- 모델을 공개하는 Technical Report에도 데이터에 대한 정보는 쉽게 공개하지 않는데, HuggingFace에서 SmolLM3을 공개하면서 학습, 데이터 등 제반사항을 대부분 공개
- 상세 config는 블로그 포스트 내 연결 링크에서 확인 가능
요약
- 11T 토큰으로 학습된 3B 모델로, 3B 기준 SoTA 및 4B 모델과 비교 시에도 경쟁력 있음
- Reasoning을 on, off할 수 있는 hybrid형 Instruct 모델 제공
- 6개 언어 지원 (영어, 프랑스어, 스페인어, 독일어, 이탈리아어, 포르투갈어)
- 최대 128k 지원 (YaRN 사용 시 긴 문맥 지원)

사전학습 (Pre-training)
아키텍처 및 학습 상세
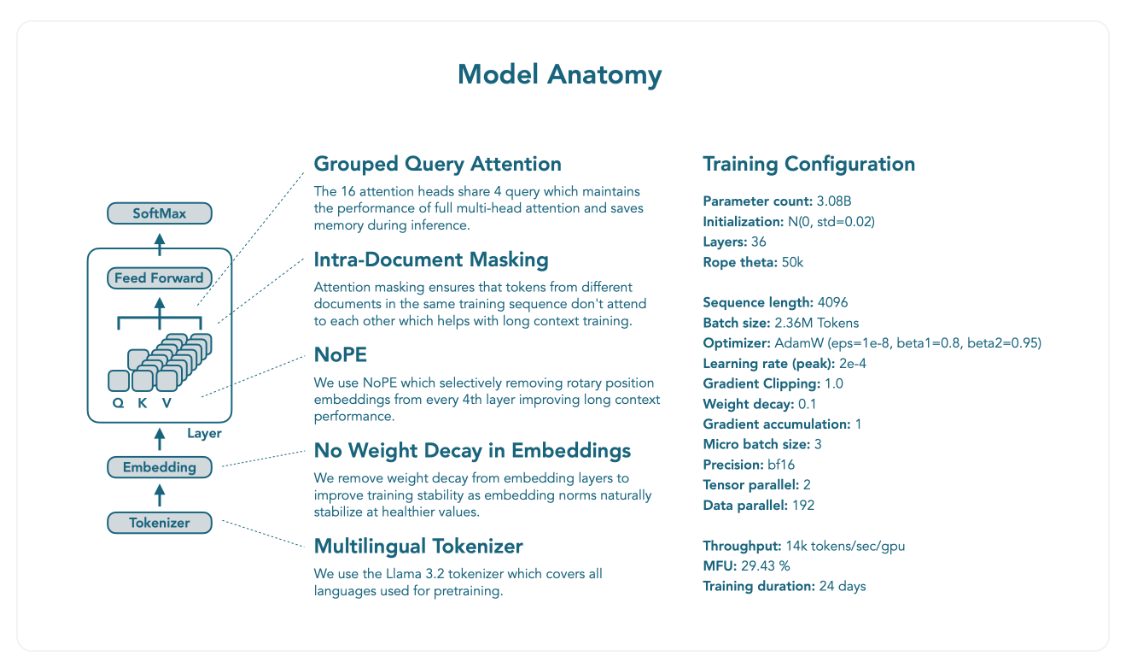
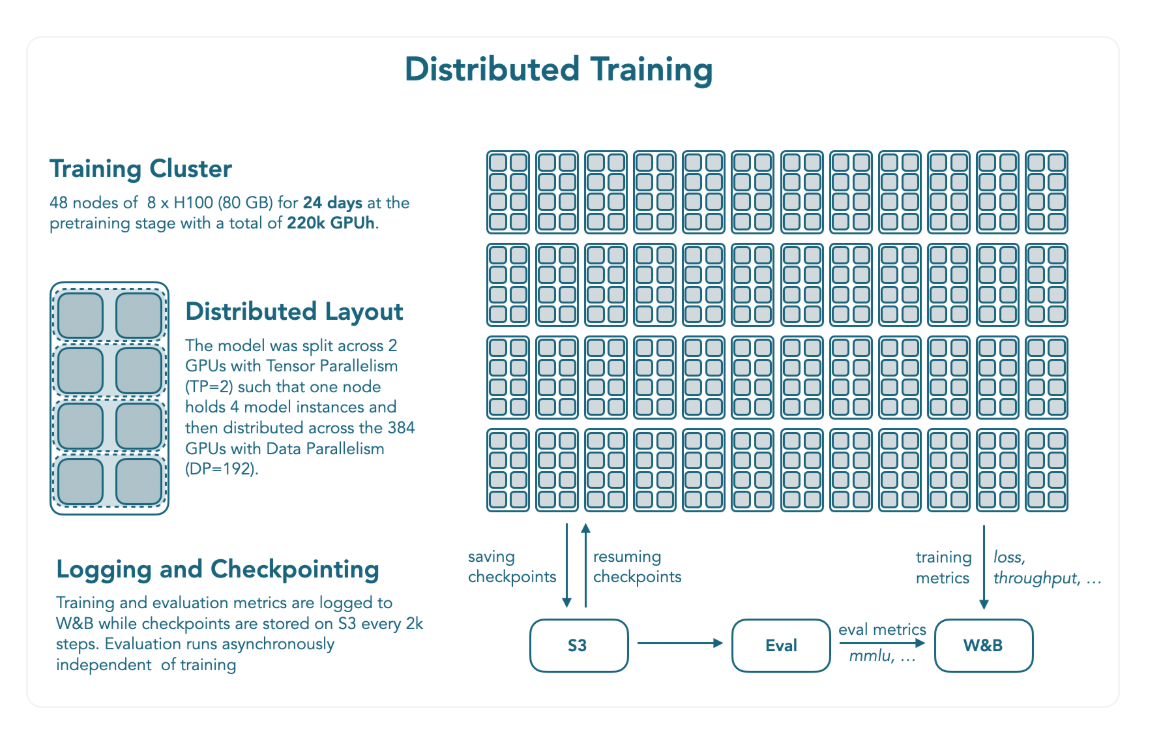
- 기본적으로 Llama 아키텍처에 수정을 더함
- Grouped Query Attention (GQA)
- Muti-head attention 대신 GQA 사용
