 이해할 수 있는 Language-Visual 모델 개발이 필요하다고 말한다.
ScienceQA
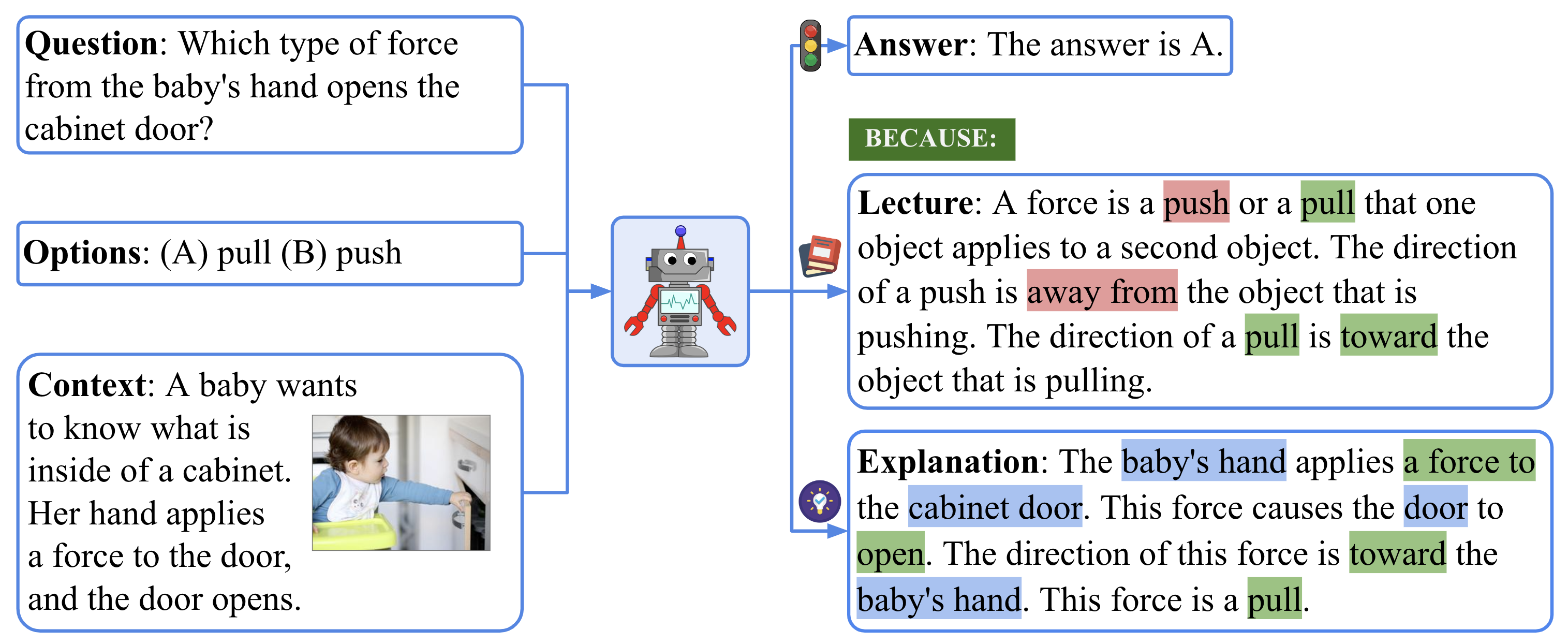
ScienceQA는 위와 같은 간단한 과학 지식을 묻는 벤치마크이다.

ScienceQA에서도 LLaVA는 좋은 성적을 거두었으며, LLaVA + GPT-4(Judge)를 사용한 벤치마크에서는 이전 SOTA(MM-CoT Large)를 뛰어넘는 성능을 기록했다.
LLaVA + GPT-4(Judge): LLaVA와 GPT-4가 각각 생성하고 GPT-4가 결과물 중 하나를 선택
5. Conclusion
이 논문은 Visual Instruction Tuning이 매우 유용함을 보여주었다. 또한 자동으로 Image-Text pairs Instruction-following dataset을 생성하는 방법을 제시했다. 이를 통해 LLaVA를 학습시켜 일부 분야에서 SOTA를 달성했다. 또한 Vision Encoder와 Language Model을 단순한 Project Layer 연결하는 혁신적인 아이디어를 처음 제시한 논문이다.
6. Improved Baselines with Visual Instruction Tuning

LLaVA 1.0의 다음 버전인 LLaVA 1.5는 무려 11개의 벤치마크에서 SOTA를 달성했다. 이 놀라운 성과가 어떻게 이루어졌는지 간단히 살펴보자.
Architecture 관점

Vision 인코더를 CLIP ViT-L/336px로 변경하여, 기존 ViT-L/14의 224px보다 더 높은 해상도를 처리할 수 있게 되어 이미지에서 더 많은 정보를 얻을 수 있었다.

또한 단일 선형 레이어를 MLP(2층)로 변경했다.
마지막으로 Language model를 Vicuna v0 7B에서 더 큰 크기와 데이터셋으로 미세 조정된 Vicuna v1.5 13B로 업그레이드했다.
Response Format Prompting

기존 VQA 데이터셋에 "Answer the question using a single word or phrase."와 같은 프롬프트를 추가하여 ChatGPT 없이도 instruction-following 데이터셋을 만들 수 있었다.
결과 분석

논문에서는 LLaVA가 성능 향상을 어떻게 이루었는지 위와 같은 표로 설명하고 있다. 이 표를 보면 대부분의 성능 향상이 VQA 같은 "데이터"에서 왔음을 알 수 있다. 이는 아키텍처 변경보다도 데이터셋이 얼마나 중요한지를 보여준다.

LLaVA-1.5 7B 모델은 80B IDEFICS와 같은 Flamigo-like LMM의 성능을 뛰어넘었으며, 이는 Vision 인코더와 관계없이 단순한 Projection Layer만 훈련하여 Flamigo 같은 복잡한 작업 없이 더 나은 성능의 Vision-Language 모델을 얻을 수 있음을 시사한다.


또한 LLaVA 1.5는 까다로운 질문에 대해 "없다"라고 답하거나 JSON 출력 능력도 향상되었다.
