A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation
hallucination-lm
목록 보기
3/6
A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation
ACL 2022
분야 및 배경지식
- hallucination (환각; 그럴듯한 거짓말)
- 거대한 사전학습 생성형 언어모델이 가지고 있는 주요 문제 중 하나
- 존재하지 않거나 정확하지 않은 내용을 모델이 마치 사실처럼 응답하는 문제
문제점
- 기존 hallucination 감지 연구들의 한계
- 참조(reference) 기반
- 정답 역할을 하는(ground-truth) 참고(reference) 자료가 존재하지 않을 수 있음
- 참고 자료를 어디에서 가져올지 정하는 것 또한 어려움
- 실시간으로 생성이 이루어지는 경우 기존의 참고 자료만 사용 가능
- 정답 역할을 하는(ground-truth) 참고(reference) 자료가 존재하지 않을 수 있음
- 문장 혹은 문서 기반
- 실시간으로 잘못된 내용을 방지할 수 있는 세세한 시그널을 주는 데에 실패할 수 있음
- 어느 부분이 hallucination인지를 파악하기보다 생성된 문장 혹은 문서 전체에 대한 hallucination 여부만 파악 가능
- 실시간으로 잘못된 내용을 방지할 수 있는 세세한 시그널을 주는 데에 실패할 수 있음
- 참조(reference) 기반
해결책
참조가 필요없는(reference-free) 토큰 단위 감지 태스크

- hallucination인지 아닌지를 판단하는 이진 분류 태스크
- 오프라인 세팅
- 생성이 완료되어 양쪽의(bidirectional) 문맥을 모두 사용 가능
- 온라인 세팅
- 이전의(unidirectional) 문맥만 접근 가능
HADES (HAllucination DEtection dataSet)
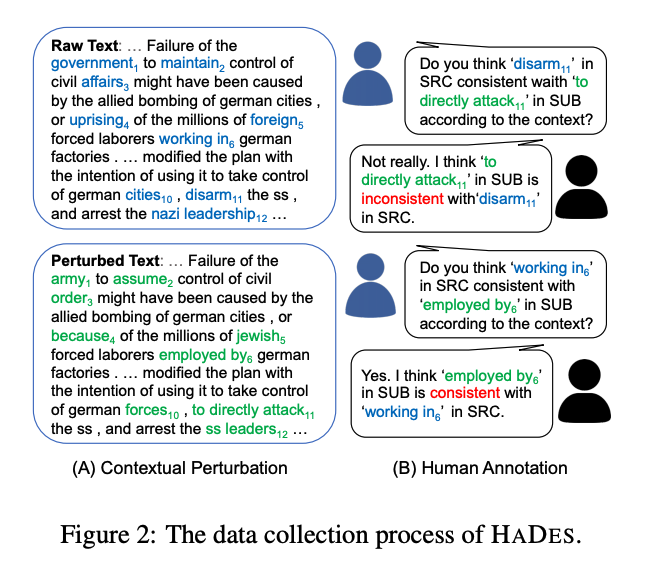
- 원시 데이터 수집
- 영어 WIKI-40B 활용
- 문맥에 작은 변화(perturbation) 주기
- 유창성(fluency)과 구문적(syntactic) 정확성, 어휘적(lexical) 다양성을 유지하면서 내용 변화
- MASK: 일부 단어를 [MASK] 토큰으로 가리기
- REPLACE: top-k sampling 이용해 BERT로 하여금 [MASK] 토큰 예측 및 치환하도록
- RANK: GPT-2를 활용해 perplexity가 낮은 후보군만 유지
- 데이터 주석(annotation)
- human annotation
- 전체 데이터 중 상대적으로 유용하고, 균형잡힌 분포를 가진 데이터들 일부에 대해서 진행
- 여러 명이 합의에 도달할 경우에 데이터 유지
- iterative model-in-the-loop annotation
- 비교적 명확하게 분류되는(more trivial) 데이터의 경우 사람이 주석을 달 필요가 없음
- 감지 모델이 낮거나 높은 확률을 부여하거나, 원래의 문맥과 유사도가 높거나, 날짜나 이름을 치환하는 등 명백한 hallucination인 경우 제외
- 또한 레이블 사이의 분포가 균형잡히게끔 샘플링 진행 (H/N = 54.5%/45.5%)
- human annotation
평가
- 데이터셋
- hallucination은 더 높은 엔트로피와 연관되는 경우가 많음
- hallucination은 사실적으로 일관된 내용보다 더 높은 평균 확률을 보임
- 모델이 과하게 확신하는 생성 결과가 hallucination에 빠질 가능성이 높음
- 모델
- 피처 기반 모델
- 로지스틱 회귀, 서포트 벡터 머신
- 트랜스포머 기반 모델
- BERT, GPT-2, XLNet, RoBERTa
- 피처 기반 모델
- 평가기준
- accuracy, precision, recall, F1, AUC, G-Mean, Brier Skill Score
- 결과
- 오프라인 세팅에서 모든 모델이 더 좋은 성능을 보임
- 사전학습 모델이 피처 기반 모델보다 훨씬 좋은 성능을 보임
- GPT-2가 전반적으로 가장 우수한 성능
- 오프라인 세팅에서 모든 모델이 더 좋은 성능을 보임
한계
- perturbation을 통해 만든 hallucination 데이터셋이 과연 모델의 hallucination을 얼마나 잘 모사하는지 의문이 듦
- 특히 perturbation 시 GPT 기반의 생성형 언어모델이 아니라 BERT를 사용했다는 점에서 한계 존재
의의
- 기존의 hallucination 감지 태스크와는 다른 새로운 형태의 태스크를 제시하였으며, 그에 걸맞는 벤치마크를 생성

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab
유익한 글이었습니다.