- 추론 시 KV 캐시 크기를 현저히 줄이면서도 비슷한 성능을 낼 수 있음
- NoPE
- 매 4번째 레이어마다 RoPE를 선택적으로 제거
- 짧은 문맥에 대한 성능을 유지하면서도 긴 문맥에 대한 모델의 성능 향상 가능
- Intra-Document Masking
- 다른 문서들이 하나의 학습 시퀀스에 있을 경우, attention masking을 수행해 서로 영향을 주지 않도록 함
- 짧은 문맥에 대한 성능을 유지하면서도 긴 문맥에 대한 모델의 성능 향상 가능
- 학습 안정성
- 임베딩 레이어에서 weight decay 제거
데이터 구성 및 학습 단계
- 웹, 수학, 코드 데이터 등을 섞어 총 11.2T 토큰 활용
- 총 3단계의 사전학습 단계 구성
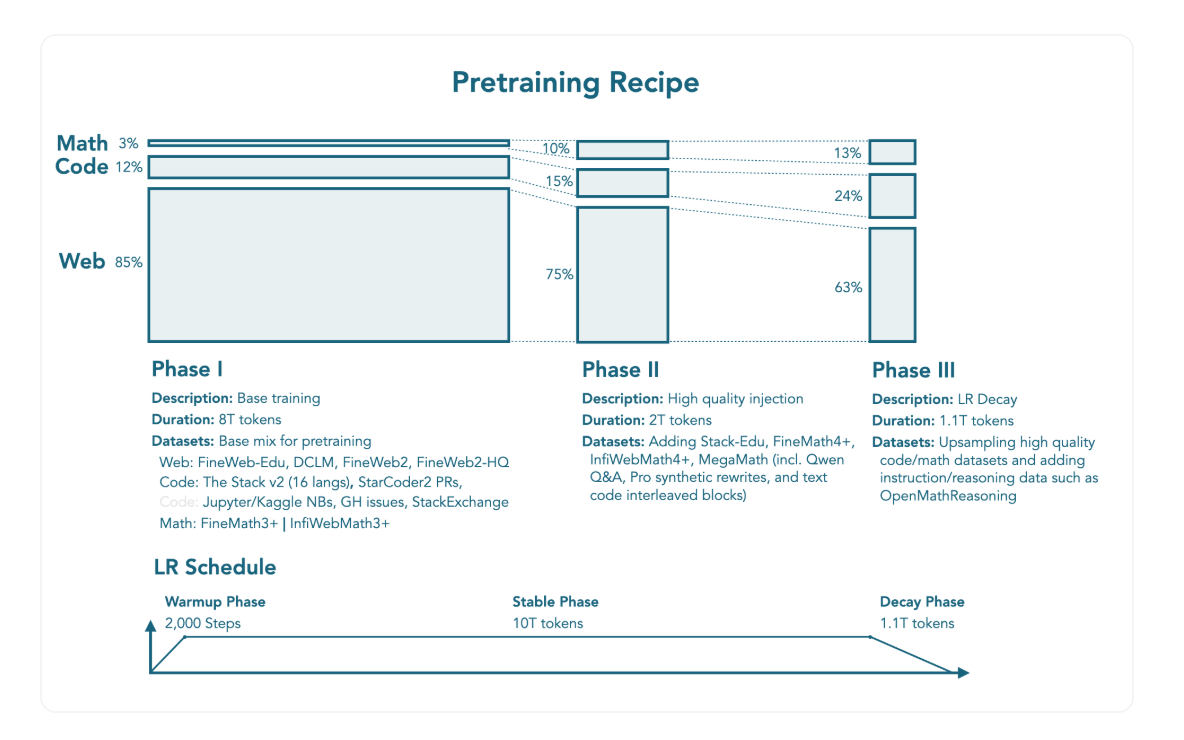
1단계: Stable Phase (0T -> 8T 토큰)
- 일반 성능을 구축하기 위한 단계
- 웹 85% (다국어 12%)
- FineWeb-Edu, DCLM, FineWeb2, FineWeb2-HQ
- 코드 12%
- The Stack v2, StarCoder2 pull requests, Jupyter and Kaggle notebooks, GitHub issues, StackExchange
- 수학 3%
- FineMath3+, InfiWebMath3
2단계: Stable Phase (8T -> 10T)
- 고품질의 수학, 코드 데이터셋 추가
- 웹 75% (다국어 12%)
- 코드 15%
- Stack-Edu 추가
- 수학 10%
- FineMath4+, InfiWebMath4+, MegaMath 활용
3단계: Decay Phase (10T -> 11.1T)
- 수학, 코드 데이터를 업샘플링한 마지막 단계
- 업샘플링이란, 전체 데이터셋 구성에서 해당 데이터셋의 비율을 높이는 과정을 의미
- 웹 63% (다국어 12%)
- 코드 24%
- 고품질 코드 데이터를 업샘플링
- 수학 13%
- OpenMathReasoning과 같은 reasoning 및 instruction 데이터셋 추가, 업샘플링
중간학습
- 긴 문맥 및 추론(Reasoning) 성능을 학습하기 위한 단계
긴 문맥 학습
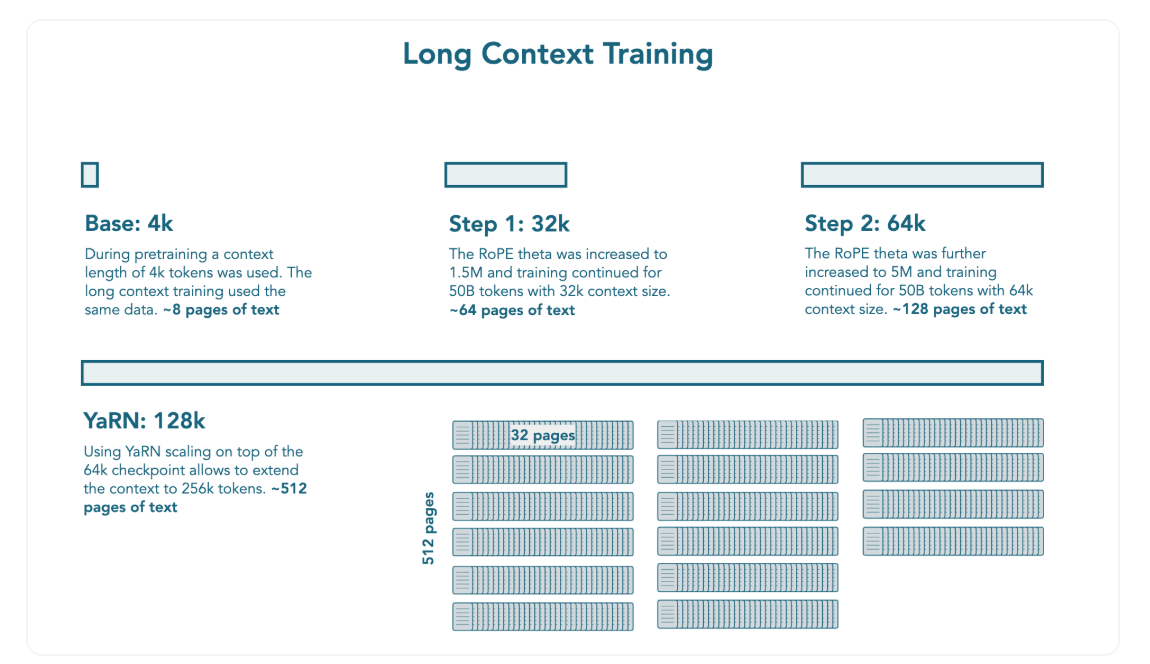
- 사전학습 이후, 추가적으로 100B 토큰에 대해 학습
- 두 단계에 걸쳐 진행 (각각 50B 토큰씩)
- RoPE theta를 1.5M까지 늘려 4k에서 32k까지 문맥 늘림
- RoPE theta를 5M까지 늘려 32k에서 64k까지 문맥 늘림
- NoPE를 사용하고, RoPE theta 값을 늘려 더 긴 시퀀스로 학습하는 것이 긴 문맥 학습에 핵심이었음
- YARN을 활용하여 추론 시 학습한 context length의 2배 (=128k) 처리 가능
추론(Reasoning) 학습
- 일반적인 추론(Reasoning) 성능의 향상을 꾀함
- OpenThoughts3-1.2M, Llama-Nemotron-Post-Training-Dataset-v1.1 활용 (35B 토큰)
- ChatML chat template 활용
- 메모리 감소가 가능한 packing 활용
- 4 epoch 학습 (~140B 토큰) 후 해당 체크포인트를 Supervised Fine-tuning 시 사용
사후학습 (Post-training)
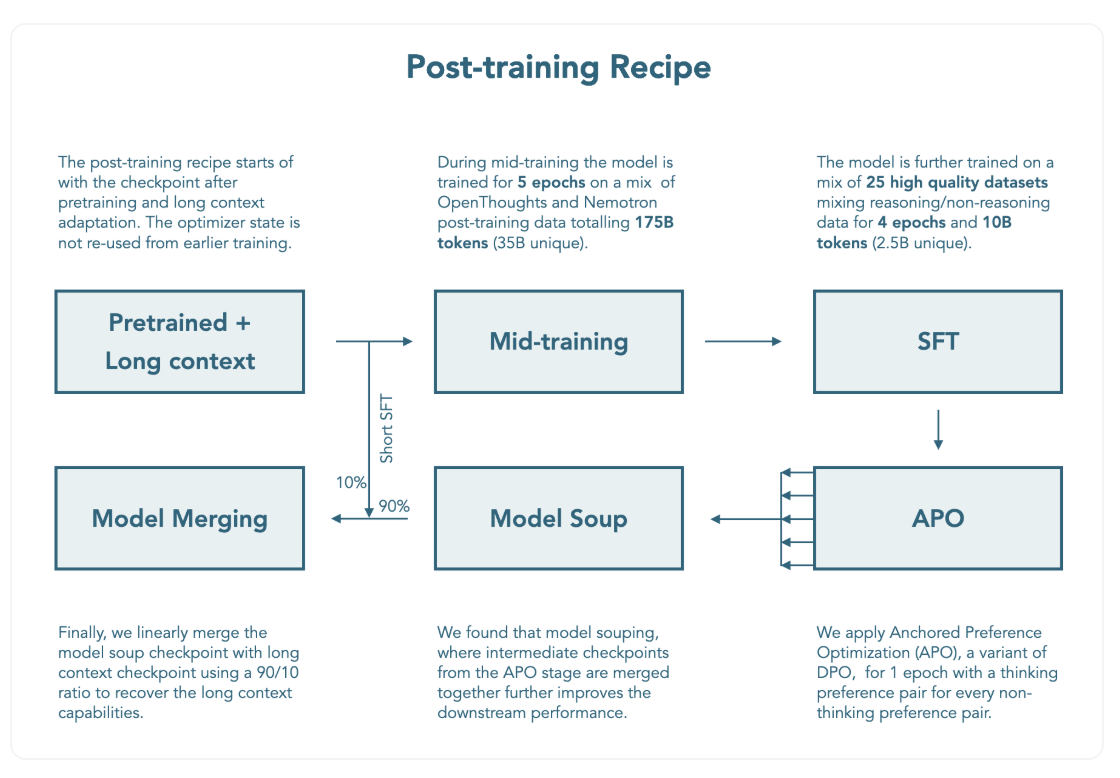
- 하나의 모델로 reasoning on/off가 가능한 hybrid 모델 학습을 위한 단계
- hybrid 사용을 위해 일반 추론 성능을 위한 중간학습, 합성 데이터셋 생성 및 Supervised Fine-tuning, alignment training 등을 활용
Chat Template 만들기
- 사용자로 하여금 대화 중 reasoning mode 사용을 결정할 수 있도록 챗 템플릿 구성
/think혹은/no_think플래그를 시스템 프롬프트에 추가함으로써 사용 가능
- Tool Calling 지원을 위해, XML 도구와 Python 도구에 대한 설명을 포함
Supervised Fine-tuning
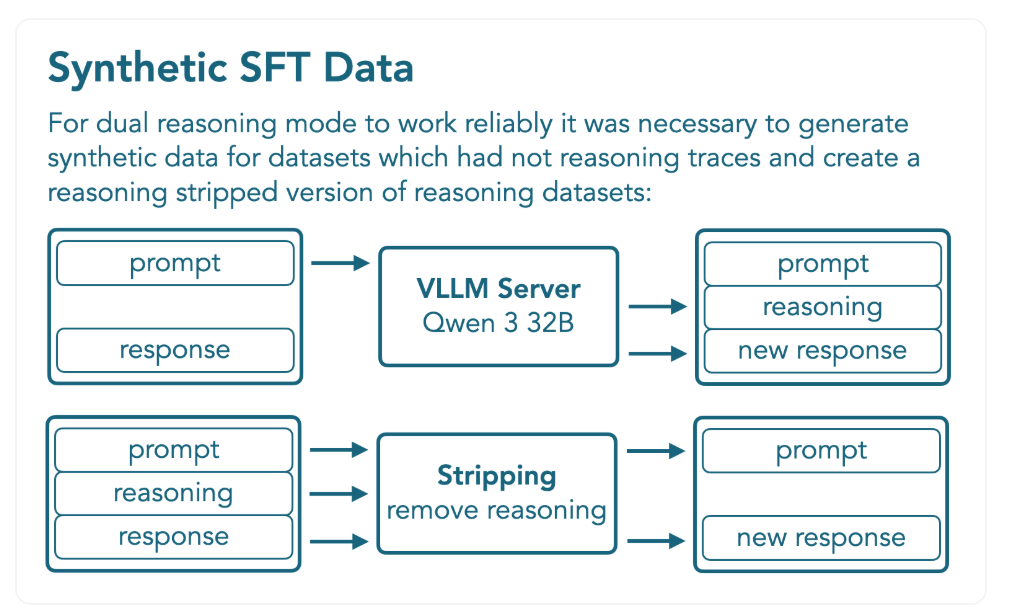
- 수학, 코드, 일반 Reasoning, 지시사항 수행, 다국어, Tool Calling 등 reasoning, non-reasoning 모드 성능을 모두 학습하기 위한 과정
- Qwen3-32B 프롬프팅을 통해 Reasoning trace를 가진 합성 데이터셋을 생성
- reasoning mode on/off를 모두 잘 지원하기 위해서는 데이터 구성의 균형을 맞추는 것이 중요
- 1B non-reasoning, 0.8B reasoning인 총 1.8B 토큰 데이터셋 활용
- BFD (best-fit decreasing) packing을 활용해 4 epoch 학습
APO (Anchored Preference Optimization)
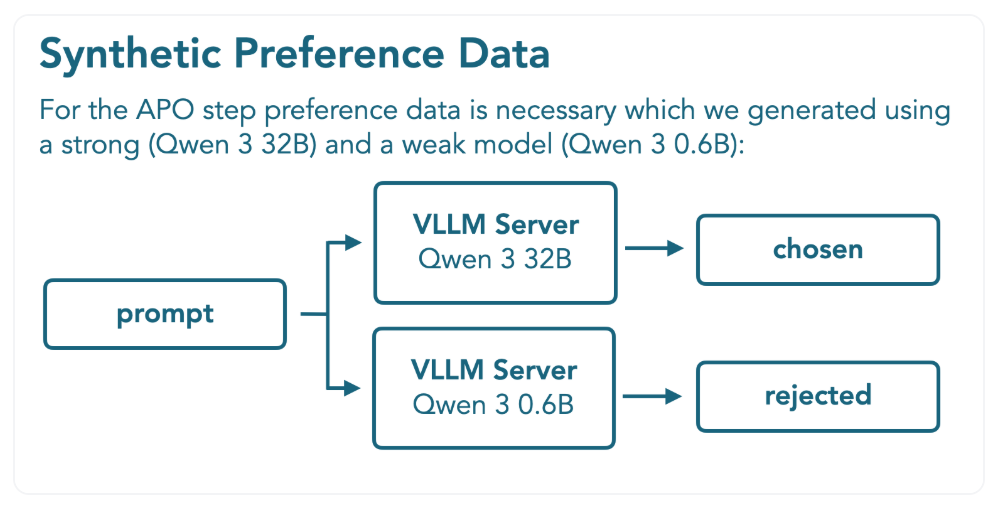
- Off-policy model alignment 방법론인 APO 활용
- DPO의 변형으로, 더 안정적인 최적화 함수를 제공
- Tulu3 preference dataset (non-reasoning) 및 reasoning을 위해 생성한 합성 데이터셋 활용
- Qwen3-32B로 생성한 답변은 chosen, Qwen3-0.6B로 생성한 답은 rejected로 활용
- 수학, 과학, 지시사항 수행, 코드, 대화, 다국어 성능 등은 향상되었으나 긴 문맥에 대한 성능은 하락
- 이를 해결하기 위해 모델 머징을 고려
모델 머징
- mergekit 라이브러리를 활용해 모델 머징 수행
- APO 체크포인트 각각을 취해 모델 "soup" 구성
- 모델 soup를 긴 문맥 성능이 높은 중간학습의 체크포인트와 결합
- 9:1 (APO : 중간학습) linear merging이 가장 좋은 성능을 보임
평가
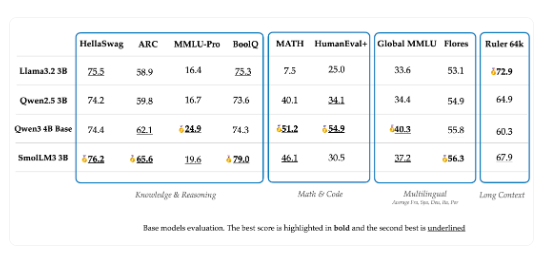
Base 모델 평가
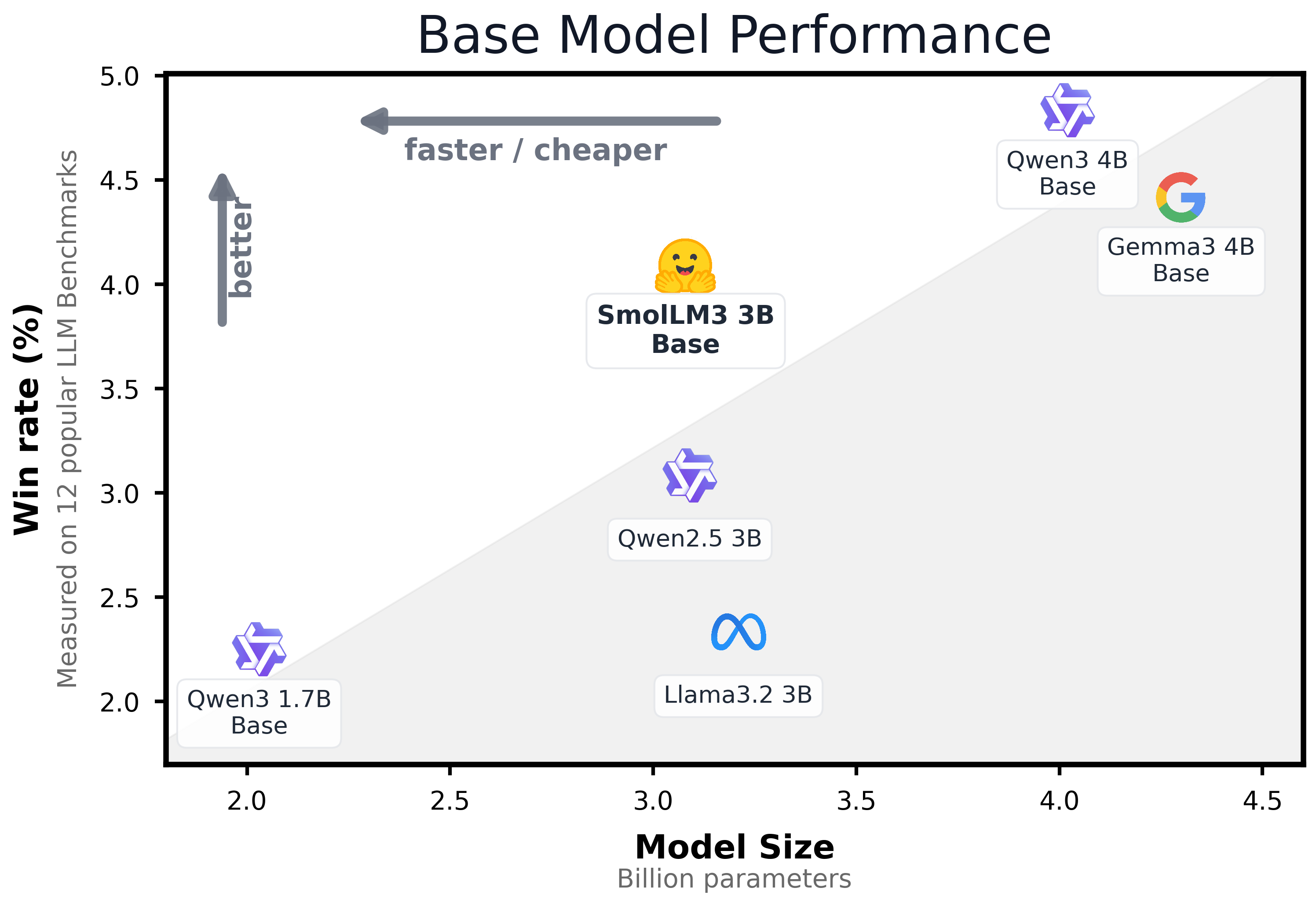
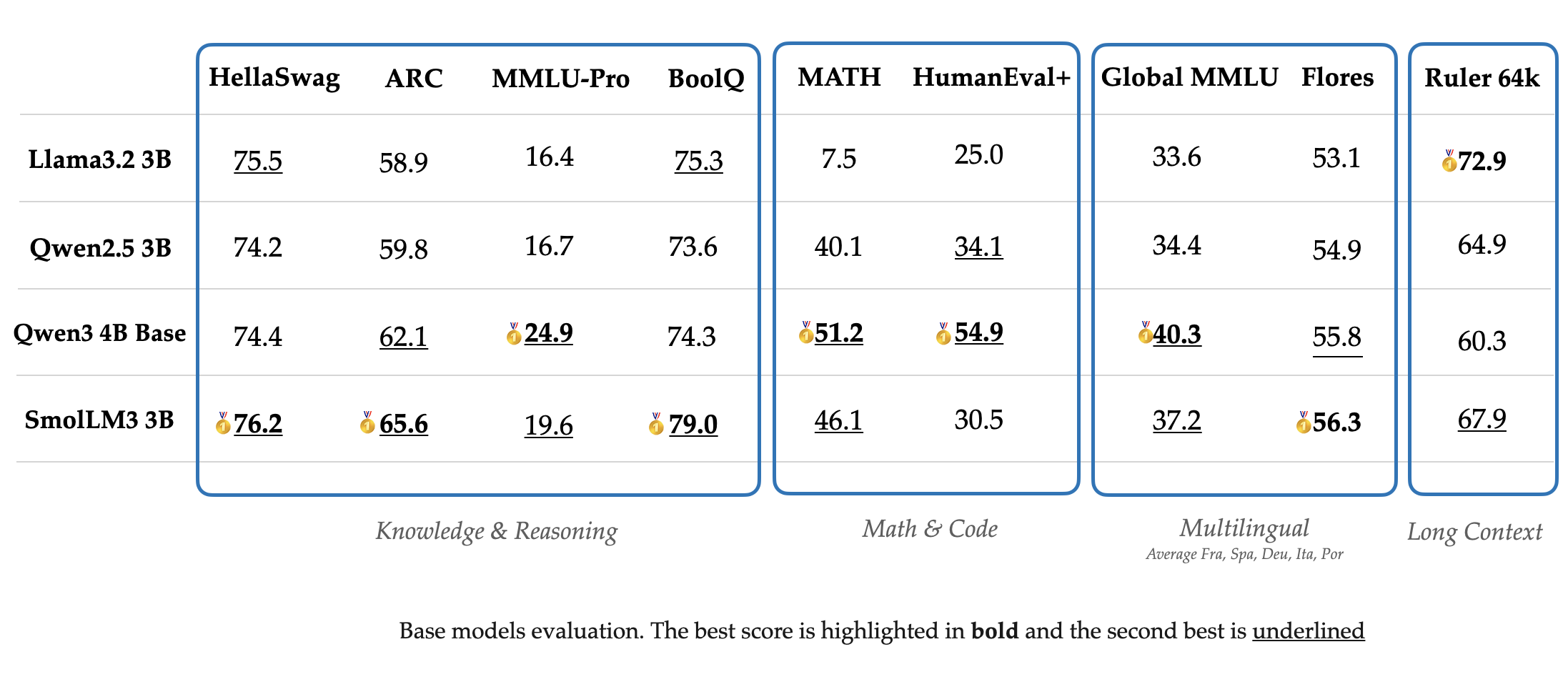
- 지식, 추론(Reasoning), 수학, 코드 등 12개 벤치마크 평가에서 3B 모델들보다 좋은 성능, 4B 모델들과 필적할 만한 성능 보임
- HellaSwag, ARC, Winogrande, CommonsenseQA, MMLU-CF, MMLU Pro CF, PIQA, OpenBookQA, GSM8K, MATH, HumanEval+, MBPP+
- 5개 주요 유럽 언어에 대해서도 높은 다국어 성능
- Global MMLU, MLMM HellaSwag, Flores-200, Belebele, testing knowledge, commonsense reasoning, text understanding, translation
Instruct / Reasoning 모델 평가
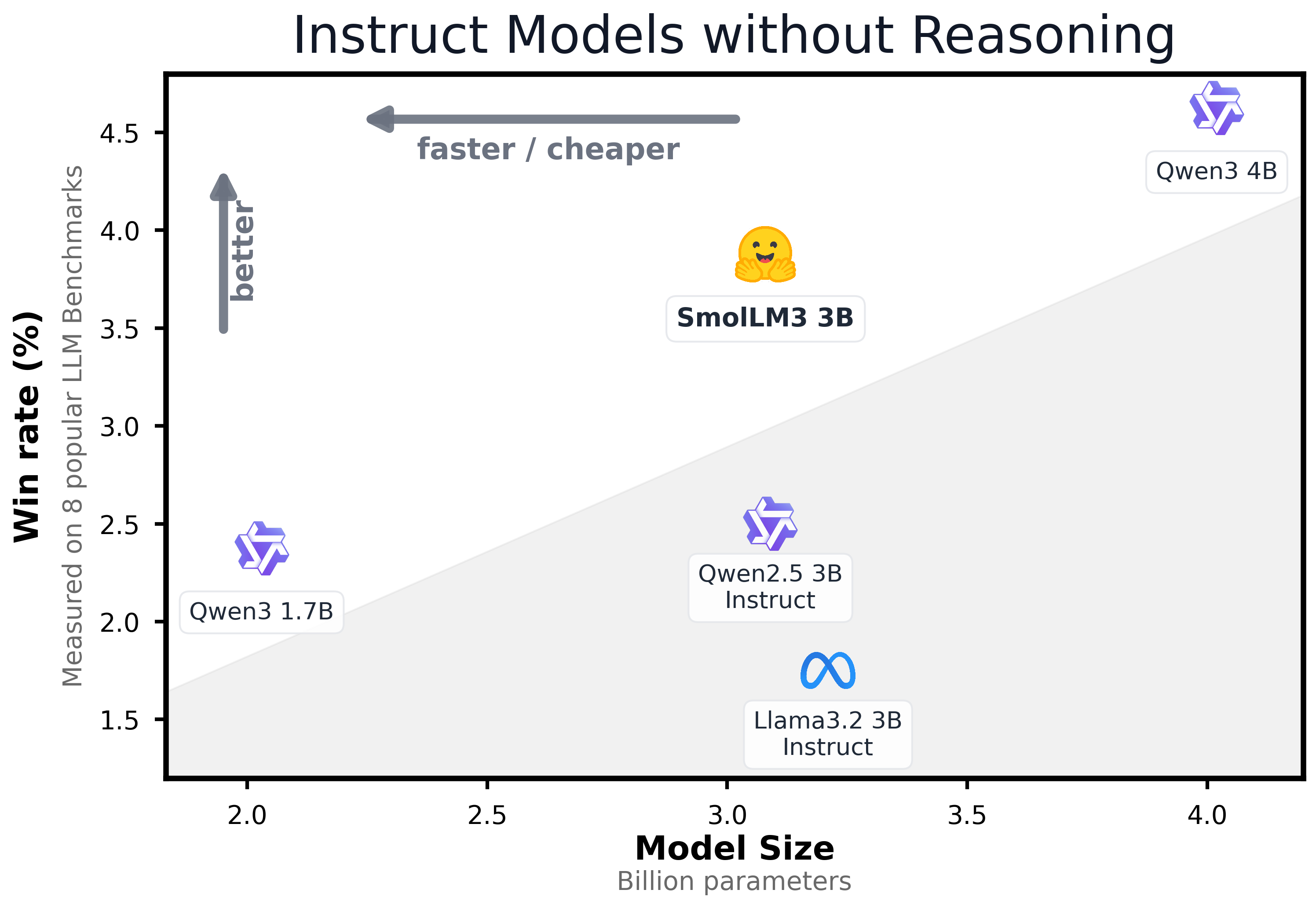
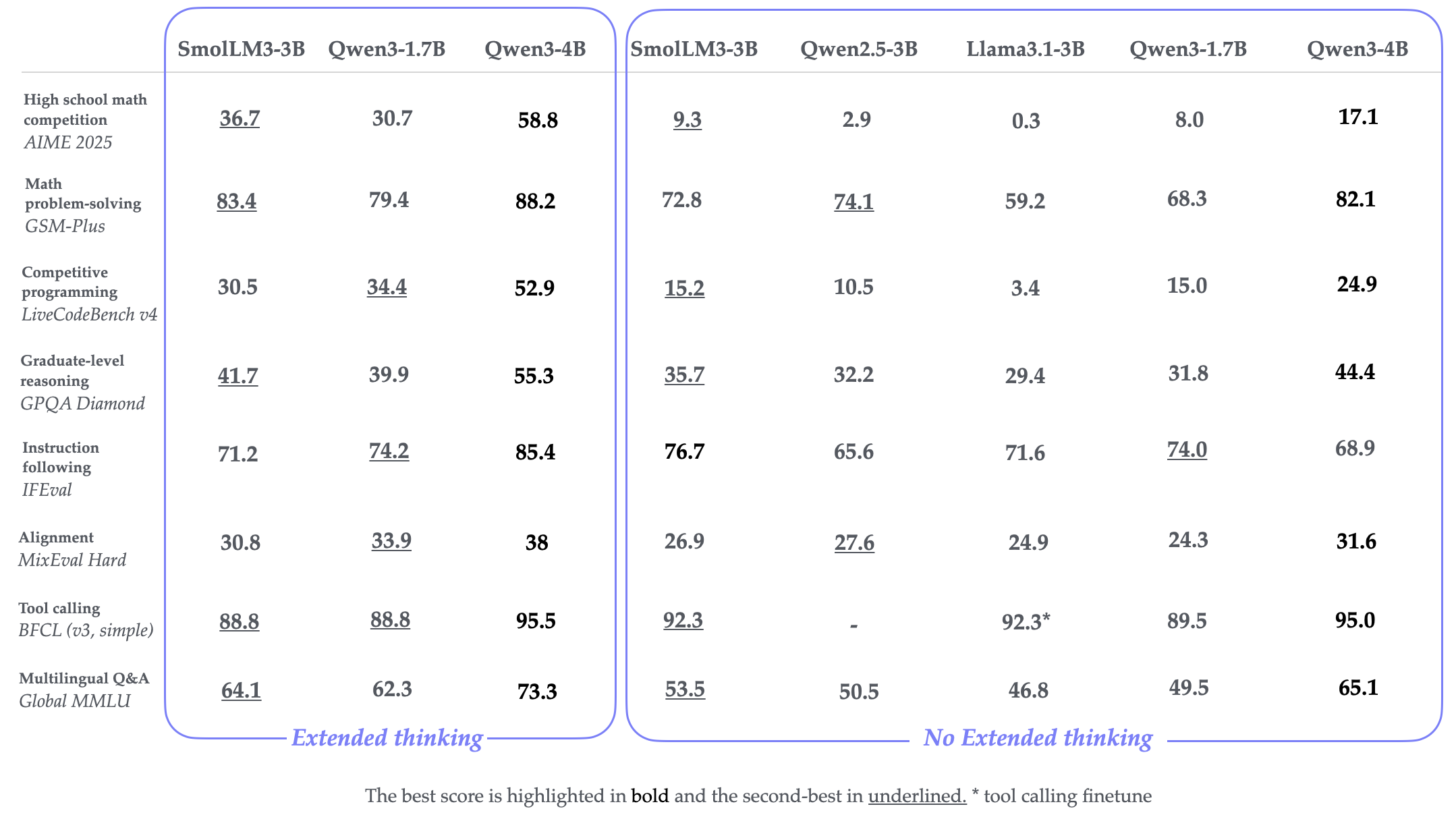
- Instruct 모드 사용 시, 다른 3B 모델보다 좋은 성능을 보임
- Reasoning 모드 사용 시, 대부분의 벤치마크에서 성능 향상을 보임
- AIME2025의 경우 9.3 -> 36.7
- LiveCodeBench의 경우 15.2 -> 30.0
- GPQA Diamond의 경우 35.7 -> 41.7
참고.

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab