Adaptive Chameleon or Stubborn Sloth: Unraveling the Behavior of Large Language Models in Knowledge Clashes
hallucination-lm
목록 보기
4/6
분야 및 배경지식

- parameteric memory
- 언어모델이 사전학습 시 거대한 코퍼스를 통해 학습하는 지식을 의미
- 모델은 factual, linguistic 등 다양한 종류의 지식을 저장하고 있다고 알려짐
- 하지만 지식이 outdated, incorrect일 확률 또한 존재
- external evidence
- external knowledge, context 등으로 지칭되기도 함
- 언어모델이 추론을 진행할 때 추가적으로 제공되는 외부의 지식을 의미
- 특히 parameteric memory와 상충하는 외부적 지식은 counter memory라고 칭함
문제점
- 파라미터에 저장된 지식과 외부적으로 제공된 지식이 상충할 때, 거대한 언어모델(=LLM)이 어떻게 작동하는지에 대한 통합적인 분석 미비
- 기존의 knowledge conflict에 대한 연구들은 단순한 방식으로 counter memory를 생성
- 예를 들어, 기존 연구들은 단순히 개체명을 변경하거나 긍정을 부정으로 바꾸는 방식을 활용
해결책 (분석)
knowledge conflict construction
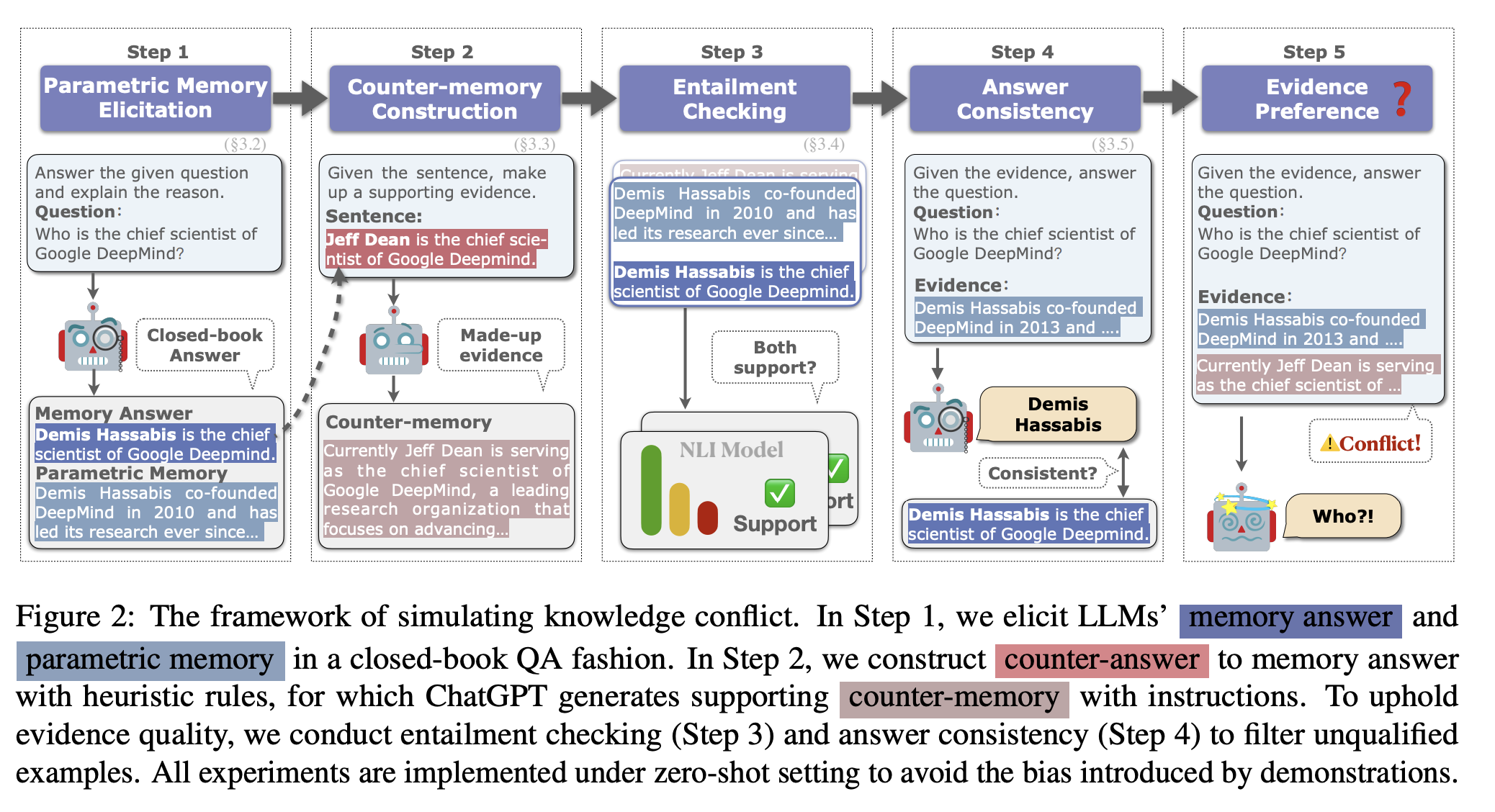
- closed-book QA 방식을 활용해 모델로 하여금 parametric memory를 도출 (step 1)
- parametric memory와는 다른 counter memory를 생성
- 개체명 변경, 부정 삽입 등의 heuristic을 이용
- 이를 지지할 수 있는 증거를 언어 모델로 하여금 생성하도록 함 (step 2)
- NLI 모델을 통해 생성된 증거가 정답을 포함하고 있는지(=entailment) 확인 (step 3)
- parametric memory를 모델에게 evidence로 제공했을 때 closed-book QA 방식과 동일한 답변을 생성하는지 일관성 확인 (step 4)
evaluation
- 외부 지식에 수용적 (receptive)
- 외부 지식이 일관성 있고 신빙성 있을 경우
- 파라미터에 저장된 지식과 다를지라도 외부 지식을 신뢰
- 파라미터에 저장된 지식과 일치하는 정보를 신뢰 (확증 편향; confirmation bias)
- 여러 개의 외부 지식이 상충할 경우 발생
- 유명한(popular) 개체들에 대한 질문일 경우 발생 (single-source, multi-source 무관)
- ChatGPT보다 GPT-4가 parametric memory에 더욱 의존적
- 제공된 지식들(=evidence)의 순서에 따라 LLM의 답변이 달라짐
- 길이가 긴 counter memory를 더욱 신뢰
- parametric memory는 길이와 무관
평가
- 데이터셋
- PopQA: 개체 기반 QA 데이터셋
- StrategyQA: multi-step reasoning 데이터셋
- 자유 형식의 QA를 다지선다 QA 형식으로 변경
- 평가기준
- memorization ratio
- f_m / (f_m + f_e)
- f_m: parametric memory의 정답 빈도수
- f_e: counter memory의 정답 빈도수
- 높을수록 LLM이 parametric memory에 더 의존한다는 것을 의미
- memorization ratio
의의
- 거대한 언어모델(=LLM)의 Knowledge conflict에 대한 첫번째 통합적 연구
- LLM을 활용해서 일관성 있는 counter memory를 생성하고자 함
한계
- 다지선다에서 정답을 고르는 문제의 경우 선택지의 순서에 따라 정답이 달라질 수 있음
- Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions (link), arXiv 2023
- 분석의 결과가 오직 counter memory, parametric memory의 영향이라고는 볼 수 없음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab