사전지식: RAG란
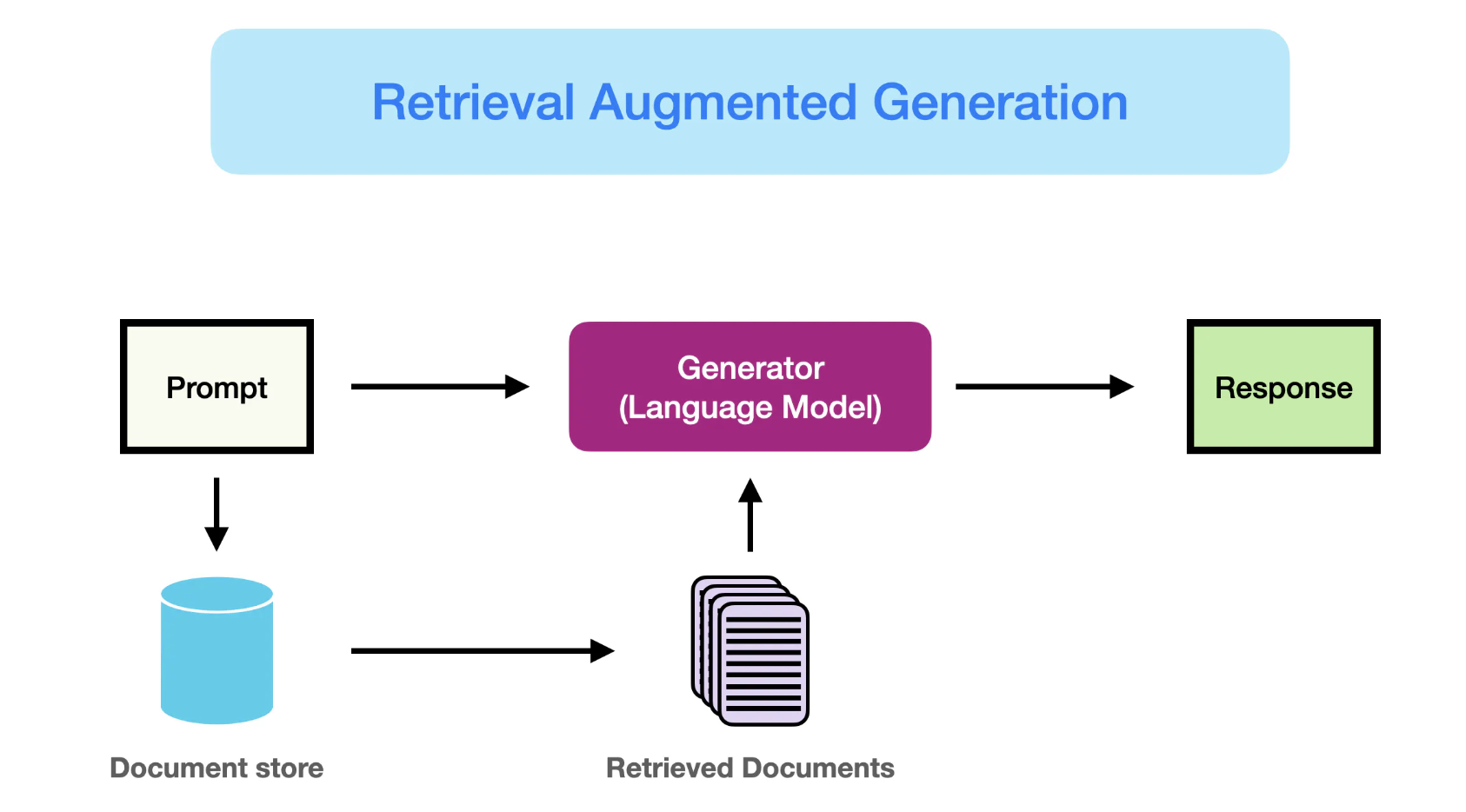
- RAG란 Retrieval-Augmented Generation의 약자
- 언어모델에게 질의할 때 외부에서 가져온 데이터를 결합하여, 언어모델이 더욱 정확한 답변을 생성하도록 하는 방법론
- RAG 활용 시나리오 (간단한 예시)
- 사용자가 언어모델에 질문(prompt)을 던짐 ("여권 재발급 시에 챙겨야 할 서류가 뭐야?")
- 사용자의 질문을 임베딩 벡터로 변환하여, 사전에 임베딩 벡터로 저장된 문서들 중에 가장 유사도가 높은 문서들을 반환함
- 사용자의 질문과 해당 문서들을 결합해 언어모델로 하여금 답변을 생성하도록 함
- RAG가 해결할 수 있는 문제
- 언어모델이 학습한 데이터가 오래되어(outdated) 부정확한 답변을 생성하는 경우 방지
- 언어모델이 그럴듯한 거짓말을 생성하는 환각(hallucination) 현상 완화 가능
Advanced RAG
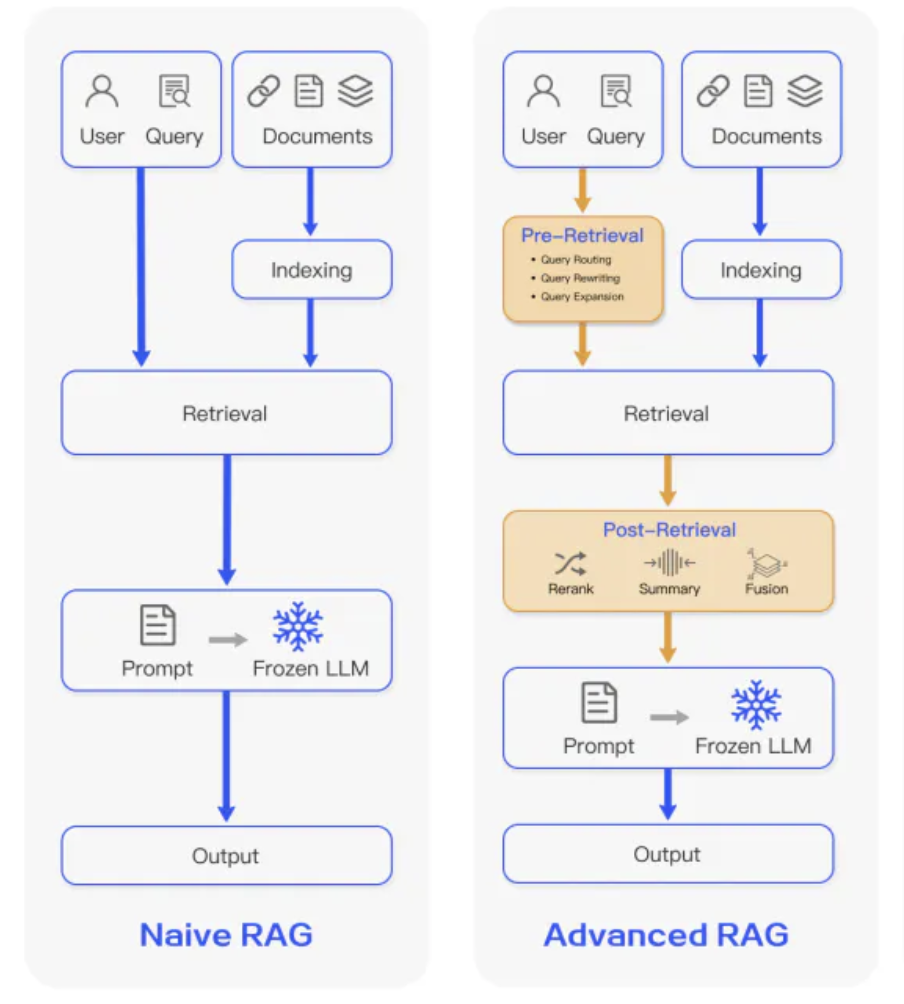
- 하지만 외부에서 데이터를 가져온다고 할 때, 어떤 문서를 가져와 프롬프트와 결합시키느냐에 따라 RAG의 성능이 좌우될 수 있음
- 최근 Advanced RAG는 문서 검색(회수; Retrieval)의 성능을 향상시키기 위해 다양한 방법을 고안
검색 전
- 문서 인덱싱 성능 향상
- 문서 인덱싱이란, 추후 문서의 검색을 용이하게 하기 위해 문서에 일종의 책갈피를 달아뒀다고 이해할 수 있음
- 이를 더욱 효율적으로 하기 위해 데이터의 세부 정도(granularity)를 조정하고, 인덱스 구조를 최적화하고, 메타데이터를 추가하는 등의 최적화 기법을 도입
- 사용자 쿼리 수정
- 사용자의 쿼리를 재작성하거나 확장시켜 관련 문서를 더욱 잘 검색할 수 있도록 변경
검색 후
- 언어모델이 받아들일 수 있는 글자의 수(context window)가 제한적이기 때문에 이를 고려해야 함
- 잡음이 많고 혼란을 줄 수 있는 정보들을 제거해야 함
- Reranking
- 관련도가 높은 문맥을 프롬프트 근처로 위치시킬 수 있음 (위치 변경)
- 관련 문맥의 존재 유무가 아닌 순서가 모델 답변 성능 향상에 중요하다는 사실이 밝혀짐
- 사용자 쿼리와 관련 문맥들 사이의 의미론적 유사성을 재탐색
- 관련도가 높은 문맥을 프롬프트 근처로 위치시킬 수 있음 (위치 변경)
- Prompt compression
- 프롬프트 압축과 관련해서 이전에 작성한 LLMLingua에 관한 설명 참고 가능 (link)
ReRanker
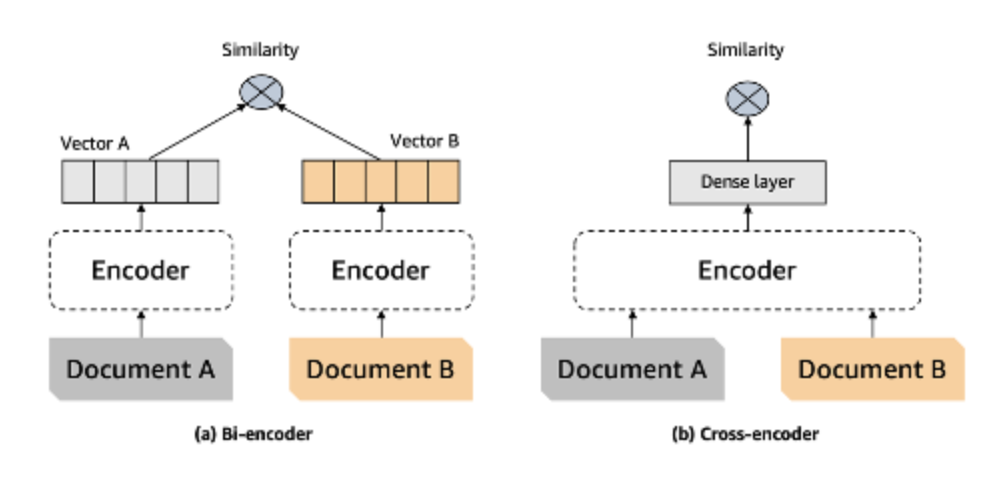
- 질문과 문서 사이의 유사도를 측정할 때 질문과 문서를 하나의 인풋으로 사용
- 일반적인 벡터 검색이 활용하는 Bi-encoder가 아닌 Cross-encoder 구조를 활용함으로써 더욱 정확한 유사도 측정이 가능
- 하지만 Cross-encoder는 모든 조합들을 활용해 인풋으로 활용해야 하기 때문에, 비용이 높음
- 때문에 일반적인 벡터 검색(retrieval)을 진행한 후, reranker 기반으로 순위를 재정렬하는 경우가 일반적
llamaindex에서 제공하는 reranker 목록
CohereReRank
from llama_index.postprocessor.cohere_rerank import CohereRerank
postprocessor = CohereRerank(
top_n=2, model="rerank-english-v2.0", api_key="YOUR COHERE API KEY"
)
postprocessor.postprocess_nodes(nodes)SentenceTransformerRerank
- cross-encoder를 활용한 reranker
from llama_index.core.postprocessor import SentenceTransformerRerank
# We choose a model with relatively high speed and decent accuracy.
postprocessor = SentenceTransformerRerank(
model="cross-encoder/ms-marco-MiniLM-L-2-v2", top_n=3
)
postprocessor.postprocess_nodes(nodes)LLM Rerank
- 거대언어모델을 활용한 reranker
from llama_index.core.postprocessor import LLMRerank
postprocessor = LLMRerank(top_n=2, service_context=service_context)
postprocessor.postprocess_nodes(nodes)JinaRerank
from llama_index.postprocessor.jinaai_rerank import JinaRerank
postprocessor = JinaRerank(
top_n=2, model="jina-reranker-v1-base-en", api_key="YOUR JINA API KEY"
)
postprocessor.postprocess_nodes(nodes)Colbert Reranker
from llama_index.postprocessor.colbert_rerank import ColbertRerank
colbert_reranker = ColbertRerank(
top_n=5,
model="colbert-ir/colbertv2.0",
tokenizer="colbert-ir/colbertv2.0",
keep_retrieval_score=True,
)
query_engine = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[colbert_reranker],
)
response = query_engine.query(
query_str,
)rankLLM
from llama_index.postprocessor import RankLLMRerank
postprocessor = RankLLMRerank(top_n=5, model="zephyr")
postprocessor.postprocess_nodes(nodes)참고자료

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab