배경지식
- 문맥 적응 (context adaption)
- 지시사항(instruction), 전략, 증거 등을 활용해 입력 데이터를 수정하는 방법
- 모델의 파라미터(가중치)를 직접 업데이트하는 post-training 등과는 구분됨
- context는 해석이 쉽다는 점, 새로운 지식을 빠르게 통합할 수 있다는 점이 장점으로 꼽힘
- 최근 긴 컨텍스트 길이를 가진 LLM과 문맥 효율적인 추론(e.g. KV cache reuse) 등 기술적 성숙을 통해 해당 방법론의 적용이 더욱 용이해짐
문제점
- context adaption은 크게 두 가지 한계를 가짐
- 단순함 편향 (brevity bias)
- 프롬프트를 최적화할 시 종합적인 누적보다는 명료성과 단순함을 선호
- 도메인 특화된 세부사항을 누락하고 거의 동일한 지시사항을 반복적으로 생성하게 됨
- 문맥 붕괴 (context collapse)
- 전체 내용의(monolithic) 재작성으로 인해 누적된 유용한 정보가 누락되는 경우가 빈번
해결책
Agentic Context Engineering

- 문맥(context)이 명료한 요약이 아니라, 종합적이고, 진화하는 playbook으로써의 역할을 해야 함
- 자세하고, 포괄적이고, 도메인 관련 정보가 풍부해야 함
- 오프라인(e.g. 시스템 프롬프트 최적화), 온라인(e.g. test-time memory adaptation) 환경을 모두 지원하는 프레임워크로 기능
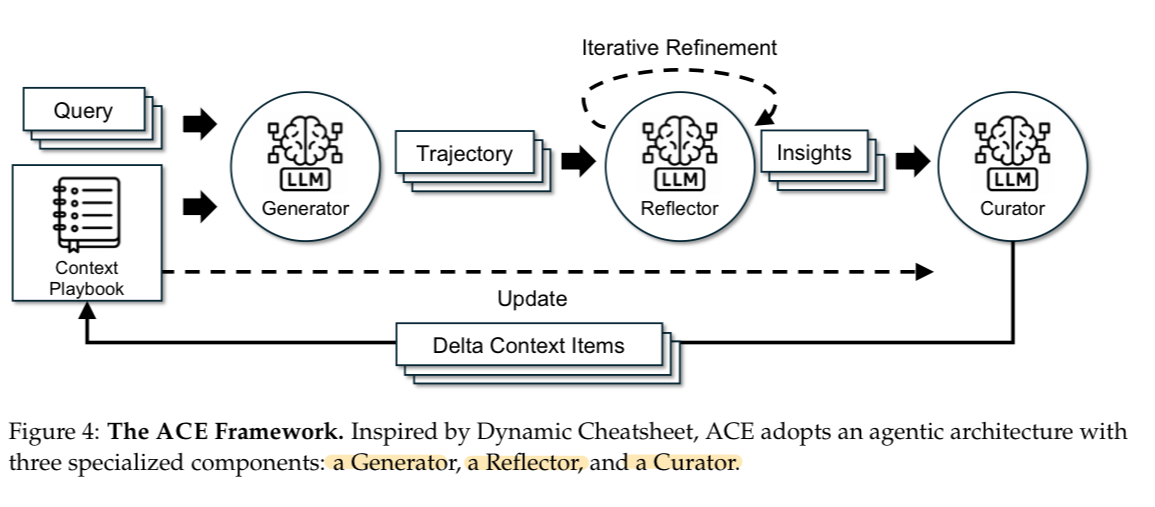
- 세 가지 중요한 혁신을 통해 위에서 언급한 문제점을 해결했다고 함
Reflector의 도입
- 새로운 쿼리에 대해 추론 궤적(과정)을 만드는 Generator, 교훈을 추출하기 위해 이러한 추론 과정을 비판하는 Reflector, 추출한 교훈들을 압축적인 delta로 합성하는 Curator로 구성
- 여기서 delta란, 변경분 혹은 차이를 나타내는 의미로 추가적으로 생성되는 작은 단위의 문맥 정보로 해석할 수 있음
- 평가와 인사이트(통찰) 추출을 담당하는 Reflector와 큐레이션을 분리하는 것이 핵심이며, 이를 통해 문맥의 품질과 전체적인 성능을 향상시킬 수 있었다고 함
- 여러 개의 delta를 병렬적으로 합칠 수 있음 (=배치 단위 adaptation 가능)
delta updates
- 비용이 많이 드는 전체 내용 재작성(monolithic rewrite) 대신 일부 수정을 진행
- 점진적으로 작은 단위의 변경분(delta; 차이)을 업데이트
- delta = structured, itemized bullet
- LLM의 memory entry의 개념과 유사하나 여기에 메타데이터와 내용(e.g. 재사용 가능한 전략, 도메인 개념, 일반적인 실패 모드 등)을 포함
- 새로운 문제를 해결할 때, Generator가 어떤 bullet이 유용한지 혹은 잘못되었는지를 강조, Reflector에게 업데이트를 위한 피드백을 제공함
- localization(국지성), fine-grained retrieval(섬세한 검색), incremental adaptation(점진적 적용)이라는 세 가지 중요한 특성을 가짐
grow-and-refine 메커니즘
- 문맥이 압축적이면서도 연관있게 유지될 수 있도록 주기적인 혹은 느린 정제(refinement)를 거침
- grow-and-refine에서, 새로운 식별자를 가진 bullet이 추가되고 기존의 bullet은 국지적으로 업데이트됨
- 그 이후 semantic embedding을 활용해 bullet을 비교하면서 불필요한 반복을 제거(de-duplication)
평가
- Agent 벤치마크, 도메인 특화 벤치마크에 대해 평가
AppWorld
- API 이해, 코드 생성, 환경 상호작용 등을 포함한 agent 태스크를 평가
- Task Goal Completion, Scenario Goal Completion을 측정 (평가지표)
- ReAct + ACE가 베이스라인 대비 평균적으로 10.6% 좋은 성능을 보임
FiNER, Formula
- 금융 추론 태스크에 대해 LLM을 평가
- 정확도(accuracy)를 측정 (평가지표)
- 정답(Ground Truth)이 주어졌을 경우 베이스라인 대비 평균적으로 약 8.6%의 성능 향상을 보임

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab