배경지식
- 프롬프트
- 언어모델로부터 응답을 얻기 위해 사용되는 인풋
- 설명(instruction), 예시(demonstration), 질문 등 다양한 구성요소로 이루어짐
- 인컨텍스트 학습 (in-context learning)
- 언어모델의 인풋에 다양한 예시 등을 제공함으로써 모델이 해당 문맥(context)을 활용해 특정 태스크를 해결할 수 있도록 하는 방법
- 파인튜닝(fine-tuning)과 다르게 모델의 파라미터를 수정하지 않음
- chain-of-thought 프롬프팅
- 언어모델로 하여금 답변을 할 때 일련의 생각 과정을 유도함으로써 더욱 정확한 답변을 얻어낼 수 있는, 단순하지만 효과적인 프롬프팅 기법
- 인스트럭션 튜닝 (instruction tuning)
- 언어모델이 사람의 질문을 잘 이해하고 대답할 수 있도록, 설명(instruction)이 주어지면 적절하게 대답할 수 있도록 학습하는 방법
- 최근 등장한 언어모델은 이를 위해 데이터셋을 만들 때 특정한 템플릿을 따르라고 안내
문제점
- 최근 좋은 성능을 위해 언어모델에 들어가는 프롬프트의 길이를 늘리는 추세
- 인컨텍스트 학습과 chain-of-thought 프롬프팅 등의 기법은 언어모델에 들어가는 프롬프트의 길이를 늘림
- 하지만 긴 프롬프트는 모델의 추론 속도를 저하시키고 더 큰 비용을 야기
해결책
LLMLingua (EMNLP 2023)
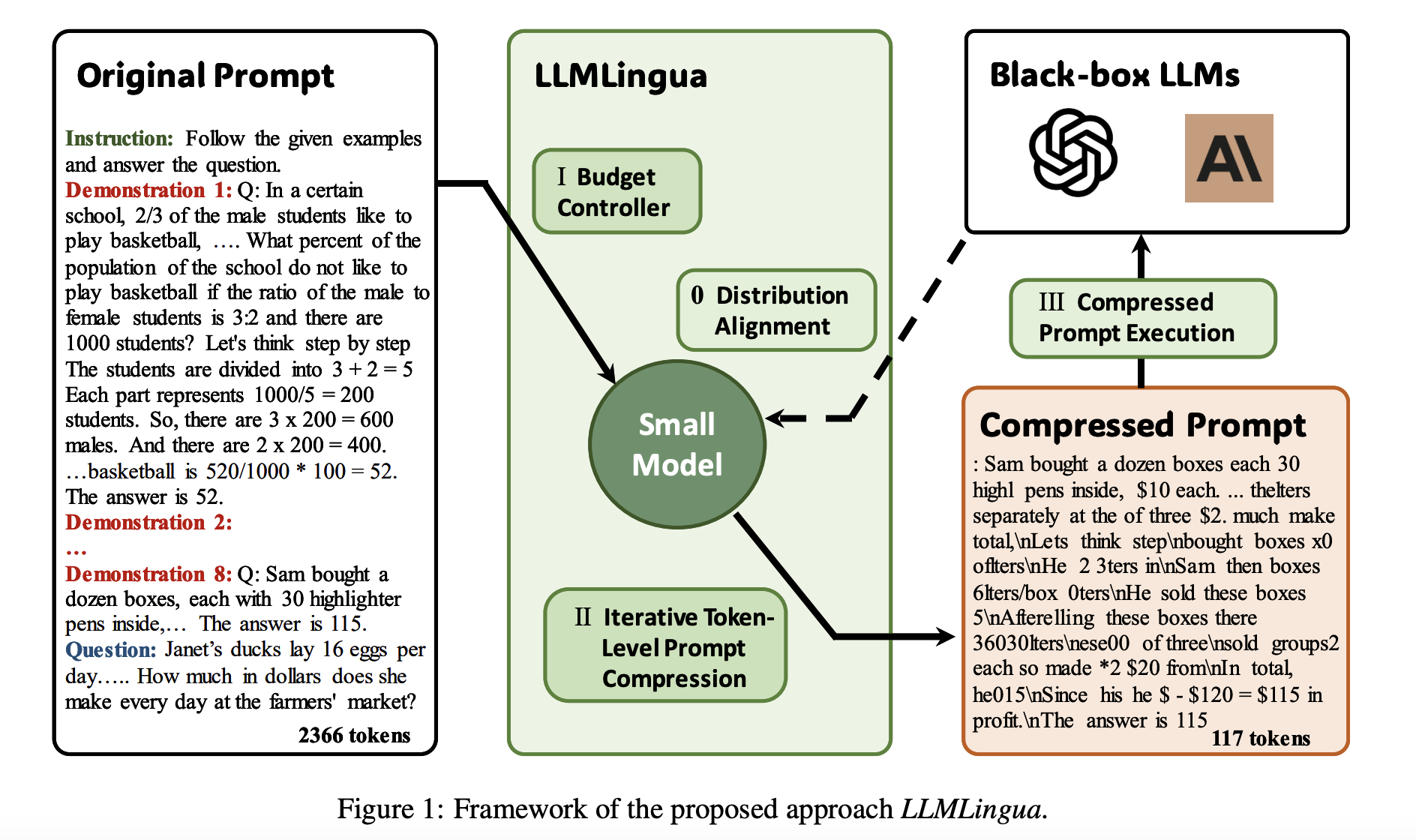
- 잘 훈련된 작은 언어모델을 활용하여 프롬프트의 길이를 효과적으로 줄이는 방법론
- 예산 조절 (budget controller)
- 원래 프롬프트에 존재하는 다양한 구성요소에 각기 다른 압축률을 동적으로 할당
- 프롬프트의 기존 의미는 유지하면서도 최대한 압축할 수 있도록
- 일반적으로 예시에는 더 높은 압축률을, 설명과 질문에는 더 낮은 압축률을 부여
- perplexity를 계산하여 어떤 정보가 더욱 중요한지를 파악
- 토큰 단위 반복 알고리즘 (token-level iterative algorithm)
- 토큰들 사이의 조건부 의존성을 고려함으로써 더욱 정교하게 프롬프트를 압축
- 각 구간마다 조건부 확률을 계산하고 압축 시 임계값을 지정
- 추가적인 인스트럭션 튜닝 방법론 (instruction tuning)
- 프롬프트를 사용할 거대한 언어모델과 프롬프트 압축에 사용하는 작은 언어모델은 분포 간 불일치 (distribution discrepancy)가 존재
- 이를 줄일 수 있는 추가적인 방법론 또한 제시
LongLLMLingua (ICLR ME-FoMo 2024)
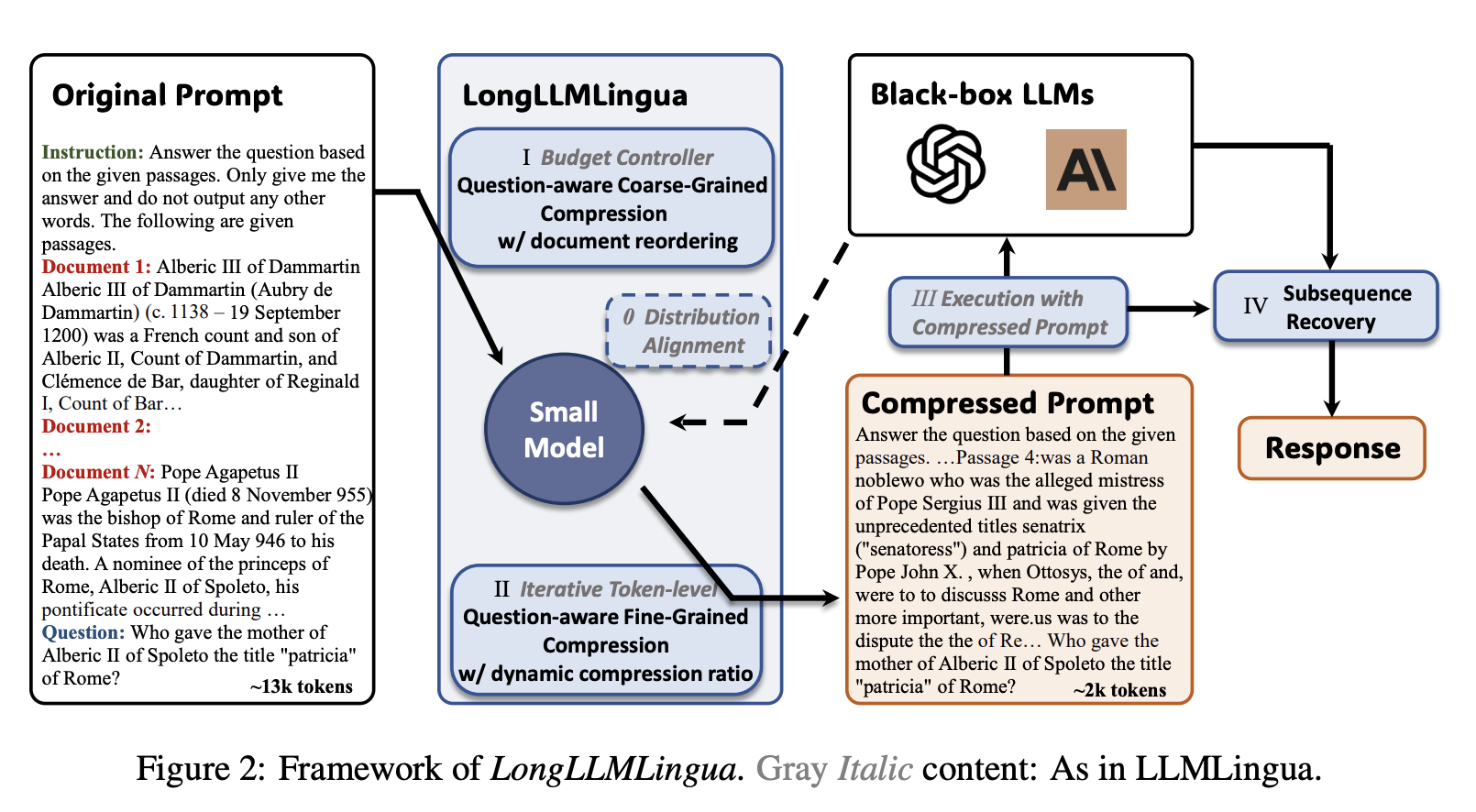
- 질문과 연관성이 높은 중요 정보들이 생략되지 않도록 기존 방법론을 보강
- 문맥에 기반한(conditioned on) 질문의 perplexity를 계산함으로써 질문과 문맥 사이의 관계를 파악
- LLMLingua는 문서 차원에서 perplexity를 계산
- 또한 contrastive perplexity를 사용해 토큰 단위로 압축을 진행할 때 해당 토큰과 질문 사이의 관계를 고려
- 문맥에 기반한(conditioned on) 질문의 perplexity를 계산함으로써 질문과 문맥 사이의 관계를 파악
- 거대언어모델이 긴 문맥을 가진 정보를 처리할 때 중간의 정보가 사라지는 현상을 완화
- 질문에 따른 문서의 중요도 점수를 바탕으로 문서의 순서를 재편
- 후속 복구 방법
- 언어모델의 응답과 기존의 프롬프트, 압축된 프롬프트의 토큰 사이의 관계를 활용해 본래의 내용을 복구
- 응답의 정확도를 높일 수 있음
- 1/4의 토큰을 사용하여 RAG 성능을 약 21.4% 향상
LLMLingua-2 (under review, 2024)
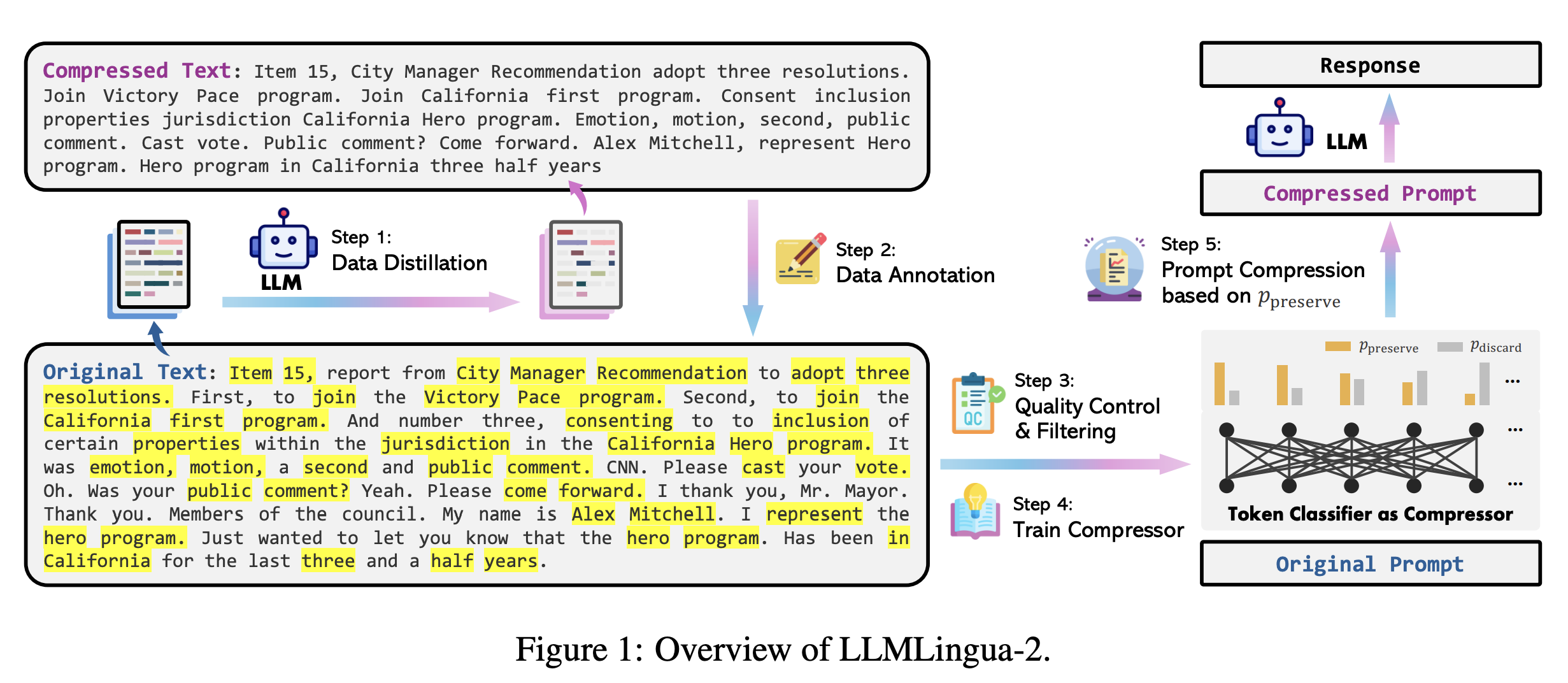
- 거대언어모델을 활용한 데이터 증류 (data distillation)
- GPT-4와 같은 거대한 언어모델이 가진, 중요한 정보를 잃지 않고 프롬프트를 압축하는 지식을 가져와 데이터 증류 절차에 활용
- 본래의 텍스트와 압축된 형태의 텍스트 쌍을 포함한 데이터셋 제공
- 프롬프트 압축 문제를 토큰 분류 태스크로 접근
- 각 토큰을 보존 혹은 삭제 레이블로 분류
- 특징을 추출하는 트랜스포머 인코더 모델을 활용해 양방향의 문맥을 모두 활용해 프롬프트를 압축
- 작은 모델을 활용해 latency를 줄임
- 압축된 프롬프트가 원래의 문맥에 충실함을 보장할 수 있음
코드
- pip install을 통해 LLMLingua를 설치하고, 쉽게 프롬프트 압축을 진행할 수 있음
- 더욱 자세한 예시는 LLMLingua의 깃헙을 참고 (글 하단 링크 참고)
pip install llmlinguaLLMLingua
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
# llm_lingua = PromptCompressor("microsoft/phi-2") # phi-2 모델을 사용하거나
# llm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"}) # LLaMA-2-7B 기반 모델 또한 사용 가능
compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)LongLLMLingua
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(
prompt_list,
question=question,
ratio=0.55,
# 아래는 LongLLMLingia를 위한 특별한 파라미터들
condition_in_question="after_condition",
reorder_context="sort",
dynamic_context_compression_ratio=0.3, # or 0.4
condition_compare=True,
context_budget="+100",
rank_method="longllmlingua",
)LLMLingua-2
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-xlm-roberta-large-meetingbank",
use_llmlingua2=True, # llmlingua-2를 사용할 지 결정
)
compressed_prompt = llm_lingua.compress_prompt(prompt, rate=0.33, force_tokens = ['\n', '?'])
## LLMLingua-2의 작은 모델 버전을 사용할 수도 있음
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank",
use_llmlingua2=True, # llmlingua-2를 사용할 지 결정
)참고 링크
- LLMLingua github
- LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models (EMNLP 2023, link)
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression (ICLR ME-FoMo 2024, link)
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression (2024, link)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab